第四章 微服务架构
微服务架构模式作为替代单体应用和面向服务架构的一个可行的选择,在业内迅速取得进展。由于这个架构模式仍然在不断的发展中,在业界存在很多困惑——这种模式是关于什么的?它是如何实现的?本报告的这部分将为你提供关键概念和必要的基础知识来理解这一重要架构模式的好处(和取舍),以此来判断这种架构是否适合你的应用。
模式描述
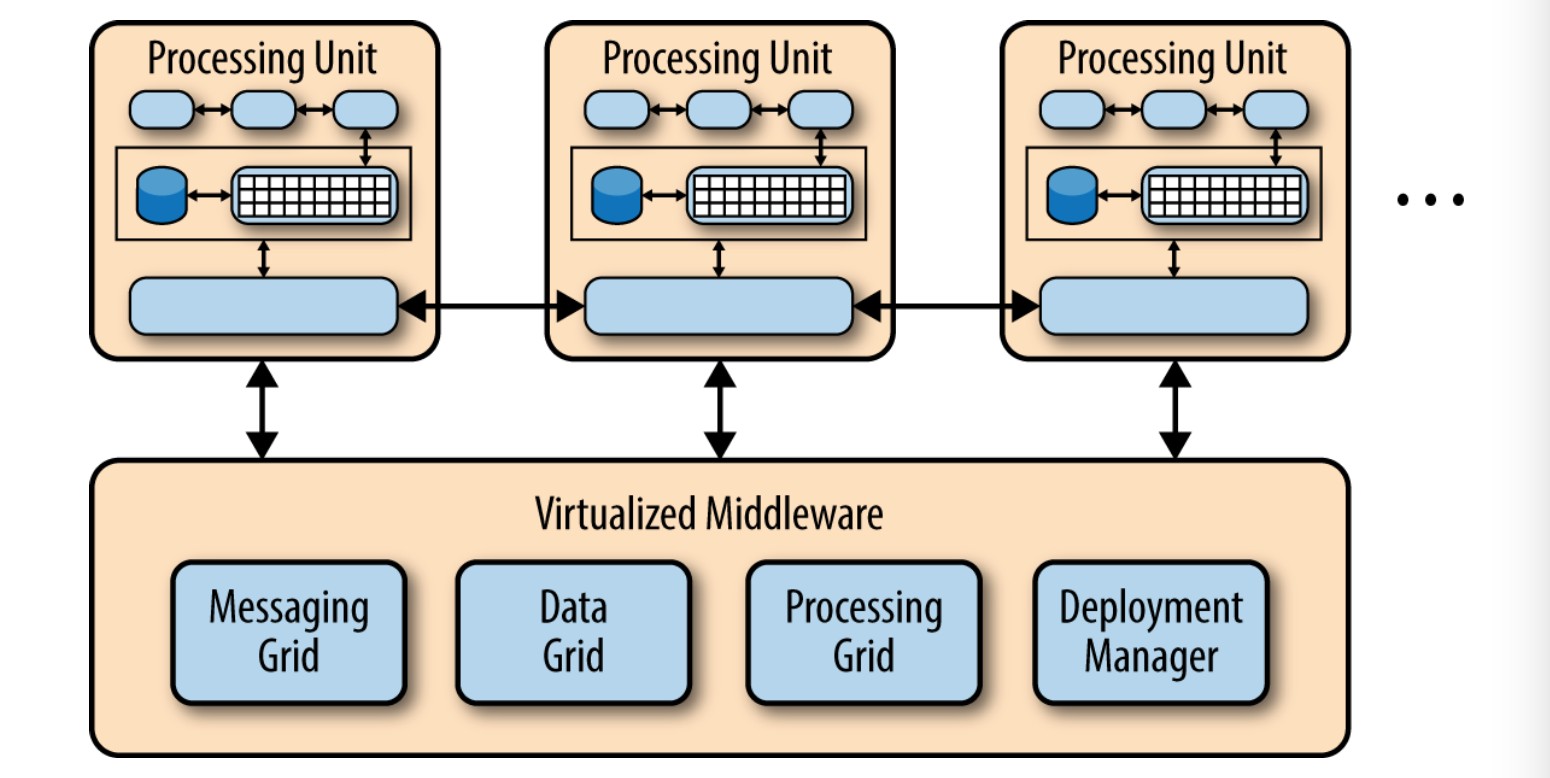
不管你选择哪种拓扑或实现风格,有几种常见的核心概念适用于一般架构模式。第一个概念是单独部署单元。如图4-1所示,微服务架构的每个组件都作为一个独立单元进行部署,让每个单元可以通过有效、简化的传输管道进行通信,同时它还有很强的扩展性,应用和组件之间高度解耦,使得部署更为简单。
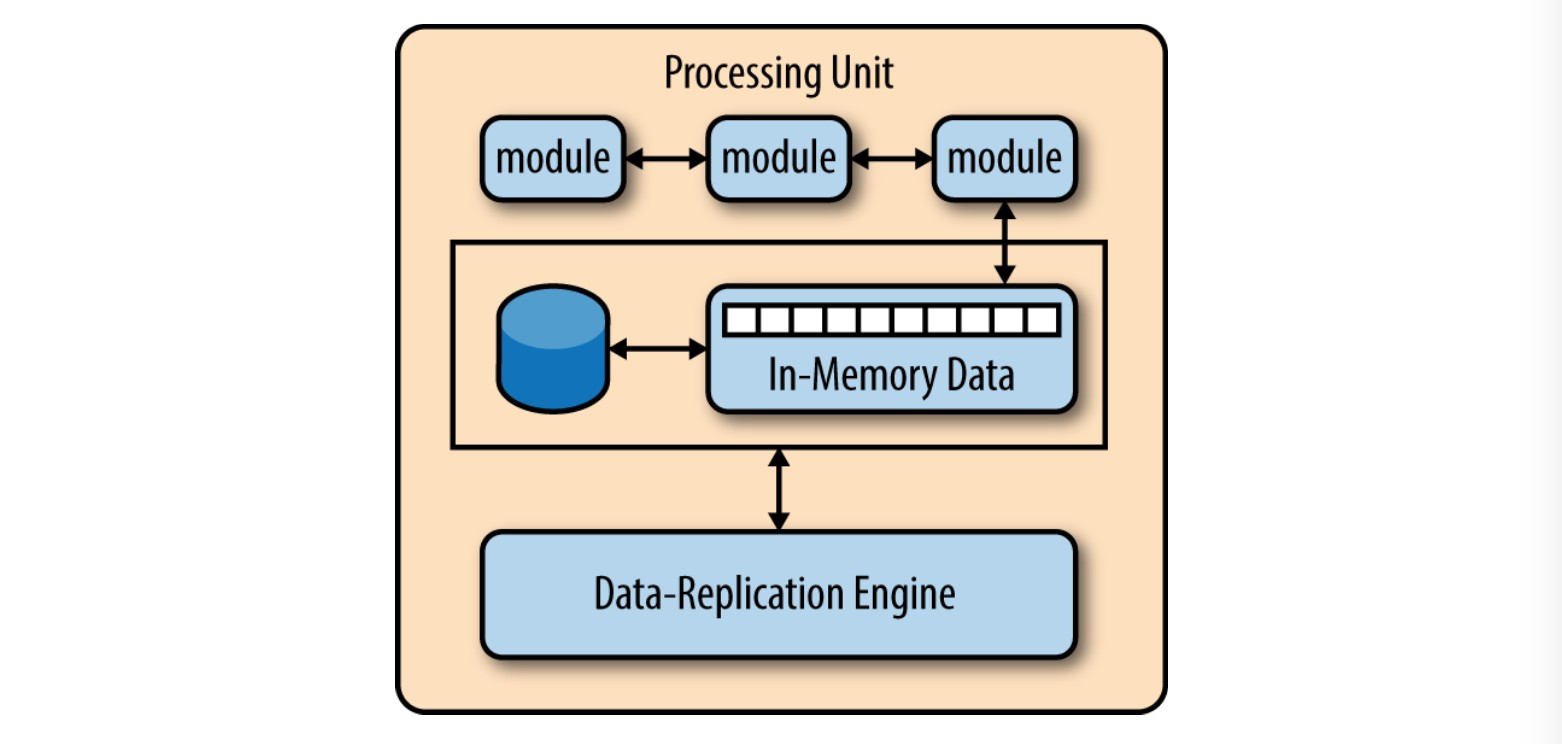
也许要理解这种模式,最重要的概念就是服务组件(service component)。不要考虑微服务架构内部的服务,而最好是考虑服务组件,从粒度上讲它可以小到单一的模块,或者大至一个应用程序。服务组件包含一个或多个模块(如Java类),这些模块可以提供一个单一功能(如,为特定的城市或城镇提供天气情况),或也可以作为一个大型商业应用的一个独立部分(如,股票交易布局或测定汽车保险的费率)。在微服务架构中,正确设计服务组件的粒度是一个很大的挑战。在接下来的服务组件部分对这一挑战进行了详细的讨论。
微服务架构模式的另一个关键概念是它是一个分布式的架构,这意味着架构内部的所有组件之间是完全解耦的,并通过某种远程访问协议(如, JMS, AMQP, REST, SOAP, RMI等)进行访问。这种架构的分布式特性是它实现一些优越的可扩展性和部署特性的关键所在。
微服务架构另一个令人兴奋的特性是它是由其他常见架构模式存在的问题演化来的,而不是作为一个解决方案被创造出来等待问题出现。微服务架构的演化有两个主要来源:使用分层架构模式的单体应用和使用面向服务架构的分布式应用。
由单体应用( 一个应用就是一个整体 )到微服务的发展过程主要是由持续交付开发促成的。从开发到生产的持续部署管道概念,简化了应用程序的部署。单体应用通常是由紧耦合的组件组成,这些组件同时又是另一个单一可部署单元的一部分,这使得它繁琐,难以改变、测试和部署应用(因此常见的“月度部署”周期出现并通常发生在大型IT商店项目)。这些因素通常会导致应用变得脆弱以至于每次有一点新功能部署后应用就不能运行。微服务架构模式通过将应用分隔成多个可部署的单元(服务组件)的方法来解决这一问题,这些服务组件可以独立于其他服务组件进行单独开发、测试和部署。
另一个导致微服务架构模式产生的演化过程是由面向服务架构模式(SOA)应用程序存在的问题引起的。虽然SOA模式非常强大,提供了无与伦比的抽象级别、异构连接、服务编排,并保证通过IT能力调整业务目标,但它仍然是复杂的,昂贵的,普遍存在,它很难理解和实现,对大多数应用程序来说过犹不及。微服务架构通过简化服务概念,消除编排需求、简化服务组件连接和访问来解决复杂度问题。
模式拓扑
虽然有很多方法来实现微服务架构模式,但三个主要的拓扑结构脱颖而出,最常见和流行的有:基于REST API的拓扑结构,基于REST的应用拓扑结构和集中式消息拓扑结构。
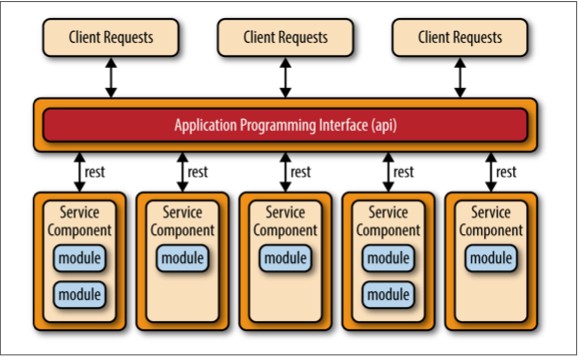
基于REST的API拓扑适用于网站,通过某些API对外提供小型的、自包含的服务。这种拓扑结构,如图4 – 2所示,由粒度非常细的服务组件(因此得名微服务)组成,这些服务组件包含一个或两个模块并独立于其他服务来执行特定业务功能。在这种拓结构扑中,这些细粒度的服务组件通常被REST-based的接口访问,而这个接口是通过一个单独部署的web API层实现的。此种拓扑的例子包含一些常见的专用的、基于云的RESTful web service,大型网站像Yahoo, Google, and Amazon都在使用。
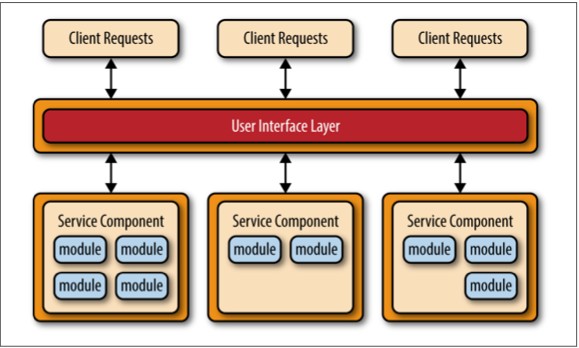
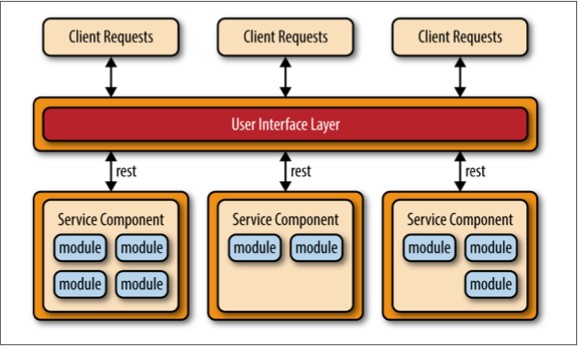
基于REST的应用拓扑结构与基于REST API的不同,它通过传统的基于web的或胖客户端业务应用来接收客户端请求,而不是通过一个简单的API层。如图4-3所示,应用的用户接口层(user interface layer)是一个web应用,可以通过简单的REST-based接口访问单独部署的服务组件(业务功能)。该拓扑结构中的服务组件与API-REST-based拓扑结构中的不同,这些服务组件往往会更大、粒度更粗、代表整个业务应用程序的一小部分,而不是细粒度的、单一操作的服务。这种拓扑结构常见于中小型企业等复程度相对较低的应用程序。
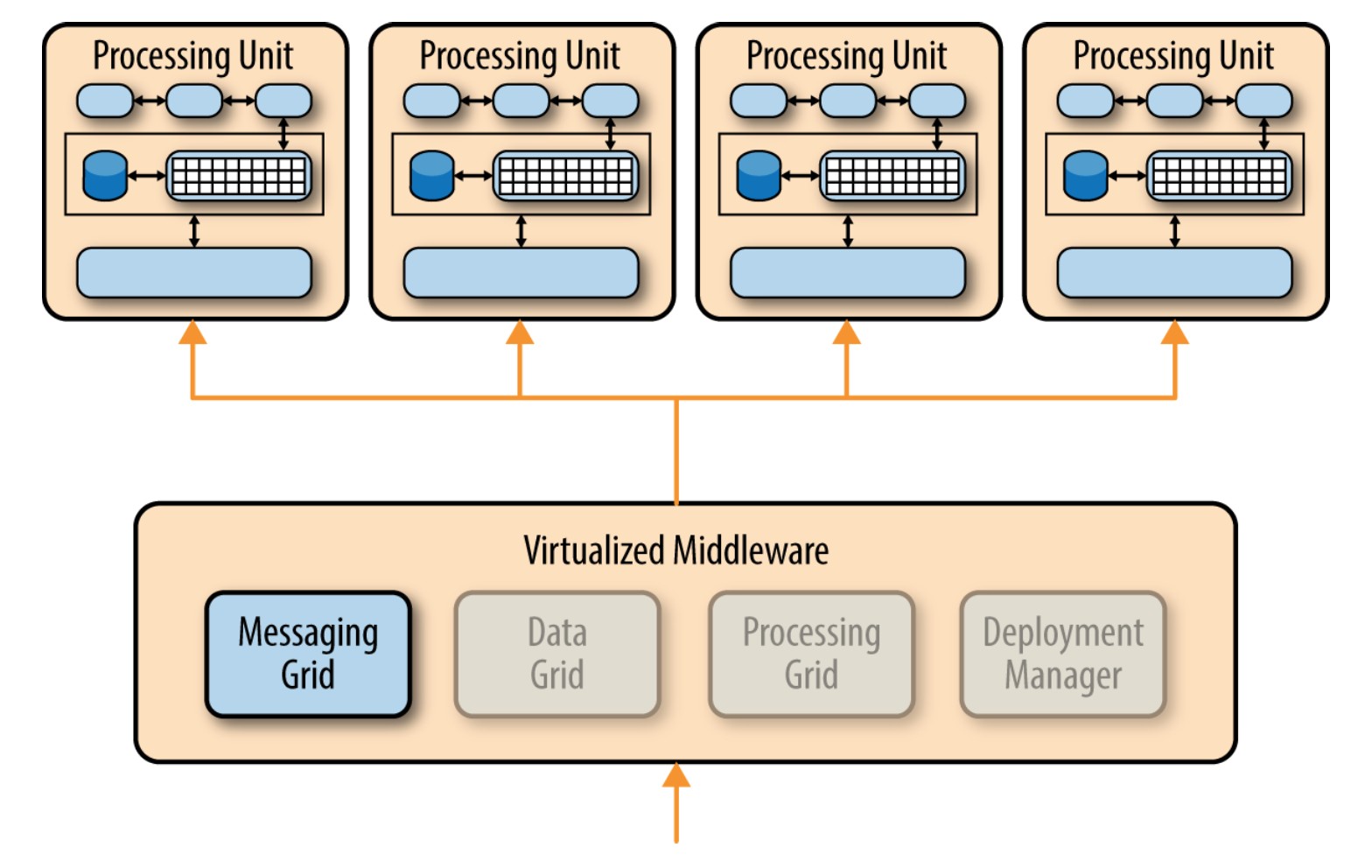
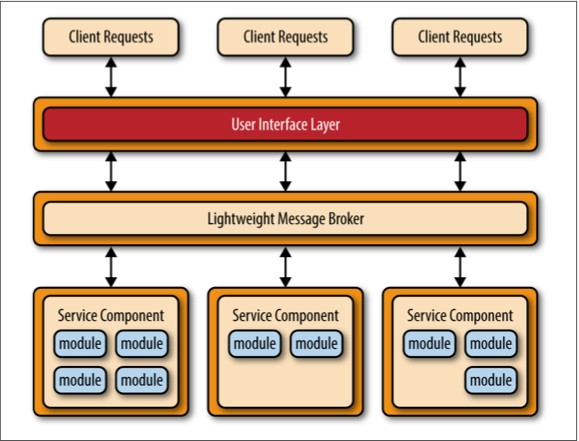
微服务架构模式中另一个常见的方法是集中式消息拓扑。该拓扑(如图4-4所示)与前面提到的基于REST的应用拓扑类似,不同的是,application REST- based拓扑结构使用REST进行远程访问,而该拓扑结构则使用一个轻量级的集中式消息代理(如,ActiveMQ, HornetQ等等)。不要将该拓扑与面向服务架构模式混淆或将其当做SOA简化版(“SOA-Lite”),这点是极其重要的。该拓扑中的轻量级消息代理(Lightweight Message Broker)不执行任何编排,转换,或复杂的路由;相反,它只是一个轻量级访问远程服务组件的传输工具。
集中式消息拓扑结构通常应用在较大的业务应用程序中,或对于某些对传输层到用户接口层或者到服务组件层有较复杂的控制逻辑的应用程序中。该拓扑较之先前讨论的简单基于REST的拓扑结构,其好处是有先进的排队机制、异步消息传递、监控、错误处理和更好的负载均衡和可扩展性。与集中式代理相关的单点故障和架构瓶颈问题已通过代理集群和代理联盟(将一个代理实例为分多个代理实例,把基于系统功能区域的吞吐量负载划分开处理)解决。
避免依赖和编排
微服务架构模式的主要挑战之一就是决定服务组件的粒度级别。如果服务组件粒度过粗,那你可能不会意识到这个架构模式带来的好处(部署、可扩展性、可测试性和松耦合),然而,服务组件粒度过细将导致服务编制要求,这会很快导致将微服务架构模式变成一个复杂、容易混淆、代价昂贵并易于出错的重量级面向服务架构。
如果你发现需要从应用内部的用户接口或API层编排服务组件,那么很有可能你服务组件的粒度太细了。如果你发现你需要在服务组件之间执行服务间通信来处理单个请求,那么很有可能要么是你服务组件的粒度太细了,要么是没有从业务功能角度正确划分服务组件。
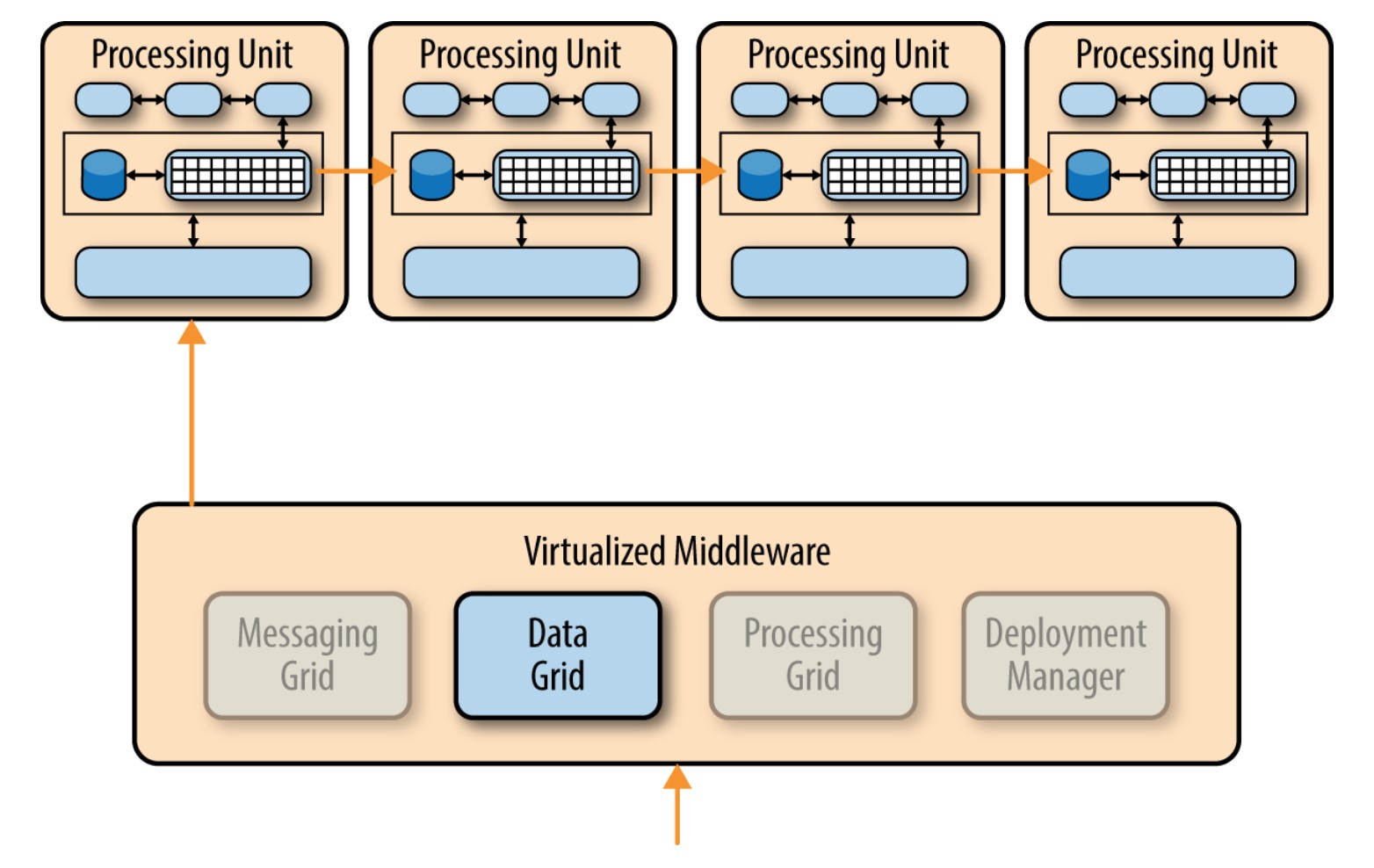
服务间通信,可能导致组件之间产生耦合,但可以通过共享数据库进行处理。例如,若一个服务组件处理网络订单而需要用户信息时,它可以去数据库检索必要的数据,而不是调用客户服务组件的功能。
共享数据库可以处理信息需求,但是共享功能呢?如果一个服务组件需要的功能包含在另一个服务组件内,或是一个公共的功能,那么有时你可以将服务组件的共享功能复制一份(因此违反了DRY规则:don’t repeat yourself)。为了保持服务组件独立和部署分离,微服务架构模式实现中会存在一小部分由重复的业务逻辑而造成的冗余,这在大多数业务应用程序中是一个相当常见的问题。小工具类可能属于这一类重复的代码。
如果你发现就算不考虑服务组件粒度的级别,你仍不能避免服务组件编排,这是一个好迹象,可能此架构模式不适用于你的应用。由于这种模式的分布式特性,很难维护服务组件之间的单一工作事务单元。这种做法需要某种事务补偿框架回滚事务,这对此相对简单而优雅的架构模式来说,显著增加了复杂性。
注意事项
微服务架构模式解决了很多单体应用和面向服务架构应用存在的问题。由于主要应用组件被分成更小的,单独部署单元,使用微服务架构模式构建的应用程序通常更健壮,并提供更好的可扩展性,支持持续交付也更容易。
该模式的另一个优点是,它提供了实时生产部署能力,从而大大减少了传统的月度或周末“大爆炸”生产部署的需求。因为变化通常被隔离成特定的服务组件,只有变化的服务组件才需要部署。如果你的服务组件只有一个实例,你可以在用户界面程序编写专门的代码用于检测一个活跃的热部署,一旦检测到就将用户重定向到一个错误页面或等待页面。你也可以在实时部署期间,将服务组件的多个实例进行交换,允许应用程序在部署期间保持持续可用性(分层架构模式很难做到这点)。
最后一个要重视的考虑是,由于微服务架构模式是分布式的架构,他与事件驱动架构模式具有一些共同的复杂的问题,包括约定的创建、维护,和管理,远程系统的可用性,远程访问身份验证和授权。
模式分析
下面这个表中包含了微服务架构模式的特点分析和评级,每个特性的评级是基于自然趋势,基于典型模式实现的能力特性,以及该模式是以什么闻名的。本报告中该模式与其他模式的并排比较,请参考报告最后的附件A。
整体灵活性
评级:高 分析:整体的灵活性是能够快速响应不断变化的环境。由于单独部署单元的概念,变化通常被隔离成单独的服务组件,使得部署变得快而简单。同时,使用这种模式构建的应用往往是松耦合的,也有助于促进改变。
易于部署
评级:高 分析:整体来讲,由于该模式的解耦特性和事件处理组件使得部署变得相对简单。broker拓扑往往比mediator拓扑更易于部署,主要是因为event-mediator组件与事件处理器是紧耦合的,事件处理器组件有一个变化可能导致event mediator跟着变化,有任何变化两者都需要部署。
可测试性
评级:高 分析:由于业务功能被分离成独立的应用模块,可以在局部范围内进行测试,这样测试工作就更有针对性。对一个特定的服务组件进行回归测试比对整个单体应用程序进行回归测试更简单、更可行。而且,由于这种模式的服务组件是松散耦合的,从开发角度来看,由一个变化导致应用其他部分也跟着变化的几率很小,并能减小由于一个微小的变化而不得不对整个应用程序进行测试的负担。
性能
评级:低 分析:虽然你可以从实现该模式来创建应用程序并可以很好的运行,整体来说,由于微服务架构模式的分布式特性,并不适用于高性能的应用程序。
伸缩性
评级:高 分析:由于应用程序被分为单独的部署单元,每个服务组件可以单独扩展,并允许对应用程序进行扩展调整。例如,股票交易的管理员功能区域可能不需要扩展,因为使用该功能的用户很少,但是交易布局服务组件可能需要扩展,因为大多数交易应用程序需要具备处理高吞吐量的功能。
易于开发
评级:高 分析:由于功能被分隔成不同的服务组件,由于开发范围更小且被隔离,开发变得更简单。程序员在一个服务组件做出一个变化影响其他服务组件的几率是很小的,从而减少开发人员或开发团队之间的协调。