在上一篇提高到了 web 通信的各种方式,包括 轮询、长连接 以及各种 HTML5 中提到的手段。本文将详细描述 WebSocket协议 在 web通讯 中的实现。
一、WebSocket 协议
1. 概述
websocket协议允许不受信用的客户端代码在可控的网络环境中控制远程主机。该协议包含一个握手和一个基本消息分帧、分层通过TCP。简单点说,通过握手应答之后,建立安全的信息管道,这种方式明显优于前文所说的基于 XMLHttpRequest 的 iframe 数据流和长轮询。该协议包括两个方面,握手链接(handshake)和数据传输(data transfer)。
2. 握手连接
这部分比较简单,就像路上遇到熟人问好。
Client:嘿,大哥,有火没?(烟递了过去) Server:哈,有啊,来~ (点上) Client:火柴啊,也行!(烟点上,验证完毕)
握手连接中,client 先主动伸手:
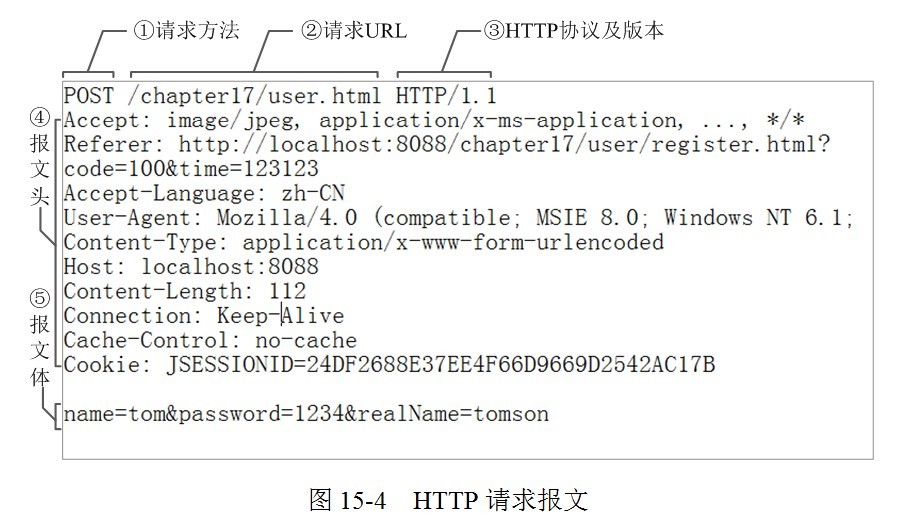
GET /chat HTTP/1.1 Host: server.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Origin: http://example.com Sec-WebSocket-Protocol: chat, superchat Sec-WebSocket-Version: 13
客户端发了一串 Base64 加密的密钥过去,也就是上面你看到的 Sec-WebSocket-Key。 Server 看到 Client 打招呼之后,悄悄地告诉 Client 他已经知道了,顺便也打个招呼。
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo= Sec-WebSocket-Protocol: chat
Server 返回了 Sec-WebSocket-Accept 这个应答,这个应答内容是通过一定的方式生成的。生成算法是:
mask = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"; // 这是算法中要用到的固定字符串 accept = base64( sha1( key + mask ) );
key 和 mask 串接之后经过 SHA-1 处理,处理后的数据再经过一次 Base64 加密。分解动作:
1. t = "GhlIHNhbXBsZSBub25jZQ==" + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
-> "GhlIHNhbXBsZSBub25jZQ==258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
2. s = sha1(t)
-> 0xb3 0x7a 0x4f 0x2c 0xc0 0x62 0x4f 0x16 0x90 0xf6
0x46 0x06 0xcf 0x38 0x59 0x45 0xb2 0xbe 0xc4 0xea
3. base64(s)
-> "s3pPLMBiTxaQ9kYGzzhZRbK+xOo="
上面 Server 端返回的 HTTP 状态码是 101,如果不是 101 ,那就说明握手一开始就失败了~
下面就来个 demo,跟服务器握个手:
var crypto = require('crypto');
require('net').createServer(function(o){
var key;
o.on('data',function(e){
if(!key){
// 握手
// 应答部分,代码先省略
console.log(e.toString());
}else{
};
});
}).listen(8000);
客户端代码:
var ws=new WebSocket("ws://127.0.0.1:8000");
ws.onerror=function(e){
console.log(e);
};
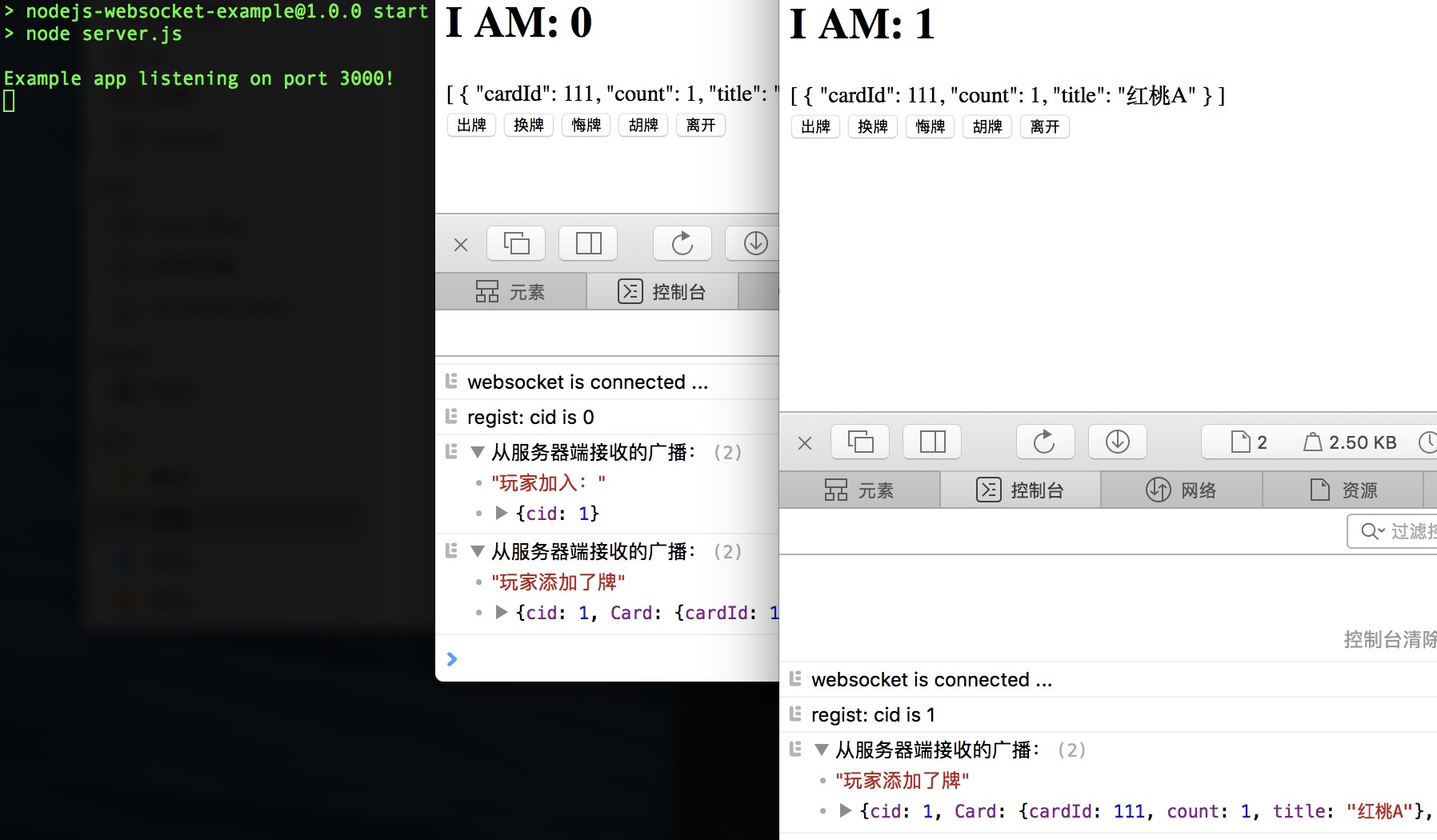
上面当然是一串不完整的代码,目的是演示握手过程中,客户端给服务端打招呼。在控制台我们可以看到:
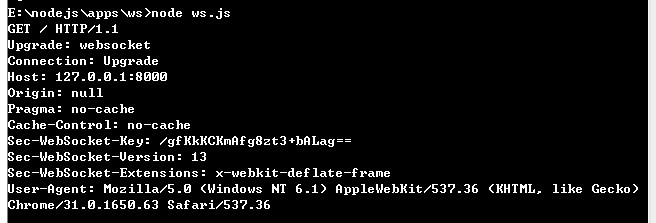
看起来很熟悉吧,其实就是发送了一个 HTTP 请求,这个我们在浏览器的 Network 中也可以看到: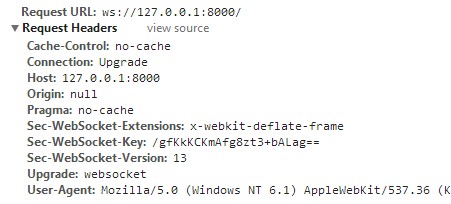
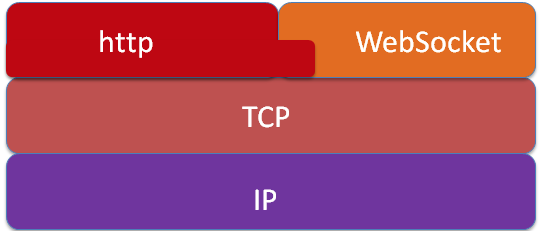
但是 WebSocket协议 并不是 HTTP 协议,刚开始验证的时候借用了 HTTP 的头,连接成功之后的通信就不是 HTTP 了,不信你用 fiddler2 抓包试试,肯定是拿不到的,后面的通信部分是基于 TCP 的连接。
服务器要成功的进行通信,必须有应答,往下看:
//服务器程序
var crypto = require('crypto');
var WS = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11';
require('net').createServer(function(o){
var key;
o.on('data',function(e){
if(!key){
//握手
key = e.toString().match(/Sec-WebSocket-Key: (.+)/)[1];
key = crypto.createHash('sha1').update(key + WS).digest('base64');
o.write('HTTP/1.1 101 Switching Protocols\r\n');
o.write('Upgrade: websocket\r\n');
o.write('Connection: Upgrade\r\n');
o.write('Sec-WebSocket-Accept: ' + key + '\r\n');
o.write('\r\n');
}else{
console.log(e);
};
});
}).listen(8000);
关于crypto模块,可以看看官方文档,上面的代码应该是很好理解的,服务器应答之后,Client 拿到 Sec-WebSocket-Accept ,然后本地做一次验证,如果验证通过了,就会触发 onopen 函数。
//客户端程序
var ws=new WebSocket("ws://127.0.0.1:8000/");
ws.onopen=function(e){
console.log("握手成功");
};
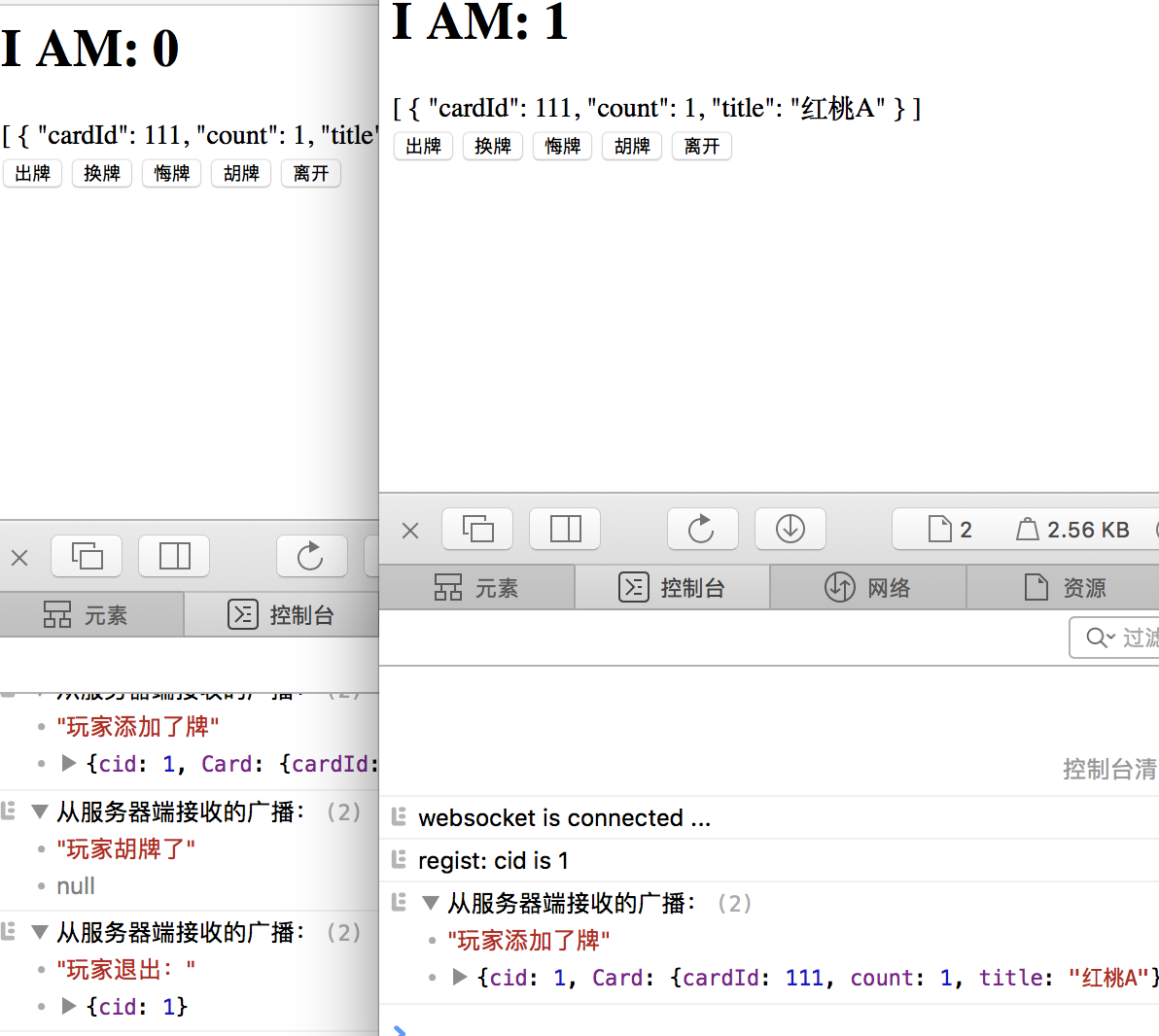
可以看到
3. 数据帧格式
官方文档提供了一个结构图
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + | Extended payload length continued, if payload len == 127 | + - - - - - - - - - - - - - - - +-------------------------------+ | |Masking-key, if MASK set to 1 | +-------------------------------+-------------------------------+ | Masking-key (continued) | Payload Data | +-------------------------------- - - - - - - - - - - - - - - - + : Payload Data continued ... : + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + | Payload Data continued ... | +---------------------------------------------------------------+
第一眼瞟到这张图恐怕是要吐血,如果大学修改计算机网络这门课应该不会对这东西陌生,数据传输协议嘛,是需要定义字节长度及相关含义的。
FIN 1bit 表示信息的最后一帧,flag,也就是标记符 RSV 1-3 1bit each 以后备用的 默认都为 0 Opcode 4bit 帧类型,稍后细说 Mask 1bit 掩码,是否加密数据,默认必须置为1 (这里很蛋疼) Payload 7bit 数据的长度 Masking-key 0 or 4 bit 掩码 Payload data (x + y) bytes 数据 Extension data x bytes 扩展数据 Application data y bytes 程序数据
https://tools.ietf.org/html/rfc6455#section-5.2
Masking-key: 0 or 4 bytes
All frames sent from the client to the server are masked by a
32-bit value that is contained within the frame. This field is
present if the mask bit is set to 1 and is absent if the mask bit
is set to 0. See Section 5.3 for further information on client-
to-server masking.
每一帧的传输都是遵从这个协议规则的,知道了这个协议,那么解析就不会太难了,下面我就直接拿了次碳酸钴同学的代码。
4. 数据帧的解析和编码
数据帧的解析代码:
function decodeDataFrame(e){
var i=0,j,s,frame={
//解析前两个字节的基本数据
FIN:e[i]>>7,Opcode:e[i++]&15,Mask:e[i]>>7,
PayloadLength:e[i++]&0x7F
};
//处理特殊长度126和127
if(frame.PayloadLength==126)
frame.length=(e[i++]<<8)+e[i++];
if(frame.PayloadLength==127)
i+=4, //长度一般用四字节的整型,前四个字节通常为长整形留空的
frame.length=(e[i++]<<24)+(e[i++]<<16)+(e[i++]<<8)+e[i++];
//判断是否使用掩码
if(frame.Mask){
//获取掩码实体
frame.MaskingKey=[e[i++],e[i++],e[i++],e[i++]];
//对数据和掩码做异或运算
for(j=0,s=[];j<frame.PayloadLength;j++)
s.push(e[i+j]^frame.MaskingKey[j%4]);
}else s=e.slice(i,frame.PayloadLength); //否则直接使用数据
//数组转换成缓冲区来使用
s=new Buffer(s);
//如果有必要则把缓冲区转换成字符串来使用
if(frame.Opcode==1)s=s.toString();
//设置上数据部分
frame.PayloadData=s;
//返回数据帧
return frame;
}
数据帧的编码:
//NodeJS
function encodeDataFrame(e){
var s=[],o=new Buffer(e.PayloadData),l=o.length;
//输入第一个字节
s.push((e.FIN<<7)+e.Opcode);
//输入第二个字节,判断它的长度并放入相应的后续长度消息
//永远不使用掩码
if(l<126)s.push(l);
else if(l<0x10000)s.push(126,(l&0xFF00)>>2,l&0xFF);
else s.push(
127, 0,0,0,0, //8字节数据,前4字节一般没用留空
(l&0xFF000000)>>6,(l&0xFF0000)>>4,(l&0xFF00)>>2,l&0xFF
);
//返回头部分和数据部分的合并缓冲区
return Buffer.concat([new Buffer(s),o]);
}
有些童鞋可能没有明白,应该解析哪些数据。这的解析任务主要是服务端处理,客户端送过去的数据是二进制流形式的,比如:
var ws = new WebSocket("ws://127.0.0.1:8000/");
ws.onopen = function(){
ws.send("握手成功");
};
Server 收到的信息是这样的:

一个放在Buffer格式的二进制流。而当我们输出的时候解析这个二进制流:
//服务器程序
var crypto = require('crypto');
var WS = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11';
require('net').createServer(function(o){
var key;
o.on('data',function(e){
if(!key){
//握手
key = e.toString().match(/Sec-WebSocket-Key: (.+)/)[1];
key = crypto.createHash('sha1').update(key + WS).digest('base64');
o.write('HTTP/1.1 101 Switching Protocols\r\n');
o.write('Upgrade: websocket\r\n');
o.write('Connection: Upgrade\r\n');
o.write('Sec-WebSocket-Accept: ' + key + '\r\n');
o.write('\r\n');
}else{
// 输出之前解析帧
console.log(decodeDataFrame(e));
};
});
}).listen(8000);
那输出的就是一个帧信息十分清晰的对象了: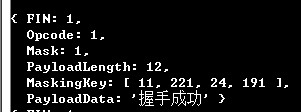
5. 连接的控制
上面我买了个关子,提到的Opcode,没有详细说明,官方文档也给了一张表:
|Opcode | Meaning | Reference | -+--------+-------------------------------------+-----------| | 0 | Continuation Frame | RFC 6455 | -+--------+-------------------------------------+-----------| | 1 | Text Frame | RFC 6455 | -+--------+-------------------------------------+-----------| | 2 | Binary Frame | RFC 6455 | -+--------+-------------------------------------+-----------| | 8 | Connection Close Frame | RFC 6455 | -+--------+-------------------------------------+-----------| | 9 | Ping Frame | RFC 6455 | -+--------+-------------------------------------+-----------| | 10 | Pong Frame | RFC 6455 | -+--------+-------------------------------------+-----------|
decodeDataFrame 解析数据,得到的数据格式是:
{
FIN: 1,
Opcode: 1,
Mask: 1,
PayloadLength: 4,
MaskingKey: [ 159, 18, 207, 93 ],
PayLoadData: '握手成功'
}
那么可以对应上面查看,此帧的作用就是发送文本,为文本帧。因为连接是基于 TCP 的,直接关闭 TCP 连接,这个通道就关闭了,不过 WebSocket 设计的还比较人性化,关闭之前还跟你打一声招呼,在服务器端,可以判断frame的Opcode:
var frame=decodeDataFrame(e);
console.log(frame);
if(frame.Opcode==8){
o.end(); //断开连接
}
客户端和服务端交互的数据(帧)格式都是一样的,只要客户端发送 ws.close(), 服务器就会执行上面的操作。相反,如果服务器给客户端也发送同样的关闭帧(close frame):
o.write(encodeDataFrame({
FIN:1,
Opcode:8,
PayloadData:buf
}));
客户端就会相应 onclose 函数,这样的交互还算是有规有矩,不容易出错。
二、注意事项
1. WebSocket URIs
很多人可能只知道 ws://text.com:8888,但事实上 websocket 协议地址是可以加 path 和 query 的。
ws-URI = "ws:" "//" host [ ":" port ] path [ "?" query ] wss-URI = "wss:" "//" host [ ":" port ] path [ "?" query ]
如果使用的是 wss 协议,那么 URI 将会以安全方式连接。 这里的 wss 大小写不敏感。
2. 协议中”多余”的部分(吐槽)
握手请求中包含Sec-WebSocket-Key字段,明眼人一下就能看出来是websocket连接,而且这个字段的加密方式在服务器也是固定的,如果别人想黑你,不会太难。
再就是那个 MaskingKey 掩码,既然强制加密了(Mask为1表示加密,加密方式就是 MaskingKey 与 PayLoadData 进行异或处理),还有必要让开发者处理这个东西么?直接封装到内部不就行了?
3. 与 TCP 和 HTTP 之间的关系
WebSocket协议是一个基于TCP的协议,就是握手链接的时候跟HTTP相关(发了一个HTTP请求),这个请求被Server切换到(Upgrade)websocket协议了。websocket把 80 端口作为默认websocket连接端口,而websocket的运行使用的是443端口。
三、参考资料
- http://tools.ietf.org/html/rfc6455 web standard – The WebSocket Protocol
- http://www.w3.org/TR/websockets/ W3.ORG – WebSockets
四、特别感谢
再次感谢 次碳酸钴 跟我交流了几个小时 : ),本文部分 node 代码参考自他的博客。
下次将以php作为后台,讲解websocket的相关知识。
文章部分内容纠正:






 本文记录我对 Vary 的一些研究,其中就包含这些问题的答案。
本文记录我对 Vary 的一些研究,其中就包含这些问题的答案。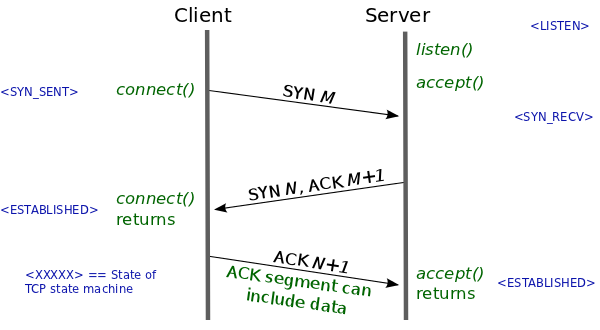









2、console.log(crypto.createHash(‘sha1’).update(‘dGhlIHNhbXBsZSBub25jZQ==258EAFA5-E914-47DA-95CA-C5AB0DC85B11’).digest(‘sha1’)); //输出:<SlowBuffer b3 7a 4f 2c c0 62 4f 16 90 f6 46 06 cf 38 59 45 b2 be c4 ea>,不像你的,前面带0x,你是怎么弄的?
3、解码部分:if(frame.PayloadLength==126) frame.length=(e[2]<<8) + e[3], i=4; //其中的frame.length,好像应该是frame.Payloadlength。下一行中也是。看了一下,次碳酸钴,那边已经改了。
4、编码部分:s.push(126,(l&0xFF00)>>2,l&0xFF); 其中的>>2,好像应该是>>8。下一行类似。