以前一直有个疑惑,为什么我创建的controller中注入的service类有时候是代理类,有时候是普通javabean,当时能力不够,现在已经有了点经验就大胆跟了跟源码,看看到底咋回事。
首先看看问题现象:
a1:service是代理类,并且是CGLIB类型代理 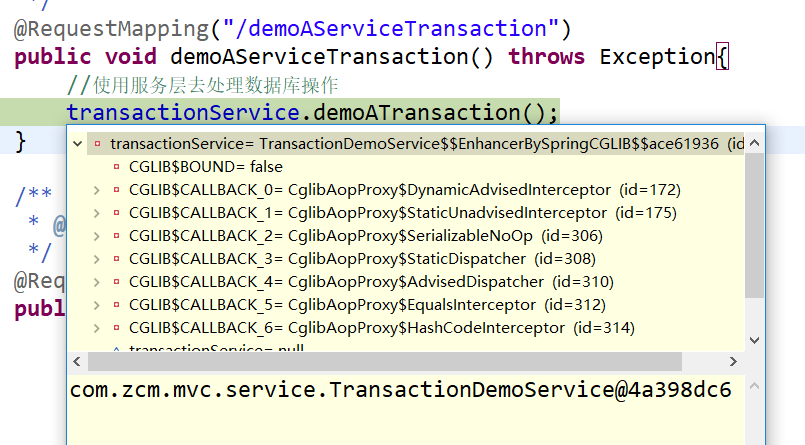
a2:service是代理类,并且是jdk 动态代理
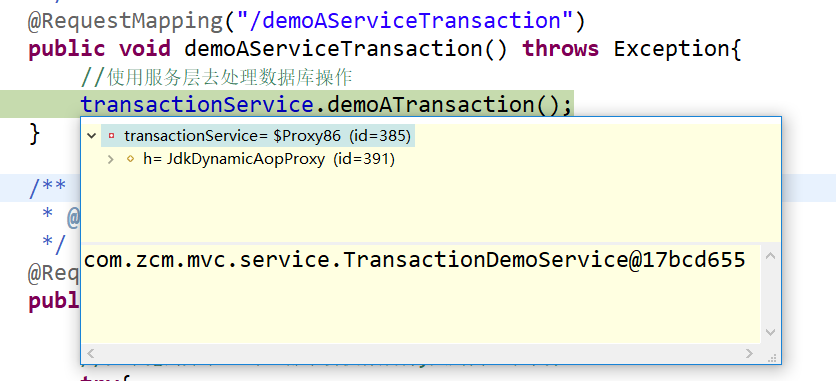
b:serivce不是代理类,而是普通类
问题分析
我对service类进行了以下的测试:(前提开启事务注解<tx:annotation-driven/>)
1)service方法添加@Transactional注解或者加入其它的aop拦截配置,没有实现任何接口。 对应问题现状 a1
2)service方法添加@Transactional注解或者加入其它的aop拦截配置,实现了接口。 对应问题现状a2
3)serice方法没有添加@Transactional注解或者其它的aop拦截配置。 对应问题现状b
看来出现这种问题的原因就是spring的问题,因为这个类是它创建的,这就需要我们来看下spring创建bean的代码,由于spring太庞大了
我们只看最关键的部分,在创建bean是都会调用getBean()方法,
@SuppressWarnings("unchecked")
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
return createBean(beanName, mbd, args);
}
经过不断的流转会进入AbstractAutowireCapableBeanFactory的createBean方法
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
try {
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) {
// A previously detected exception with proper bean creation context already,
// or illegal singleton state to be communicated up to DefaultSingletonBeanRegistry.
throw ex;
}
}
然后调用doCreateBean方法
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}return exposedObject;
}
然后进入核心的createBeanInstance方法,省去了不相关方法
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {// No special handling: simply use no-arg constructor.
return instantiateBean(beanName, mbd);
}
然后调用instantiateBean进行bea的实例化
protected BeanWrapper instantiateBean(final String beanName, final RootBeanDefinition mbd) {
try {
Object beanInstance;
final BeanFactory parent = this;
if (System.getSecurityManager() != null) {
beanInstance = AccessController.doPrivileged((PrivilegedAction<Object>) () ->
getInstantiationStrategy().instantiate(mbd, beanName, parent),
getAccessControlContext());
}
else {
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
实例化时会调用SimpleInstantiationStrategy的instantiate方法
@Override
public Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner) {
// Don't override the class with CGLIB if no overrides.
if (!bd.hasMethodOverrides()) {
Constructor<?> constructorToUse;
synchronized (bd.constructorArgumentLock) {
constructorToUse = (Constructor<?>) bd.resolvedConstructorOrFactoryMethod;
if (constructorToUse == null) {
final Class<?> clazz = bd.getBeanClass();
if (clazz.isInterface()) {
throw new BeanInstantiationException(clazz, "Specified class is an interface");
}
try {
if (System.getSecurityManager() != null) {
constructorToUse = AccessController.doPrivileged(
(PrivilegedExceptionAction<Constructor<?>>) clazz::getDeclaredConstructor);
}
else {
constructorToUse = clazz.getDeclaredConstructor();
}
bd.resolvedConstructorOrFactoryMethod = constructorToUse;
}
catch (Throwable ex) {
throw new BeanInstantiationException(clazz, "No default constructor found", ex);
}
}
}
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
通过上面的代码分析,如果Bean定义中没有方法覆盖,就使用JDK的反射机制进行实例化,否则,使用CGLIB进行实例化。
1、通过CGLIB的方式instantiateWithMethodInjection(bd, beanName, owner)
2、或者java的反射方式BeanUtils.instantiateClass(constructorToUse)
实例化一个bean
这是时候都是一个纯洁无瑕的javabean,那每个bean的额外加工,例如为某个bean添加事务支持,添加aop配置,还有就是将springmvc的controller进行url和handler的映射,等等这些都是在spring的扩展点完成的,回到
上面的doCreateBean方法,执行完实例化bean后执行
1、populateBean(beanName, mbd, instanceWrapper);
其中的populateBean是为了给生成的bean装配属性,
2、initializeBean(beanName, exposedObject, mbd);
这不是我们这次讨论的重点,关键是initializebean方法 ,为了配置bean的拓展方法 aop 事务等
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
invokeAwareMethods(beanName, bean);
return null;
}, getAccessControlContext());
}
else {
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
这个方法就是对生成的bean进行一些扩展处理,主要就是这个方法会调用我们自定义的扩展点
applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
Object current = beanProcessor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
可以看到这里是获取所有的beanProcessor,调用postProcessAfterInitialization方法,我们要关注是的一个叫InfrastructureAdvisorAutoProxyCreator的扩展类。
/**
* Auto-proxy creator that considers infrastructure Advisor beans only,
* ignoring any application-defined Advisors.
*
* @author Juergen Hoeller
* @since 2.0.7
*/
@SuppressWarnings("serial")
public class InfrastructureAdvisorAutoProxyCreator extends AbstractAdvisorAutoProxyCreator {}
看下这个类的注释可以发现这个类是为配置了aop配置(包括注解和xml配置两种方式)的类,生成代理类。
核心方法是下面这个方法wrapIfNecessary方法。
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
if (beanName != null && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
Object proxy = createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
下面解析下这个函数
首先看下getAdvicesAndAdvisorsForBean这个方法:名字很明显用来获取当前bean的advisor和adices的,这些都是生成代理类时需要的信息。
protected Object[] getAdvicesAndAdvisorsForBean(Class<?> beanClass, String beanName, TargetSource targetSource) {
List<Advisor> advisors = findEligibleAdvisors(beanClass, beanName);
if (advisors.isEmpty()) {
return DO_NOT_PROXY;
}
return advisors.toArray();
}
然后调用findEligibleAdvisors,获取配置的advisor信息
protected List<Advisor> findEligibleAdvisors(Class<?> beanClass, String beanName) {
List<Advisor> candidateAdvisors = findCandidateAdvisors();
List<Advisor> eligibleAdvisors = findAdvisorsThatCanApply(candidateAdvisors, beanClass, beanName);
extendAdvisors(eligibleAdvisors);
if (!eligibleAdvisors.isEmpty()) {
eligibleAdvisors = sortAdvisors(eligibleAdvisors);
}
return eligibleAdvisors;
}
来看下findCandidateAdvisors方法,最终调用BeanFactoryAdvisorRetrievalHelper.findAdvisorBeans
public List<Advisor> findAdvisorBeans() {
// Determine list of advisor bean names, if not cached already.
String[] advisorNames = null;
synchronized (this) {
advisorNames = this.cachedAdvisorBeanNames;
if (advisorNames == null) {
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the auto-proxy creator apply to them!
advisorNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this.beanFactory, Advisor.class, true, false);
this.cachedAdvisorBeanNames = advisorNames;
}
}
if (advisorNames.length == 0) {
return new LinkedList<>();
}
List<Advisor> advisors = new LinkedList<>();
for (String name : advisorNames) {
if (isEligibleBean(name)) {
if (this.beanFactory.isCurrentlyInCreation(name)) {
}
else {
try {
advisors.add(this.beanFactory.getBean(name, Advisor.class));
}
catch (BeanCreationException ex) {
throw ex;
}
}
}
}
return advisors;
}
1)首先获取spring管理的Advisor类型的类名称。
2)通过beanFactory获取该bean对应的实体类,并装入advisors。
生成的这个advisor可是相当复杂,这里我们以事务advisor为例说明
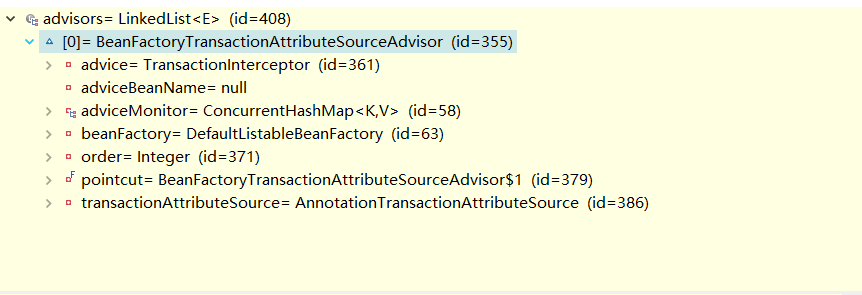
可以看到这个advisor包含了advice(aop中的通知),pointcut(aop中的切入点),

advice是TransactionInterceptor,这个通知是用来管理spring的事务的可以看到包含事务的管理器等管理事务的属性,具体的方法见TransactionAspectSupport.invokeWithinTransaction
pointcut是TransactionAttributeSourcePointcut,
public boolean matches(Method method, @Nullable Class<?> targetClass) {
if (targetClass != null && TransactionalProxy.class.isAssignableFrom(targetClass)) {
return false;
}
TransactionAttributeSource tas = getTransactionAttributeSource();
return (tas == null || tas.getTransactionAttribute(method, targetClass) != null);
}
这个是pointcut的核心方法,用来匹配某个类是否符合事务管理的aop拦截要求。
ok,回到之前的wrapIfNecessary方法
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
if (beanName != null && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
Object proxy = createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
我们之前分析道getAdvicesAndAdvisorsForBean方法,可以看到如果得到的结果是DO_NOT_PROXY,就会将这个bean直接返回,
如果不是DO_NOT_PROXY,(其实DO_NOT_PROXY就是null,但是使用DO_NOT_PROXY会使得代码逻辑更加清晰),就会执行
createProxy方法,创建一个代理类,然后返回一个代理类,ok,现在我们就清楚了问题分析中的 第3)和第 1) 2) 区别,那就是
service类是否配置了相关的aop拦截配置,无论是注解还是xml形式,目前我们还不清楚第1)和 第2)的区别,就是为什么有时候
生成jdk代理,有时候生成cglib代理,这就需要继续向下看creatProxy方法了,最终会进入一个DefaultAopProxyFactory的createAopProxy
方法:
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
return new ObjenesisCglibAopProxy(config);
}
else {
return new JdkDynamicAopProxy(config);
}
}
如果目标类是接口就一定会使用jdk代理,如果目标类没有可以代理的接口就一定会使用Cglib代理。
问题总结
这个问题我们现在知道了,那他有什么意义呢,换句话说,我们为什么要知道这个,即使不知道原理,我们也可以去搜搜去解决,在我看来
把他弄明白的过程学会了很多知识,而且我们如果在工作过程中遇到了需要扩展的地方,我们可以很容易的去解决。
最后欢迎大家在评论区留言,有什么想法说出来,共同进步。
来自:https://www.cnblogs.com/zcmzex/p/8822509.html
参考另一篇IOC源码理解分析:
总结:
//AbstractAutowireCapableBeanFactory创建Bean实例对象:
//AbstractAutowireCapableBeanFactory类实现了ObejctFactory接口,创建容器指定的Bean实例对象,同时还对创建的Bean实例对象进行初始化处理。
// 创建Bean实例对象 方法中 调用了 核心 三句话
protected Object createBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
//调用一 :createBeanInstance:生成Bean所包含的java对象实例。
instanceWrapper = createBeanInstance(beanName, mbd, args);
//调用二:populateBean :对Bean属性的依赖注入进行处理(解析bean的属性,并对bean的属性赋值[值注入])
populateBean(beanName, mbd, instanceWrapper);
//调用三:对 bean 的 扩展功能 进行配置 比如 aop ,事务。(可以 插入到任何操作 后)
// BeanPostProcessor是Bean后置处理器,用于监听容器触发的事件
exposedObject = initializeBean(beanName, exposedObject, mbd);
// 创建bean的 过程 都是 普通的 实例bean ,如果 是接口 就执行 不创建。
// 然后 bean 赋值 过程 没有变化,
// 到了 bean 拓展功能阶段,就看 有没有 代理 或者 接口问题了。比如 上面的 举例 明天写后续