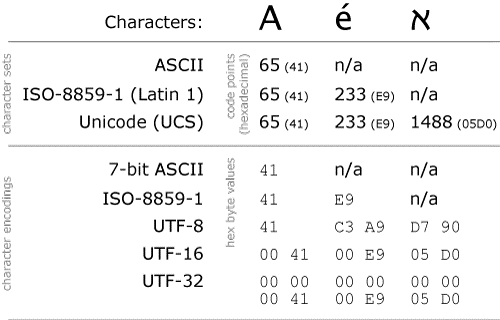
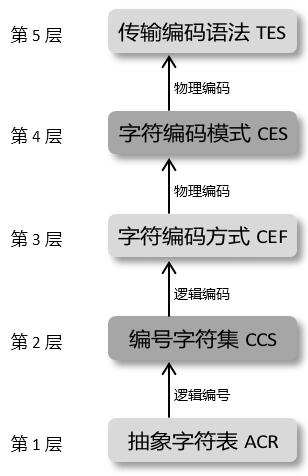
大白话之http编码总结:
1、从本质上看url编码过程:【分成path路径部分和querystring查询串部分】
scheme://host[:port#]/path/…/[url-params] (路径) [?query-string][#anchor](查询字符串,#anchor 这个是文章锚点,用于定位文章的小标题)
浏览器的问题主要是路径(pathinfo)和查询字符串(querystring)的编码问题。
2、 RFC 3986(2005年出版),建议所有新的URI必须对未保留字符不加以百分号编码;其它字符建议先转换为UTF-8字节序列, 然后对其字节值使用百分号编码。此前的URI不受此标准的影响。【按道理来说,编码问题应该解决了】
但是因为历史原因,部分浏览器的url ,还没有完全采用utf-8编码。说白了大家统一认为path路径是用utf-8编码的没有问题,但是querystring 查询串该怎么编码,意见不统一。
总结来说:Path路径中需要编码的内容都是用utf-8编码的,浏览器编码问题就是querystring查询串的编码问题,因为意见不统一。
3、补充:查询串 querystring 也包括:
表单的enctype属性为application/x-www-form-urlencoded 的post请求,因为请求体中的数据也是经过urlencoded。【虽然这是旧的url编码,需要注意空格会编码成 +】这时候请求体中的数据也相当于querystring ,只是请求体中不包含?符号。
4、将path路径的二进制流 和 querystring请求串的二进制流,拼接在一起就是完整的url二进制请求流。【当然放在请求体中的请求串不算url的一部分】
5、请求头中出现Content-Type字段 ,是为了通知服务器,我有请求体。
比如: Content-Type: application/x-www-form-urlencoded
响应头中出现Content-Type字段 ,是为了通知客户端,我有响应体。
比如: Content-Type: application/json;charset=UTF-8
6、所有http流都是ASCII编码的二进制流,除了表单用post提交且编码用 multipart/form-data 的情况,这时候请求头还是ASCII流,但是请求体中上传文件是二进制原文件流,请求体中的表单元素都是按表单环境中的编码方式 编码成二进制流,至于请求体中的其他的模板内容如——WebKitFormBoundaryo2ilS97ZdtneTvV5
Content-Disposition:form-data;name=”name-file”;filename= 等等 还是用ASCII编码的二进制流
一、path路径编码详解
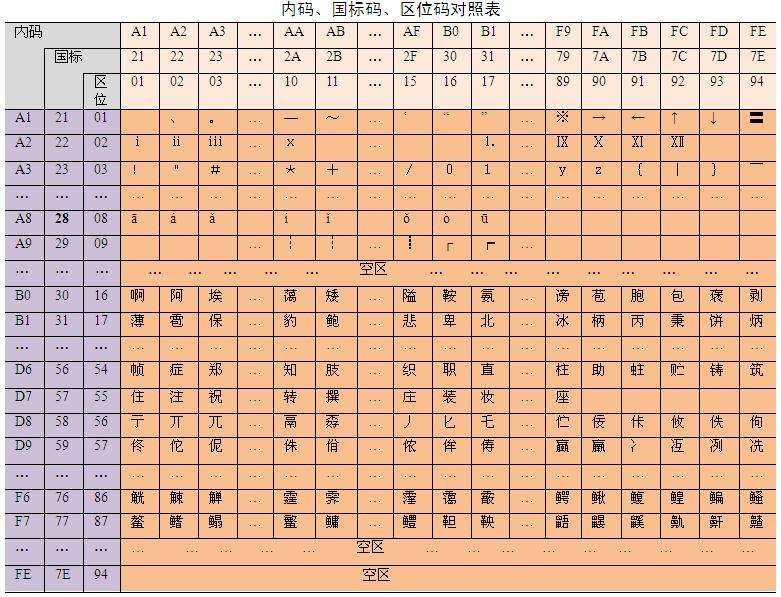
根据rfc3986,无论什么环境,什么浏览器,在path路径编码中,将需要的编码的字符,按utf-8编码。编码后以16进制展示,接着将16进制的展示符号,两两一组(相当于一个字节)为一个单元,在每个单元前添加百分号(%),最后将整个path进行 ASCII编码。
大白话:比如网站路径:www.baidu.com/春节
将春节:utf-8编码,E6 98 A5 E8 8A 82,然后在每个字节前添加百分号(%),即:%E6%98%A5%E8%8A%82【这算进行了一次编码,后面又会对每个字符再进行ASCII编码,变成二进制流】
第一步网站地址 部分utf-8编码:
www.baidu.com/%E6%98%A5%E8%8A%82
第二步网站地址 全部ASCII编码后 真正的二进制流:
77 77 77 2E 62 61 69 64 75 2E 63 6F 6D 2F 25 45
36 25 39 38 25 41 35 25 45 38 25 38 41 25 38 32
二、querystring查询串编码详解
1、在浏览器地址栏输入的查询串
比如输入: http://www.test.com/春节?name=春节&psw=123
所有浏览器的path路径都是用utf-8编码的,此时查询串的编码根据浏览器不同可以分为两类。
第一类: 将查询串两步编码成二进制流 ,比如 firefox,chrome,Safari,edge。
面对 ?name=春节&psw=123 。
做法是:浏览器根据自身默认的编码方式,对查询串进行编码并添加百分号。然后再继续进行第二步ASCII编码。
##### 都遵循标准url编码规范,都将查询串中需要编码的部分 采用浏览器默认的 utf-8 编码 并添加百分号
##### 编码前 ?name=春节&psw=123
##### 编码后 ?name=%E6%98%A5%E8%8A%82&psw=123
##### ASCII码继续 编码成二进制流
3F 6E 61 6D 65 3D 25 45 36 25 39 38 25 41 35 25
45 38 25 38 41 25 38 32 26 70 73 77 3D 31 32 33
第二类:将查询串一步编码成二进制流,比如IE浏览器。
面对 ?name=春节&psw=123
做法是:直接把这个 ?name=春节&psw=123 编码成二进制流,一步到位。编码方式与浏览器环境有关。中文IE 默认用 gb2312 编码方式将查询串编码。
### 中文IE 默认用 gb2312 编码查询串
###【主要是用gb2312编码 春节 二字,至于剩余的符号,因为gb2312是ASCII的一个拓展,所有用gb2312编码和ASCII编码都是一样的】
### 查询串 ?name=春节&psw=123 编码后的二进制流
3F 6E 61 6D 65 3D B4 BA BD DA 26 70 73 77 3D 31 32 33
再举一个例子:
chrome:https://wuu.wikipedia.org/wiki/%E6%98%A5%E8%8A%82?%E6%98%A5%E8%8A%82
#Request Headers
:authority: wuu.wikipedia.org
:method: GET
:path: /wiki/%E6%98%A5%E8%8A%82?%E6%98%A5%E8%8A%82
:scheme: https
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7
cookie: WMF-Last-Access-Global=13-Aug-2018; GeoIP=JP:13:Tokyo:35.69:139.75:v4; WMF-Last-Access=13-Aug-2018
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36
我们知道,”春”和”节”的utf-8编码分别是”E6 98 A5″和”E8 8A 82″,因此,”%E6%98%A5%E8%8A%82″就是按照顺序,在每个字节前加上%而得到的。
所以 chrome浏览器,url中的 路径path 和 查询串 query string 都是UTF-8编码。其实Firefox, Safari ,Edge 都是 同样的。
##### utf-8 编码后 %E6%98%A5%E8%8A%82
##### 又经过第二次 ASCII 编码后
25 45 36 25 39 38 25 41 35 25 45 38 25 38 41 25 38 32
至于,IE 浏览器 无论 IE 8 还是 IE 11 ,路径 path是UTF-8 编码,【查询串queryString 则按照 浏览器默认 编码来进行。比如 中文的IE 用的 就是 GB2312编码。 而且是一步到位,直接编码成二进制流,没有百分号编码的过程。】
IE浏览器:www.baidu.com/春节?春节
#Request Headers
GET /%E6%98%A5%E8%8A%82?���� HTTP/1.1
Accept: image/gif, image/jpeg, image/pjpeg, image/pjpeg, application/x-shockwave-flash, application/xaml+xml, application/x-ms-xbap, application/x-ms-application, */*
Accept-Language: zh-cn
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: www.baidu.com
Cookie: BAIDUID=DFF7C9EB333036D329E7EB55757711B7:FG=1; BIDUPSID=D05CF78322A0985BC8FD928169BC4BF1; PSTM=1533825584; H_PS_PSSID=; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BD_UPN=1123314151; H_PS_645EC=9c51wK0QsNr9o%2BoxCNqWR7faZJlxa6F7GdNch0OwzQznYCdO%2B5jhAlHofJh5PLalplC3%2BoaOqoNeFg
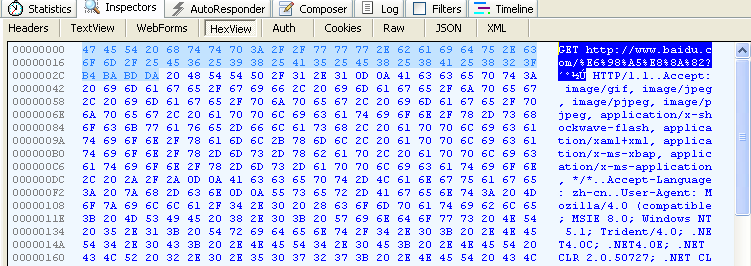
我们知道,”春”和”节”的GB2312编码(我的操作系统”Windows XP”中文版的默认编码)分别是”B4 BA”和”BD DA”。因此,IE实际上就是将查询字符串,以GB2312编码的格式发送出去。至于,路径pathinfo 还是 用utf-8 的形式,比如春节两字的编码– %E6%98%A5%E8%8A%82【但是IE的查询串没有用%编码,直接GB2312编码成二进制流,与其他浏览器先百分号编码,再编码成二进制流不同】
=======================================================
参考其他文章,说以前Firefox的 pathInfo和queryString都是URL encode按照GB2312编码的。对于中文IE,如果在高级选项中选中总以UTF-8发送(默认方式),则PathInfo是URL Encode是按照UTF-8编码,QueryString是按照GBK编码。 很显然,不同的浏览器以及同一浏览器的不同设置,会影响最终URL中PathInfo的编码。
按照RFC3986 的规定,需要编码的字符,都应该用utf-8编码成字节流,然后百分号编码。所以这是浏览器的历史遗留问题。
根据现在的浏览器情况:浏览器地址栏直接输入:
Chrome,Safari,Edge,Firefox,pathInfo和query string 都是utf-8编码
IE pathInfo 用utf-8 编码,query string 用 gb2312 编码
2、点击超链接生成的查询串
比如网页中有如下超链接:
<a href="gbk-response/春节?name=春节&psw=123">go</a>
所有浏览器的path路径都是用utf-8编码的,此时查询串的编码根据浏览器不同可以分为两类。
第一类: 将查询串两步编码成二进制流 ,比如 firefox,chrome,Safari,edge。
面对 ?name=春节&psw=123 。
做法是:
1、浏览器首先根据网页中设置的编码方式对查询串进行编码并添加百分号。
<meta http-equiv="content-type" content="text/html;charset=utf-8">
2、如果网页中找不到指定的编码方法,浏览器就会采用自身默认的编码方式,对查询串进行编码并添加百分号(中文环境下firefox,chrome,Safari,edge,默认都是utf-8 编码),然后再继续对查询串进行第二步ASCII编码。
第二类:将查询串一步编码成二进制流,比如IE浏览器。
面对 ?name=春节&psw=123
做法是:
1、浏览器首先根据网页中设置的编码方式对查询串一步到位编码成二进制流。
<meta http-equiv="content-type" content="text/html;charset=utf-8">
2、如果网页中找不到指定的编码方法,浏览器就会采用自身默认的编码方式(中文环境下 IE 默认采用gb2312编码)一步到位编码成二进制流。
3、表单提交生成的查询串
如果请求串,由表单提交生成且表单的enctype属性为 application/x-www-form-urlencoded【默认属性】,无论是get还是post方法,都会进行百分号编码【当然这种旧url编码需要注意 空格会编码成 +】
form元素有个enctype属性,可以指定数据编码方式,有如下三种:
1. application/x-www-form-urlencoded: 表单数据编码为键值对,&分隔
2. multipart/form-data: 表单数据编码为一条消息,每个控件对应消息的一部分
3. text/plain: 表单数据以纯文本形式进行编码
详细说明:
form的enctype的编码方式,常用有两种:
application/x-www-form-urlencoded和multipart/form-data
其中 application/x-www-form-urlencoded为默认编码方式。
在form的action为get时,浏览器用x-www-form-urlencoded的编码方式,将表单数据编码为
(name1=value1&name2=value2...),然后把这个字符串append到url后面,用?分隔,跳转
到这个新的url
当form的action为post时,浏览器将form数据封装到http body中,然后发送到server。
在没有type=file时候,用默认的 application/x-www-form-urlencoded 就行。
在有 type=file 时候,要用multipart/form-data编码方式。浏览器会把表单以控件为单位分割,
并且为每个部分加上Content-Dispositon(form-data或file)、Content-Type(默认text/plain)、
name(控件name)等信息,并加上分割符(boundary)。
假设浏览器所在环境,采用UTF-8编码将表单信息编码成querystring【编码选择方式后文会讲到】
1、如果浏览器用get方式请求 http://www.test.com/春节?name=春节&psw=123
则url显示结果为:http://www.test.com/%E6%98%A5%E8%8A%82?name=%B4%BA%BD%DA&pwd=123
2、如果浏览器是post请求方式:则url显示结果为http://www.test.com/%E6%98%A5%E8%8A%82
且请求体中有:name=%B4%BA%BD%DA&pwd=123
不管是放在url中还是请求体中,接下来仍需要将请求串ASCII编码。
### 已经过一次编码的请求串
?name=%E6%98%A5%E8%8A%82&psw=123
### ASCII码继续 编码成二进制流
3F 6E 61 6D 65 3D 25 45 36 25 39 38 25 41 35
25 45 38 25 38 41 25 38 32 26 70 73 77 3D 31
### 注意放在请求体中的请求串(严格来讲已不叫请求串了)
### 因为请求体中的请求串没有问号(?)所以请求体的二进制流要去掉第一个3F
4、表单提交生成的查询串的编码选择
(1)如果网页中 的head标签中 没有指定 网页编码类型
比如缺少类似下面这个的
<meta http-equiv="content-type" content="text/html;charset=utf-8">
那么浏览器会使用默认的编码方式进行解码,这样会出现乱码的可能。比如mac下的chrome浏览器,我这边测试出来默认编码是用gb2312的。如果网页没直接指明编码方式,那么如果是gb2312编码的网页那会显示正确。如果是utf-8编码的网页,网页就会解析错误,产生乱码。因为浏览器默认是用GB2312解码网页的。
测试了一下Safari,发现浏览器默认编码即不是utf-8,也不是GB2312。
测试了一下Firefox,浏览器默认编码是GB2312。
测试了一下IE,浏览器默认编码是GB2312。
注:浏览器默认编码可能和系统默认编码有关。【如中文系统和英文系统】
(2)如果表单中,指定了accept-charset
网页里的form编码其实不完全取决于网页编码,form标记中有一个accept-charset属性,在非ie浏览器种,如果将其赋值(比如accept-charset=”UTF-8″),则表单会按照这个值表示的编码方式,将需要编码的字符编码成字节流,然后采用 application/x-www-form-urlencoded 非标准URL编码。
<form action="form_action.asp" accept-charset="utf-8">
<p>First name: <input type="text" name="fname" /></p>
<p>Last name: <input type="text" name="lname" /></p>
<input type="submit" value="Submit" />
</form>
定义和用法
accept-charset 属性规定服务器处理表单数据所接受的字符集。此属性的默认值是 “unknown”,表示表单的字符集与包含表单的文档的字符集相同。
提示:请避免使用该属性。应该在服务器端验证文件上传。
浏览器支持
除了 Internet Explorer,accept-charset 属性得到几乎所有浏览器的支持。
注释:accept-charset 属性无法在 Internet Explorer 中正确地工作。如果 accept-charset 属性设置为 “ISO-8859-1″,IE 将发送以 “Windows-1252” 编码的数据。
我在chrome浏览器中测试过,gb2312编码的网页,表单用指定用utf-8编码。
结果我发现,请求头中 Content-Type: application/x-www-form-urlencoded 也不存在 charset=xxx 的字段。
POST http://192.168.2.233/http_encode/gbk-response/%E6%98%A5%E8%8A%82 HTTP/1.1
Host: 192.168.2.233
Connection: keep-alive
Content-Length: 32
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://192.168.2.233
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Referer: http://192.168.1.133/~cool/http_encode/gbk-post.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
name=%E6%98%A5+%E8%8A%82&pwd=123
在ie下,我的兼容解决办法是:
form1.onsubmit=function(){
document.charset=this.getAttribute('accept-charset');
}
三、表单知识补充
1、四种常见的 POST 提交数据方式
(1)application/x-www-form-urlencoded
(2)multipart/form-data
(3)application/json
(4)text/xml(xml-rpc)
2、表单提交方式GET与POST的区别
当用GET提交时,会将表单信息变成query string 查询字符串。根据 网页中 head 标签 里面设定的编码方案 将 query string 中 需要编码的字符 编码成字节流 。然后再用非标准的url编码。【大白话,GET提交表单时,表单信息变成了URL里面的query string,即在http协议的请求行中】
因为 query string 在表单 中 ,采用的 是 application/x-www-form-urlencoded 非标准URL编码。 这和标准的URL编码有区别。比如编码空格时标准url编码成”%20″,非标准url编码成”+”。
========================================================
当用POST提交表单时,会将表单信息变成FORM DATA,存放在http协议中的 请求体中。FORM DATA 和query string 一样,也是将 需要编码的部分,根据网页head中设定的编码方式,编码成字节流。然后采用 application/x-www-form-urlencoded 非标准URL编码。
同时,会在请求头中 加入:
Content-Type: application/x-www-form-urlencoded
注意:无论是GET还是POST方式,将表单信息编码成字节流时,空格是不需要编码的,所以后面采用 application/x-www-form-urlencoded 非标准URL编码时,空格 一定会被编码成 “+”符号。
3、表单中的enctype属性
表单常用属性:
action:url 地址,服务器接收表单数据的地址
method:提交服务器的http方法,一般为post和get
name:参数名属性
######################################
enctype: 表单数据提交时使用的编码类型,默认使用"aplication/x-www-form-urlencoded",
如果是使用POST请求,则请求头中的content-type指定值就是该值。因为包含了请求体。
如果是使用GET请求,通过URL的query string传递参数,没有请求体,所以不需要content-type
######################################
如果表单中有上传文件,编码类型需要使用"multipart/form-data",类型,才能完成传递文件数据。
<form action="/upload" enctype="multipart/form-data" method="post">
Username: <input type="text" name="username">
Password: <input type="password" name="password">
File: <input type="file" name="file">
<input type="submit">
</form>
4、表单用post提交,并且编码用 multipart/form-data 的情况
这种情况下,除了上传的文件直接采用二进制流没有再编码,其他的表单信息编码方式和x-www-form-urlencoded一样。举例如下:
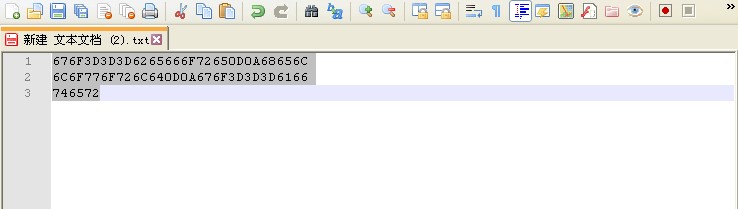
表单信息:【name-desc 填写 春节 二字,上传的文件为 春节.txt】
<form action="testfileupload" method="post" enctype="multipart/form-data" accept-charset="gb2312">
File:<input type="file" name="name-file"/>
Desc:<input type="text" name="name-desc"/>
<input type="submit" name="name-submit" value="submit" />
</form>
待上传文件:春节.txt
文件内容:
good春节OK
hello
文件二进制代码:
【备注在Windows的记事本软件中如果用utf-8编码保存时,会自动在保存信息中添加EF BB BF 字节序,而mac系统下不会,这里实验采用mac系统】
676f 6f64 e698 a5e8 8a82 4f4b 0d0a 6865
6c6c 6f
提交请求时,fiddler2抓包结果:
POST http://192.168.1.131:8080/springmvc-2/testfileupload HTTP/1.1
Host: 192.168.1.131:8080
Connection: keep-alive
Content-Length: 410
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://192.168.1.131:8080
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryo2ilS97ZdtneTvV5
Referer: http://192.168.1.131:8080/springmvc-2/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=A15ECBF73D297496D7785129A231A321
------WebKitFormBoundaryo2ilS97ZdtneTvV5
Content-Disposition: form-data; name="name-file"; filename=" .txt"
Content-Type: text/plain
good春节OK
hello
------WebKitFormBoundaryo2ilS97ZdtneTvV5
Content-Disposition: form-data; name="name-desc"
------WebKitFormBoundaryo2ilS97ZdtneTvV5
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundaryo2ilS97ZdtneTvV5--
http请求特别解析:
##### 下面的 filename=" .txt" 其实是 filename="春节.txt"
##### 之所有 出现空白是表单信息中 春节 2个字 二进制信息是 B4 BA BD DA ,采用了GBK编码
##### 而 fiddler2 显示信息 用的是 utf-8 编码 所有显示不出来
Content-Disposition: form-data; name="name-file"; filename=" .txt"
##### 下面第三行默认是空白,而第四行 也是 空白 但是 有二进制信息 是 B4 BA BD DA
------WebKitFormBoundaryo2ilS97ZdtneTvV5
Content-Disposition: form-data; name="name-desc"
如果把表单 删除gb2312编码,也就是用 网页内定 的utf-8 编码:
<form action="testfileupload" method="post" enctype="multipart/form-data" >
File:<input type="file" name="name-file"/>
Desc:<input type="text" name="name-desc"/>
<input type="submit" name="name-submit" value="submit" />
</form>
抓包结果:
POST http://192.168.1.131:8080/springmvc-2/testfileupload HTTP/1.1
Host: 192.168.1.131:8080
Connection: keep-alive
Content-Length: 414
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://192.168.1.131:8080
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary4v5NL53bCqC2d9fH
Referer: http://192.168.1.131:8080/springmvc-2/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=A15ECBF73D297496D7785129A231A321
------WebKitFormBoundary4v5NL53bCqC2d9fH
Content-Disposition: form-data; name="name-file"; filename="春节.txt"
Content-Type: text/plain
good春节OK
hello
------WebKitFormBoundary4v5NL53bCqC2d9fH
Content-Disposition: form-data; name="name-desc"
春节
------WebKitFormBoundary4v5NL53bCqC2d9fH
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundary4v5NL53bCqC2d9fH--
从这里我们能够看到,所有 春节 两字 编码信息 都是 utf-8 编码,都能在fiddler2 抓包中,正确显示。
从结果比较来看, multipart/form-data 的请求体中,上传文件的表单单元,不需要再编码,直接传输文件二进制流,因为春节.txt是utf-8编码,而fiddler2默认是用utf-8解码,所有解码正确。至于其他的表单单元,根据表单环境提供的编码方式编码,然后传递。上面的例子,表单第一次编码是gb2312,而fiddler2是utf-8解码,导致抓包时,信息解码错误。表单第二次编码是utf-8,和fiddler2的解码一致,所以信息抓包解码正确。
======================================================
特别说明:如果改成了iso-8859-1的编码表单
<form action="testRequestBody" method="post" enctype="multipart/form-data" accept-charset="iso-8859-1">
File:<input type="file" name="name-file"/>
Desc:<input type="text" name="name-desc"/>
<input type="submit" name="name-submit" value="submit" />
</form>
上传文件名还是春节.txt ,表单输入的name-desc 也还是 春节
这个时候fiddler2抓包二进制流,然后用utf-8解码结果:
POST http://192.168.1.131:8080/springmvc-2/testRequestBody HTTP/1.1
Host: 192.168.1.131:8080
Connection: keep-alive
Content-Length: 420
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://192.168.1.131:8080
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary3FCh7yh4z2wpPZo9
Referer: http://192.168.1.131:8080/springmvc-2/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=07D6AF477CEE3B7CDB6A1847E2ECB3A4
------WebKitFormBoundary3FCh7yh4z2wpPZo9
Content-Disposition: form-data; name="name-file"; filename="??.txt"
Content-Type: text/plain
good春节OK
hello
------WebKitFormBoundary3FCh7yh4z2wpPZo9
Content-Disposition: form-data; name="name-desc"
春节
------WebKitFormBoundary3FCh7yh4z2wpPZo9
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundary3FCh7yh4z2wpPZo9--
我们看到:请求体中
文件名为: filename=”??.txt” 查看二进制发现春节两字 编码成 3F 3F
而 表单中 name-desc 值为: 春节 【这个26149 33410 分别是春节的Unicode 十进制 值】【春节 这两个都可以用ASCII解码成二进制流比如 &#代表26 23】
从这里我们能够看出来:表单用 multipart/form-data 传递信息时,当遇到表单信息无法编码时,表单中的不同类型,应对结果可能不同。比如 表单中的文件名应对错误编码的结果与 表单中 name-desc 应对错误编码的结果不同。但是,如果表单能被正确编码,那么两者编码结果值相同(因为两者原码相同)。
后来,我们又将表单编码设置成立utf-16,但是抓包结果来看,表单信息还是被编码成了utf-8,所以感觉没有效果。
当我们将表单 用big5 编码时,上传文件名 改为:春節 ,表单填写name-desc时 也改为 春節 ,抓包结果看到这两处 春節 都被编码成了 AC 4B B8 60 二进制流。至于文件中的信息春节,因为文件用utf-8编码过的二进制流,直接放入请求体中,不需要二次编码,所以不受表单编码的影响。
我们知道的是表单信息提交时,会按照表单设置的编码进行发送。但是对于 上传文件,用的是原始二进制流,不用编码。现在有一个疑问,就是http请求中,默认格式字符信息,用的是ASCII编码 还是 用表单设置的编码,目前我看到的表单编码都是兼容ASCII码的(比如UTF-8,GBK,big5 兼容ASCII),所以无法实质区分。曾尝试用utf-16设置表单编码,但是抓包后发现,表单信息居然采用了utf-8 编码。所以区分不了。
四、url编码与javascript
url编码-JavaScript-函数
escape 、 encodeURI 、encodeURIComponent
首先,无论网页的编码方式是什么,都可以正确解析,毕竟编码和解码是对应统一的。JavaScript引擎根据 已经编码好的网页二进制流 和 网页的编码方式 , 将网页二进制信息流正确转码成JavaScript引擎内部能处理的二进制流【内部编码要么是ucs-2 或者是 utf -16,待探究】
所以,JavaScript 中的 函数参数 也会 编码成 内部编码。【JavaScript内部编码可能是 ucs-2,utf-16,总之:两个字节内,编码的结果都是一样的,以后再探讨到底是哪种编码 】
javascript:escape("\u6625\u8282"); ==> 反斜杠 \ 代表Unicode转义字符。以Unicode字符序的方式接收
javascript:escape("春节"); ==> 春节 二字,代表默认的字符 接收
#这里的函数参数 春节 或者 Unicode排序值 都将内部都编码成了 UCS-2 或者 UTF-16
#这里的函数返回值 就是 将内部编码后的数据 进行运算,并将运算结果转码成 Unicode排序值,然后输出
编码问题归纳:记录网页信息的网页编码 和 JavaScript引擎处理网页信息的内部编码。
下面列出了这三个函数的安全字符(即函数不会对这些字符进行编码)
escape(69个):*/@+-._0-9a-zA-Z
encodeURI(82个):!#$&'()*+,/:;=?@-._~0-9a-zA-Z
encodeURIComponent(71个):!'()*-._~0-9a-zA-Z
encodeURI('https://www.baidu.com/ a b c')
// "https://www.baidu.com/%20a%20b%20c"
encodeURIComponent('https://www.baidu.com/ a b c')
// "https%3A%2F%2Fwww.baidu.com%2F%20a%20b%20c"
//而 escape 会编码成下面这样,eocode 了冒号却没 encode 斜杠,十分怪异,故废弃之
escape('https://www.baidu.com/ a b c')
// "https%3A//www.baidu.com/%20a%20b%20c"
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode排序值。比如”春节”的返回结果是%u6625%u8282,也就是说在Unicode字符集中,”春”是第6625个(十六进制)字符,”节”是第8282个(十六进制)字符。
春的Unicode排序值为:6625(十六进制) ; 26149(十进制)
春的utf-8编码值为:E6 98 A5(十六进制) ;URL编码采用的是utf-8 编码!!!
Javascript:escape("春节");
"%u6625%u8282"
Javascript:escape("Hello World");
"Hello%20World"
### 反斜杠 \ 代表Unicode转义字符 ,以Unicode字符序的方式接收。
javascript:escape("\u6625\u8282");
"%u6625%u8282"
javascript:unescape("%u6625%u8282");
"春节"
javascript:unescape("\u6625\u8282");
"春节"
escape()的具体规则是,除了ASCII字母、数字、标点符号”@ * _ + – . /”以外,对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
escape()不对”+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
escape函数已经被W3C废弃了。因为 escape函数 返回的是Unicode 排序值,不是 utf-8 编码值。不符合RFC3986 标准。但是在ECMA-262标准中仍然保留着escape的这种编码语法。
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号”; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
encodeURI("http://www.cnblogs.com/season-huang/some other thing");
//"http://www.cnblogs.com/season-huang/some%20other%20thing";
编码后变为上述结果,可以看到空格被编码成了%20,而斜杠 / ,冒号 : 并没有被编码。需要注意的是,它不对单引号’编码。
encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,”; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。
使用场景:当我们的 URL 长这样子,请求参数中带了另一个 URL :
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";
//直接对它进行 encodeURI 显然是不行的。
//因为 encodeURI 不会对冒号 : 及斜杠 / 进行转义,
//那么就会出现上述所说的服务器接受到之后解析会有歧义。
encodeURI(URL);
// "http://www.a.com?foo=http://www.b.com?t=123&b=456"
//这个时候,就该用到 encodeURIComponent() 。
//它的作用是对 URL 中的参数进行编码,记住是对参数,而不是对整个 URL 进行编码。
//正确的用法:encodeURIComponent() 着眼于对单个的参数进行编码:
var param = "http://www.b.com?t=123&s=456"; // 要被编码的参数
URL = "http://www.a.com?foo="+encodeURIComponent(param);
//"http://www.a.com?foo=http%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"
url编码-JavaScript-AJAX
GBK编码的gbk-get.html
<!DOCTYPE html>
<html>
<head>
<title>gb2312网页测试get提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=gb2312">
<script type="text/javascript" src="jquery.js"></script>
</head>
<body>
<center>
<a href="gbk-response/春节?name=春节&psw=123">go</a>
<form action="gbk-http-get-response/春节" method="get">
<p>用户名:<input type="text" id="name" name="name"/></p>
<p>密码:<input type="password" id="pwd" name="pwd"/></p>
<input type="submit" value="登录">
<input type="button" value="ajax-get" id="ajax-get-btn"/>
<input type="button" value="ajax-post" id="ajax-post-btn"/>
</form>
</center>
<script>
$("#ajax-get-btn").click(function(){
//发送ajax请求,弹出部门信息,显示在下拉列表中
$.ajax({
url:"gbk-ajax-get-response/春节",
type:"get",
data:"name="+$("#name").val(),
success:function(result){
}
})
});
$("#ajax-post-btn").click(function(){
//获取DOM对象的 value 属性
var name = $("#name")[0].value;
//发送ajax请求,弹出部门信息,显示在下拉列表中
$.ajax({
url:"gbk-ajax-post-response/春节",
type:"post",
//下面这个 ${"#name"}.value 写错了,难怪一直报错。 应该是 $("#name").value
//data:"name="+${"#name"}.value,
data:"name="+name,
success:function(result){
}
})
});
// $("#ajax-get-btn").click(function(){
//
// var name = ${"#name"}.value;
//
// //发送ajax请求,弹出部门信息,显示在下拉列表中
// $.ajax({
// url:"control",
// type:"get",
// // 下面的写法是错误的,正确的是 1、获取DOM属性 data:"name="+$("#name")[0].value, 或者 2、获取JQuery属性 data:"name="+$("#name").val(),
// // data:"name="+${"#name"}.value,
// data:"name="+name,
// success:function(result){
//
// }
//
// })
// });
</script>
</body>
</html>
utf-8编码的文件大致相同:
测试结果:
fiddler2 用 utf-8 解码显示 http请求信息
IE浏览器,gbk网页,用get请求
GET http://192.168.1.131/~sky/http_encode/gbk-ajax-get-response/%B4%BA%BD%DA?name= HTTP/1.1
x-requested-with: XMLHttpRequest
Accept-Language: zh-cn
Referer: http://192.168.1.131/~sky/http_encode/gbk-get.html
Accept: */*
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Host: 192.168.1.131
Connection: Keep-Alive
/%B4%BA%BD%DA?name=
上面用utf-8显示的文字,用16进制表示如下:
2F 25 42 34 25 42 41 25 42 44 25 44 41 3F 6E 61 6D 65 3D B4 BA BD DA
IE浏览器,gbk网页,用post请求
POST http://192.168.1.131/~sky/http_encode/gbk-ajax-post-response/%B4%BA%BD%DA HTTP/1.1
x-requested-with: XMLHttpRequest
Accept-Language: zh-cn
Referer: http://192.168.1.131/~sky/http_encode/gbk-get.html
Accept: */*
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Host: 192.168.1.131
Content-Length: 11
Connection: Keep-Alive
Pragma: no-cache
name=春节
fiddler2 用utf-8 解码http信息:
请求体: name=春节 的二进制码为 6e 61 6d 65 3d e6 98 a5 e8 8a 82
IE浏览器 utf-8 网页 ,用get请求
GET http://192.168.1.131/~sky/http_encode/utf8-ajax-get-response/%B4%BA%BD%DA?name= HTTP/1.1
x-requested-with: XMLHttpRequest
Accept-Language: zh-cn
Referer: http://192.168.1.131/~sky/http_encode/utf-8-get.html
Accept: */*
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Host: 192.168.1.131
Connection: Keep-Alive
/%B4%BA%BD%DA?name=
上面用utf-8显示的文字,用16进制表示如下:
2F 25 42 34 25 42 41 25 42 44 25 44 41 3F 6E 61 6D 65 3D B4 BA BD DA
IE浏览器 utf-8 网页 ,用post请求
POST http://192.168.1.131/~sky/http_encode/utf8-ajax-post-response/%B4%BA%BD%DA HTTP/1.1
x-requested-with: XMLHttpRequest
Accept-Language: zh-cn
Referer: http://192.168.1.131/~sky/http_encode/utf-8-get.html
Accept: */*
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Host: 192.168.1.131
Content-Length: 11
Connection: Keep-Alive
Pragma: no-cache
name=春节
fiddler2 用utf-8 解码http信息:
请求体: name=春节 的二进制码为 6e 61 6d 65 3d e6 98 a5 e8 8a 82
=================================================================
chrome gbk网页 get请求
GET /~sky/http_encode/gbk-ajax-get-response/%E6%98%A5%E8%8A%82?name=%B4%BA%BD%DA HTTP/1.1
Host: localhost
Connection: keep-alive
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Referer: http://localhost/~sky/http_encode/gbk-get.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7
chrome gbk网页 post请求
POST /~sky/http_encode/gbk-ajax-post-response/%E6%98%A5%E8%8A%82 HTTP/1.1
Host: localhost
Connection: keep-alive
Content-Length: 11
Accept: */*
Origin: http://localhost
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: http://localhost/~sky/http_encode/gbk-get.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7
name=春节
抓包发现:请求体的二进制代码为:
6e 61 6d 65 3d e6 98 a5 e8 8a 82
chrome utf-8 get请求
GET /~sky/http_encode/utf8-ajax-get-response/%E6%98%A5%E8%8A%82?name=%E6%98%A5%E8%8A%82 HTTP/1.1
Host: localhost
Connection: keep-alive
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Referer: http://localhost/~sky/http_encode/utf-8-get.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7
chrome utf-8 post请求
POST /~sky/http_encode/utf8-ajax-post-response/%E6%98%A5%E8%8A%82 HTTP/1.1
Host: localhost
Connection: keep-alive
Content-Length: 11
Accept: */*
Origin: http://localhost
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: http://localhost/~sky/http_encode/utf-8-get.html
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7
name=春节
抓包发现:请求体的二进制代码为:
6e 61 6d 65 3d e6 98 a5 e8 8a 82
也就是说,在Ajax调用中,path路径调用不同,IE是%B4%BA%BD%DA,chrome是%E6%98%A5%E8%8A%82。querystring 又和网页的编码有关系,IE 是 一步到位的编码。chrome是两步到位的编码,中间经历了百分号编码。
五、url编码与服务器响应
Apache服务器返回的 Response Headers :
HTTP/1.1 200 OK
Date: Wed, 15 Aug 2018 07:49:34 GMT
Server: Apache/2.4.28 (Unix) PHP/5.5.38
Last-Modified: Wed, 15 Aug 2018 03:41:28 GMT
ETag: "1c2-xxxxxxxxxxxx" 【一串字符串】
Accept-Ranges: bytes
Content-Length: 450
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html【我看到百度Apache服务器,这里是 text/html;charset=utf-8】
百度Apache 服务器 Request Headers
HTTP/1.1 200 OK
Bdpagetype: 3
Bdqid: XXXXXXXXXXXXXXXX
Cache-Control: private
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Cxy_all: news+XXXXXXXXXXXXXXXXXXXXXXXXX
Cxy_ex: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Date: Wed, 15 Aug 2018 07:43:23 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: Apache
Tracecode: XXXXXXXXXXXXXXXXXXXXXXXXX
Vary: Accept-Encoding
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
Nginx 服务器 Request Headers:
HTTP/1.1 200 OK
Server: nginx/1.14.0
Date: Wed, 15 Aug 2018 07:56:25 GMT
Content-Type: text/html
【上面是欢迎页的响应,我个人网站和Nginx官网服务器的响应都是text/html;charset=utf-8】
Content-Length: 612
Last-Modified: Tue, 17 Apr 2018 15:48:00 GMT
Connection: keep-alive
ETag: "XXXXXXXXXX-XXX" 【一串字符串】
Accept-Ranges: bytes
nginx官网服务器:Response Headers
content-encoding: gzip
content-type: text/html; charset=UTF-8
date: Wed, 15 Aug 2018 08:22:48 GMT
link: <https://www.nginx.com/wp-json/>; rel="https://api.w.org/"
link: <https://www.nginx.com/>; rel=shortlink
link: <https://www.nginx.com/wp-json>; rel="https://github.com/WP-API/WP-API"
server: nginx
status: 200
vary: Accept-Encoding, User-Agent
x-cache-config: 0 0
x-cache-status: HIT
x-cache-status: HIT
x-pingback: https://www.nginx.com/xmlrpc.php
x-user-agent: standard
Tomcat 服务器解析 http 请求过程
1、开发人员必须清楚的servlet规范:
(1) HttpServletRequest.setCharacterEncoding()方法 仅仅只适用于设置post提交的request body的编码而不是设置get方法提交的queryString的编码。该方法告诉应用服务器应该采用什么编码解析post传过来的内容。很多文章并没有说明这一点。
(2) HttpServletRequest.getPathInfo()返回的结果是由Servlet服务器解码(decode)过的。
(3) HttpServletRequest.getRequestURI()返回的字符串没有被Servlet服务器decoded过。
(4) POST提交的数据是作为request body的一部分。
(5) 网页的Http头中ContentType(“text/html; charset=GBK”)的作用:
(a) 告诉浏览器网页中数据是什么编码;
(b) 表单提交时,通常浏览器会根据ContentType指定的charset对表单中的数据编码,然后发送给服务器的。
这里需要注意的是:这里所说的ContentType是指http头的ContentType,而不是在网页中meta中的ContentType。
2、Java中的uri 和 url 【和IETF设置的标准不同】
浏览器请求:http://localhost:8080/springmvc-1/春节.jsp?p=春节
写了一个 春节.jsp 文件
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ page language="java" import="java.util.*" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
</head>
<body>
测试完成 uri 与 url
<br>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
out.println("basePath:"+basePath);
out.println("<br/>");
out.println("getContextPath:"+request.getContextPath());
out.println("<br/>");
out.println("getServletPath:"+request.getServletPath());
out.println("<br/>");
out.println("getRequestURI:"+request.getRequestURI());
out.println("<br/>");
out.println("getRequestURL:"+request.getRequestURL());
out.println("<br/>");
out.println("getRealPath:"+request.getRealPath("/"));
out.println("<br/>");
out.println("getServletContext().getRealPath:"+getServletContext().getRealPath("/"));
out.println("<br/>");
out.println("getQueryString:"+request.getQueryString());
%>
</body>
</html>
结果显示:chrome,Safari,Firefox,Edge结果
测试完成 uri 与 url
basePath:http://localhost:8080/springmvc-1/
getContextPath:/springmvc-1
getServletPath:/春节.jsp
getRequestURI:/springmvc-1/%E6%98%A5%E8%8A%82.jsp
getRequestURL:http://localhost:8080/springmvc-1/%E6%98%A5%E8%8A%82.jsp
getRealPath:/Users/hello/Documents/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0/wtpwebapps/springmvc-1/
getServletContext().getRealPath:/Users/hello/Documents/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0/wtpwebapps/springmvc-1/
getQueryString:p=%E6%98%A5%E8%8A%82
IE浏览器显示结果【浏览器地址栏 编码,query string 用了GB2312 导致乱码】
测试完成 uri 与 url
basePath:http://192.168.1.133:8080/springmvc-1/
getContextPath:/springmvc-1
getServletPath:/春节.jsp
getRequestURI:/springmvc-1/%E6%98%A5%E8%8A%82.jsp
getRequestURL:http://192.168.1.133:8080/springmvc-1/%E6%98%A5%E8%8A%82.jsp
getRealPath:/Users/hello/Documents/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0/wtpwebapps/springmvc-1/
getServletContext().getRealPath:/Users/hello/Documents/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0/wtpwebapps/springmvc-1/
getQueryString:p=´º½Ú
Tomcat 服务器 response 报文:
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Content-Type: text/html;charset=UTF-8
Content-Length: 849
Date: Thu, 16 Aug 2018 09:50:30 GMT
java中 request.getServletPath() 和 request.getPathInfo() 的区别 {映射问题造成}
在 Web 中,我们通常需要获取 URL 相对于 Webapp 的路径,主要是下面的几个方法:
request.getServletPath()
request.getPathInfo()
request.getContextPath()
request.getRequestURI()
其中 request.getRequestURI() 的返回值包含了 request.getContextPath(),所以是相对于网站的根目录的。
下面我们分析 request.getServletPath() 和 request.getPathInfo()
1. 如果我们的 servlet-mapping 如下配置:
<servlet-mapping>
<servlet-name>jetbrick-template</servlet-name>
<url-pattern>*.jetx</url-pattern>
</servlet-mapping>
那么访问: /context/templates/index.jetx
request.getServletPath() == "/templates/index.jetx"
request.getPathInfo() == <null>
2. 如果我们的 servlet-mapping 如下配置:
<servlet-mapping>
<servlet-name>jetbrick-template</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
那么访问: /context/templates/index.jetx
request.getServletPath() == ""
request.getPathInfo() == "/templates/index.jetx"
3. 如果我们的 servlet-mapping 如下配置:
<servlet-mapping>
<servlet-name>jetbrick-template</servlet-name>
<url-pattern>/template/*</url-pattern>
</servlet-mapping>
那么访问: /context/templates/index.jetx
request.getServletPath() == "/templates"
request.getPathInfo() == "/index.jetx"
3、tomcat 解析http 流的过程
解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在 org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length -
cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(),
cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}
从上面的代码中可以知道对 URL 的 URI【java标准的uri,上节已提到过】 部分进行解码的字符集是在 connector 的 <Connector URIEncoding=”UTF-8”/> 中定义的,如果没有定义,那么将以默认编码 ISO-8859-1 解析。所以如果有中文 URL 时最好把 URIEncoding 设置成 UTF-8 编码。
QueryString 的解码字符集要么是 Header 中 ContentType 中定义的 Charset 要么就是默认的 ISO-8859-1,要使用 ContentType 中定义的编码就要设置 connector 的 <Connector URIEncoding=”UTF-8” useBodyEncodingForURI=”true”/> 中的 useBodyEncodingForURI 设置为 true。这个配置项的名字有点让人产生混淆,它并不是对整个 URI 都采用 BodyEncoding 进行解码而仅仅是对 QueryString 使用 BodyEncoding 解码,这一点还要特别注意。
关于post表单提交的数据,存放在请求体中,至于如何解码,需要以后探讨。
六、请求头编码与网页内置编码优先级
设置网页编码的方法有:
1.利用php header()函数声明,这个header()函数的作用是把括号里面的信息发到http标头。
header(“Content-type: text/html; charset=xxx”);
2.利用HTML <meta >进行声明,HTML <meta >这个标签的作用是声明客户端的浏览器用什么字符集编码显示该页面
<META http-equiv=”content-type” content=”text/html; charset=xxx”>
3.服务器在response 网页时,也可以 设置 服务器默认响应 编码。就相当于给每个文件都 加了一行header(“content-type:text/html; charset=xxx”)。如果网页里有header(“content-type:text/html; charset=xxx”),就把默认的字符集改为你设置的字符集,所以这个函数永远有用。
所以,网页编码的优先级是:
header(“content-type:text/html; charset=xxx”)
AddDefaultCharset xxx
<META http-equiv=”content-type” content=”text/html; charset=xxx”>
如果你是web程序员,给你的每个页面都加个header(“content-type:text/html; charset=xxx”),保证它在任何服务器都能正确显示,可移植性强。
1,2点 在服务器和浏览器上都可以使用,第3点只能在服务器上使用。
七、其它需要编码的地方
除了 URL 和参数编码问题外,在服务端还有很多地方可能存在编码,如可能需要读取 xml、velocity 模版引擎、JSP 或者从数据库读取数据等。
xml 文件可以通过设置头来制定编码格式
<?xml version="1.0" encoding="UTF-8"?>
Velocity 模版设置编码格式:
services.VelocityService.input.encoding=UTF-8
JSP 设置编码格式:
<%@page contentType="text/html; charset=UTF-8"%>
访问数据库都是通过客户端 JDBC 驱动来完成,用 JDBC 来存取数据要和数据的内置编码保持一致,可以通过设置 JDBC URL 来制定如 MySQL:url=”jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK”。
PHP程序在查询数据库之前,首先执行 mysql_query(“SET NAMES xxxx”);其中 xxxx 是你网页的编码(charset=xxxx),如果网页中 charset=utf8,则 xxxx=utf8,如果网页中 charset=gb2312,则xxxx=gb2312,几乎所有WEB程序,都有一段连接数据库的公共代码,放在一个文件里,在这文件里,加入 mysql_query(“set names”)就可以了。
SET NAMES 显示客户端发送的 SQL 语句中使用什么字符集。因此,SET NAMES ‘utf-8’语句告诉服务器“将来从这个客户端传来的信息采用字符集utf-8”。它还为服务器发送回客户端的结果指定了字符集。(例如,如果你使用一 个SELECT语句,它表示列值使用了什么字符集。)
八、乱码出现的常见原因
在了解了 Java Web 中可能需要编码的地方后,下面看一下,当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
1、中文变成了看不懂的字符
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”编码过程如下图所示
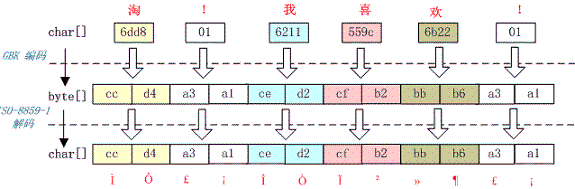
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
2、一个汉字变成一个问号
例如,字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示
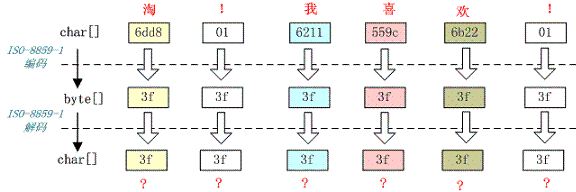
将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
3、一个汉字变成两个问号
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示
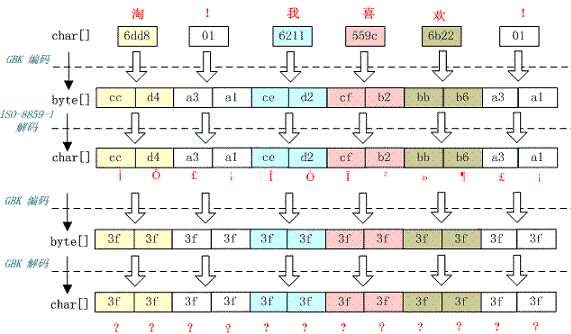
这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。
4、网页中head标签设置的编码和保存网页的编码不同
我用 gb2312 编码 保存了一个网页【大白话,里面的中文都是gb2312编码】。然后我在该网页中,<META http-equiv=”content-type” content=”text/html; charset=xxx”>设置了utf-8编码。 于是出现乱码了。
5、一种不正常的正确编码
还有一种情况是在我们通过 request.getParameter 获取参数值时,当我们直接调用
String value = request.getParameter(name);
会出现乱码,但是如果用下面的方式
String value = String(request.getParameter(name).getBytes("
ISO-8859-1"), "GBK");
解析时取得的 value 会是正确的汉字字符,这种情况是怎么造成的呢?
看下如所示:
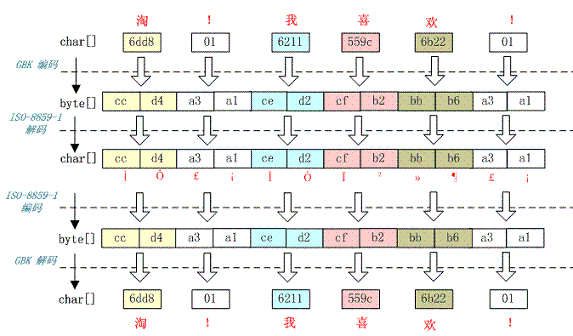
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat 的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
九、http编码优先级及编码别名的宽容性
1、编码优先级问题
根据 HTML4.01 规范中的描述,服务端应该提供给用户端文档的字符编码(character encoding)信息,最直接的方式为通过 HTTP 协议([RFC2616], 3.4 及 14.17) “Content-Type” 头字段的 “charset” 将文档的字符编码告诉用户端。例如以下 HTTP 头声明了字符编码为 ISO-8859-1:
Content-Type: text/html; charset=ISO-8859-1
处于某种情况无法访问服务器时,HTML 文档可以包含有关文档的字符编码的明确信息,META 元素可以用来为用户端提供这些信息。例如指定当前文档的字符编码为 ISO-8859-1,文档中应包含如下 META 声明:
<META http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
当 HTTP 协议与 META 元素均没有提供有关一个文档的字符编码信息时,HTML 还为一些元素提供了 charset 属性。结合这些机制,作者可以在很大程度上提高当用户获取资源时用户端识别字符编码的机会。
针对如何确定一个文档的字符编码,用户代码必须遵守下面的优先级顺序(优先级由高至低):
(1)HTTP “Content-Type” 字段中的 “charset” 参数。
(2)META 声明中 “http-equiv” 为 “Content-Type” 对应的值中的 “charset” 的值。
(3)元素的 charset 属性。
关于 字符编码 的详细信息,请参考 HTML4.01 规范 5.2 Character encodings 以及 W3C Internationalization 关于 Character encodings 中的内容。
2、编码别名宽容性问题
补充知识:做个测试,我们就能明白各浏览器对页面的默认字符编码不尽相同。
当页面没有设置任何字符编码信息或者浏览器无法识别 HTTP 头字段以及 META 元素中所声明的字符编码信息时,所有浏览器均会以各自在当前语言版本下的默认字符编码显示页面。
编码别名宽容性举例:
<?php
header("Content-Type: text/html; charset=maccyrillic");
?>
<!DOCTYPE HTML>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=b.i.g+5"/>
</head>
<body style="font:24px Tahoma;">
字符編碼 ---
<script>
document.write((document.charset || document.characterSet).toUpperCase());
</script>
</body>
</html>
上面的动态页面自身的编码为 BIG5,HTTP “Content-Type” 头字段设置了字符编码为 maccyrillic,页面中的 META 元素设置了字符编码为 b.i.g+5。
各浏览器中运行效果如下:
| IE6 IE7 IE8 Firefox |
Chrome Safari |
Opera |
| 才絪絏 — GB2312 |
¶r≤≈љsљX — X-MAC-CYRILLIC |
字符編碼 — BIG5 |
(1) 在 IE6 IE7 IE8 Firefox 中,浏览器无法识别 maccyrillic 这种字符编码别名,所以寻找更低优先级的 META 元素声明的字符编码,但发现也无法识别 b.i.g+5 这种字符编码别名,继而采用了当前语言版本的默认编码 GB2312,与页面自身的字符编码 BIG5 不相符,导致页面中的文字显示异常。
(2) 在 Chrome Safari 中,浏览器将 maccyrillic 识别为合法的 X-MAC-CYRILLIC,则不再理会更低优先级的编码设置,页面采用 X-MAC-CYRILLIC 作为字符的编码,与页面自身的 BIG5 编码不符,导致页面中的文字显示异常。
(3) 在 Opera 中,浏览器无法识别 maccyrillic 这种字符编码别名,所以寻找更低优先级的 META 元素声明的字符编码,将 b.i.g+5 这种字符编码别名识别为 BIG5,刚好与页面自身的 BIG5 字符编码相符,所以页面中的文字显示正常。
出现上述现象的原因主要有三点:
(1) 各浏览器的字符编码别名表不尽相同,对同一种编码下的各种别名支持的宽泛程度不一样。像 maccyrillic 这种别名在 Chrome Safari 可以识别为通用的 X-MAC-CYRILLIC1,但其他浏览器则会将其视作错误的字符编码信息处理。
(2) 各浏览器在匹配页面的字符编码与别名表中的字符编码时,匹配的方式不同。Chrome Safari Opera 会将编码类型的字符串做一个转换,过滤了除英文大小写字符、数字字符之外的字符(isASCIIAlphanumeric)。如 ISO8859_5 会以转换后的 ISO88595 与别名表中的 ISO-8859-5 转换后的 ISO88595 做比较,b.i.g+5 也会转换为 big5 与别名表中的做比较,所以浏览器可以正确识别这些设置的字符编码为浏览器内部的别名。
(3) 各浏览器的默认字符编码不同。
注:各浏览器均可以识别 X-MAC-CYRILLIC 这种通用的字符编码别名。
附录:http 抓包工具 和 测试网页代码
1、http抓包工具fiddler2
2、测试网页代码下载
GBK编码的文件:
<!DOCTYPE html>
<html>
<head>
<title>gb2312网页测试get提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=gb2312">
</head>
<body>
<center>
<form action="gbk-response/春节" method="get">
<p>用户名:<input type="text" name="name"/></p>
<p>密码:<input type="password" name="pwd"/></p>
<input type="submit" value="登录">
</form>
</center>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>gb2312网页测试get提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=gb2312">
</head>
<body>
<center>
<form action="gbk-response/春节" method="post">
<p>用户名:<input type="text" name="name"/></p>
<p>密码:<input type="password" name="pwd"/></p>
<input type="submit" value="登录">
</form>
</center>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>gb2312网页测试get提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=gb2312">
</head>
<body>
<center>
gb2312 响应页
</center>
</body>
</html>
UTF-8编码的文件:
<!DOCTYPE html>
<html>
<head>
<title>utf-8网页测试get提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
</head>
<body>
<center>
<form action="utf-8-response/春节" method="get">
<p>用户名:<input type="text" name="name"/></p>
<p>密码:<input type="password" name="pwd"/></p>
<input type="submit" value="登录">
</form>
</center>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>utf-8网页测试post提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
</head>
<body>
<center>
<form action="utf-8-response/春节" method="post">
<p>用户名:<input type="text" name="name"/></p>
<p>密码:<input type="password" name="pwd"/></p>
<input type="submit" value="登录">
</form>
</center>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<title>utf-8网页测试get提交数据方法</title>
<meta http-equiv="content-type" content="text/html;charset=utf-8">
</head>
<body>
<center>
utf-8 响应页
</center>
</body>
</html>
查看 网页的请求和响应,可以用 fiddler2 或者 浏览器开发者工具 –> network –>网页–>headers
参考:
http://www.w3help.org/zh-cn/causes/HR9001
https://blog.csdn.net/xiaokuikey/article/details/50517015
http://aub.iteye.com/blog/763117
https://www.cnblogs.com/JemBai/archive/2010/11/10/1873764.html
http://www.ruanyifeng.com/blog/2010/02/url_encoding.html
http://kaozjlin.iteye.com/blog/1038802
https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/index.html
 用notepad++ 查看十六进制代码如下:
用notepad++ 查看十六进制代码如下: