一、HttpMessageConverter概述
HttpMessageConverter<T> 是 Spring3.0 新添加的一个接 口,负责将请求信息转换为一个对象(类型为 T),将对象( 类型为 T)输出为响应信息。
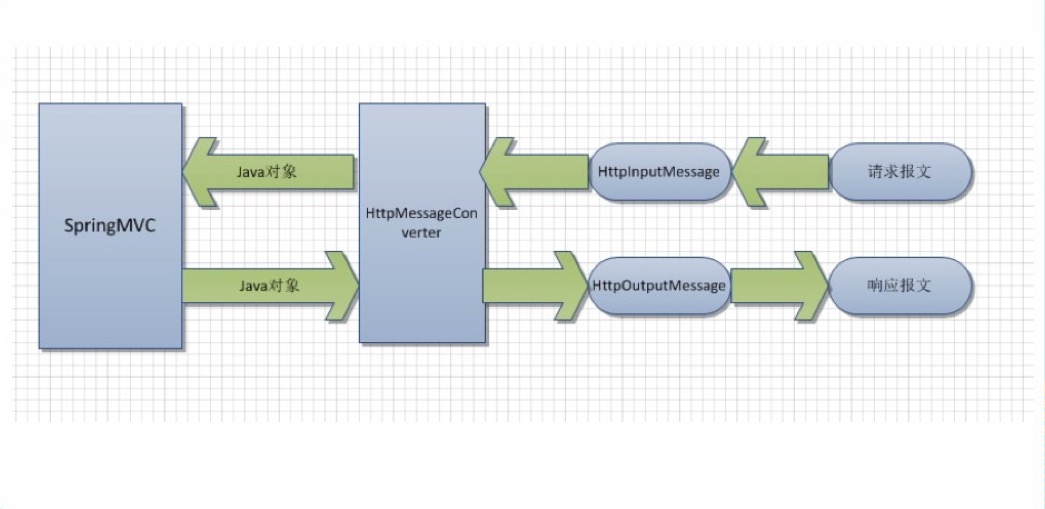
使用 HttpMessageConverter<T> 将请求信息转化并绑定到处理方法的入 参中或将响应结果转为对应类型的响应信息,Spring 提供了两种途径:
–使用 @RequestBody / @ResponseBody 对处理方法进行标注
–使用 HttpEntity<T> / ResponseEntity<T> 作为处理方法的入参或返回值
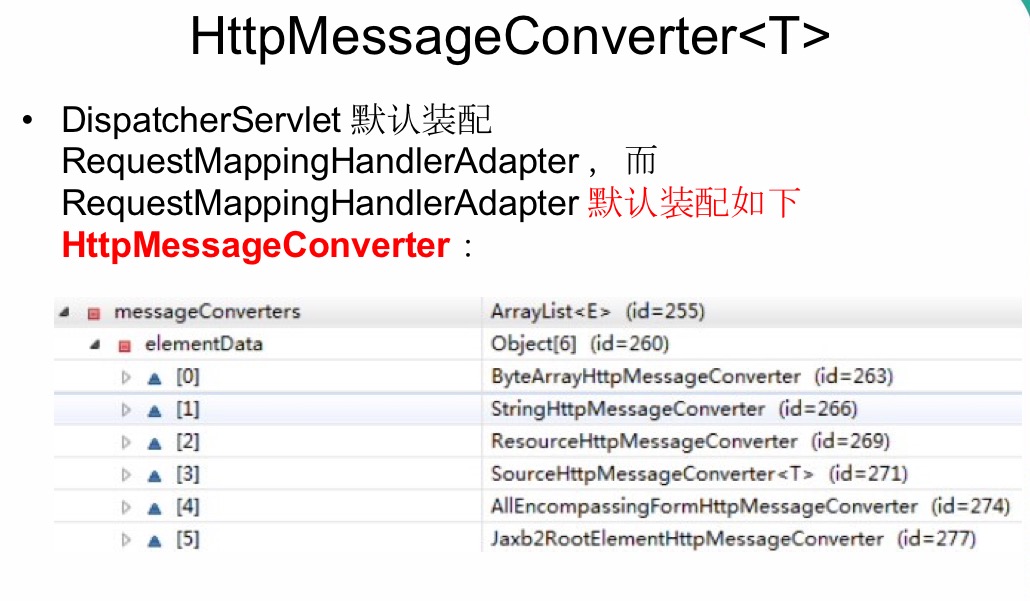
当控制器处理方法使用到 @RequestBody/@ResponseBody 或HttpEntity<T>/ResponseEntity<T> 时, Spring 首先根据请求头或响应头的Accept 属性选择匹配的 HttpMessageConverter, 进而根据参数类型或 泛型类型的过滤得到匹配的 HttpMessageConverter, 若找不到可用的HttpMessageConverter 将报错
- @RequestBody 和 @ResponseBody 不需要成对出现。
ajax发送和接收乱码问题:
因为HttpMessageConverter的几个实现类,都是先查询http请求头的编码方式,然后再解码的,如果没有指定就使用默认的编码方式。比如iso-8859-1。这样会使得中文乱码。
碰到使用ajax调用spring mvc时出现乱码,这里写一下解决方法。
一:ajax传入spring mvc时,@RequestBody出现乱码:
这是ajax调用时,传入data编码有误导致,通过以下方式解决(红色字体部分):
前台ajax调用代码:
$.ajax({
url : baseUrl + “/crlandIsp/commonInfoCreate/save.do”,
type : “POST”,
cache : false,
data : mdata,
contentType : “text/html;charset=UTF-8”,
dataType : “json”,
success : function(result) {
},
error : function(xhr, ajaxOptions, thrownError) {
}
});
二:spring mvc通过@ResponseBody返回时,ajax接收到乱码结果:
修改spring mvc controller代码(添加红色部分),指定响应头编码方式:
@RequestMapping(value = “/queryDetail”,produces = “text/html;charset=UTF-8”)
public @ResponseBody String save(@RequestBody String body) throws Exception {
try {
。。。。
}
方法二、修改全局的默认配置编码
<mvc:annotation-driven>
<mvc:message-converters register-defaults="true">
<bean class="org.springframework.http.converter.StringHttpMessageConverter">
<property name="supportedMediaTypes" value = "text/html;charset=UTF-8" />
</bean>
</mvc:message-converters>
</mvc:annotation-driven>
网上也有这种,但是你们是不是<mvc:annotation-driven>不能配置子集。
这里只要把你们的spring-mvc-.xsd改成4就可以在<mvc:annotation-driven>下配置了,如下图
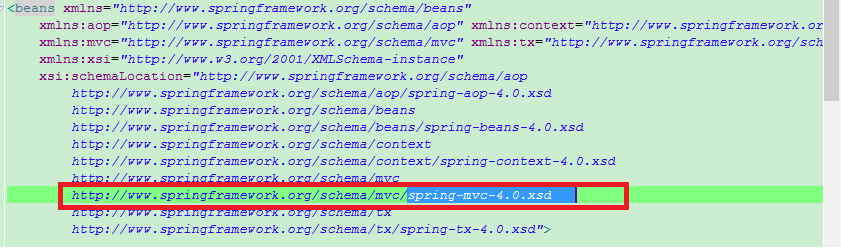
主要还是spring-mvc-4.0.xsd。改了之后再eclipse中按ALT+/就会出现如下提示
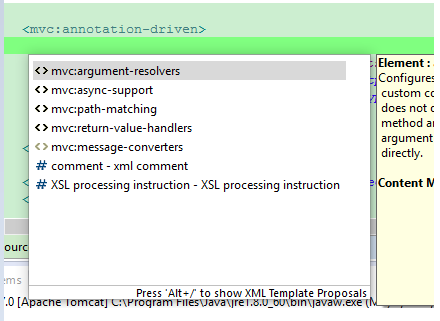
这边还要注意一点
<property name="supportedMediaTypes" value = "text/plain;charset=UTF-8" />
text/plain这个还是会中文乱码,用text/html就不会
二、HttpMessageConverter应用
1、测试请求体信息
(1)测试带上传文件
utf-8编码的文件:春节.txt
good春节OK
hello
文件二进制为:
676f 6f64 e698 a5e8 8a82 4f4b 0d0a 6865
6c6c 6f
(2)测试网页:
<form action="testRequestBody" method="post" enctype="multipart/form-data" accept-charset="gb2312">
File:<input type="file" name="name-file"/>
Desc:<input type="text" name="name-desc"/>
<input type="submit" name="name-submit" value="submit" />
</form>
(2)测试请求体的控制器:
@ResponseBody
@RequestMapping("/testRequestBody")
public String testHttpMessageConverter(@RequestBody String body){
System.out.println(body);
return "helloworld! " + new Date();
}
浏览器fiddler2抓包结果:
(将二进制流用gb2312解码的结果,很明显文件上传时传的是原始二进制流,原始信息是utf-8编码,上传时没有在重新经过编码,于是春节,二字的utf-8编码是 E6 98 A5 E8 8A 82 的二进制流,抓包解码时,将E6 98 A5 E8 8A 82用GB2312解码,于是出现乱码 鏄ヨ妭 ,至于表单中的其他信息 ,因为都采用了gb2312编码,所以解码时就正确了,不会出现乱码 )
POST http://192.168.1.131:8080/springmvc-2/testRequestBody HTTP/1.1
Host: 192.168.1.131:8080
Connection: keep-alive
Content-Length: 410
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://192.168.1.131:8080
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryrvTDZPfQOBKllDXv
Referer: http://192.168.1.131:8080/springmvc-2/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=5E065281AC2C661A0098111FB38F3745
------WebKitFormBoundaryrvTDZPfQOBKllDXv
Content-Disposition: form-data; name="name-file"; filename="春节.txt"
Content-Type: text/plain
good鏄ヨ妭OK
hello
------WebKitFormBoundaryrvTDZPfQOBKllDXv
Content-Disposition: form-data; name="name-desc"
春节
------WebKitFormBoundaryrvTDZPfQOBKllDXv
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundaryrvTDZPfQOBKllDXv--
服务器控制台输出结果:【输出的是请求体】
------WebKitFormBoundaryrvTDZPfQOBKllDXv
Content-Disposition: form-data; name="name-file"; filename="´º½Ú.txt"
Content-Type: text/plain
goodæ¥èOK
hello
------WebKitFormBoundaryrvTDZPfQOBKllDXv
Content-Disposition: form-data; name="name-desc"
´º½Ú
------WebKitFormBoundaryrvTDZPfQOBKllDXv
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundaryrvTDZPfQOBKllDXv--
特别备注:控制台返回的请求体中:
##### 针对 filename="´º½Ú.txt" ,
##### 这个 ´º½Ú 是浏览器 用gb2312编码 春节 两字成 B4 BA BD DA 的二进制流,放入请求体中
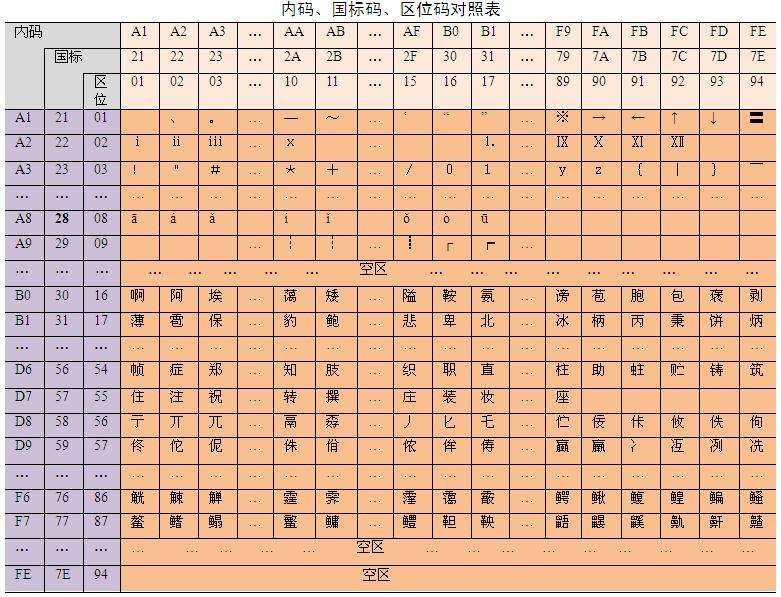
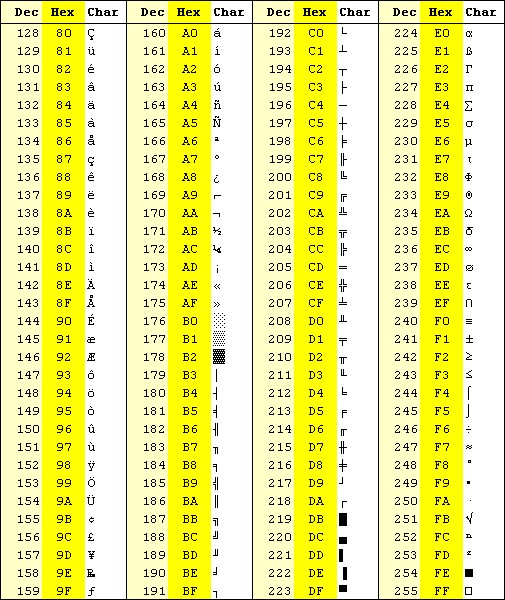
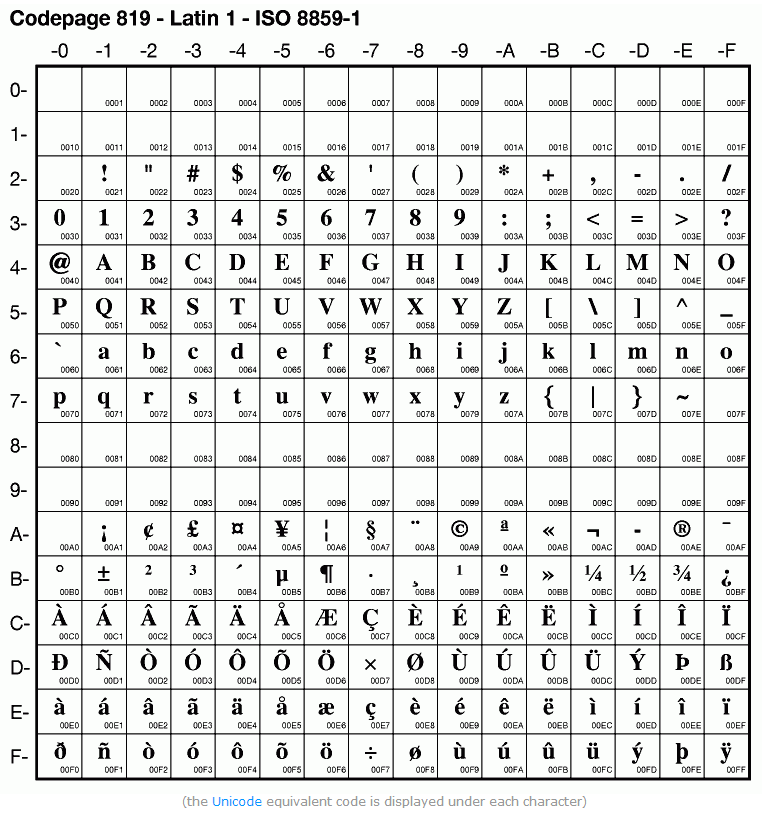
##### 解码时 springmvc 查看http头,发现没有编码指明,于是默认用 iso-8859-1解码 造成乱码
Content-Disposition: form-data; name="name-file"; filename="´º½Ú.txt"
##### 下面第三行 也是同样的 原因
Content-Disposition: form-data; name="name-desc"
´º½Ú
##### 总结来说,multipart/form-data 编码的表单,表单中信息都是按 表单规定的编码方式,
##### 直接编码成 二进制流。然后存放到 请求体中。而表单其他自动生成的信息,都是ASCII编码
##### 其实也可以说是按照 表单默认 的编码方式,因为http 用到的编码都是 ASCII码的扩展码,都兼容支持ASCII码
##### 当然 文件上传时 没有进行编码,直接是原始文件的二进制流加入到 请求体中 比如下面的文件信息:
Content-Type: text/plain
goodæ¥èOK
hello
------WebKitFormBoundaryrvTDZPfQOBKllDXv
##### 上面的例子中:原始文件信息 已经说过了 是用utf-8编码 成二进制流,utf-8兼容ASCII码,
##### 当 springmvc 接收请求体时,因为发现请求头中没有编码信息 ,所以采用默认的iso-8859-1解码,这个兼容ASCII码
##### 所以 英文字母能够正常解码 ,中文 春节 二字,一开始utf-8编码成 E6 98 A5 E8 8A 82 的二进制流,
##### 后来解码时 ,用ios-8859-1将这些二进制流错误的解码了,导致出现乱码 æ¥è
=========================================================
如果将表单设置成utf-8编码,效果就不一样了。
<form action="testRequestBody" method="post" enctype="multipart/form-data" accept-charset="UTF-8">
File:<input type="file" name="name-file"/>
Desc:<input type="text" name="name-desc"/>
<input type="submit" name="name-submit" value="submit" />
</form>
用utf-8解码抓包时的二进制流:
POST http://192.168.1.131:8080/springmvc-2/testRequestBody HTTP/1.1
Host: 192.168.1.131:8080
Connection: keep-alive
Content-Length: 414
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Origin: http://192.168.1.131:8080
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundarySIE2A85QOHmfv0rl
Referer: http://192.168.1.131:8080/springmvc-2/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=69D0B1B2F9AAE721AED15F660424C708
------WebKitFormBoundarySIE2A85QOHmfv0rl
Content-Disposition: form-data; name="name-file"; filename="春节.txt"
Content-Type: text/plain
good春节OK
hello
------WebKitFormBoundarySIE2A85QOHmfv0rl
Content-Disposition: form-data; name="name-desc"
春节
------WebKitFormBoundarySIE2A85QOHmfv0rl
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundarySIE2A85QOHmfv0rl--
查看服务器控制台输出结果:
所有乱码 æ¥è 都是因为春节的utf-8 编码成二进制流 E6 98 A5 E8 8A 82
后来用iso-8859-1 解码 E6 98 A5 E8 8A 82 时,出现乱码 æ¥è
------WebKitFormBoundarySIE2A85QOHmfv0rl
Content-Disposition: form-data; name="name-file"; filename="æ¥è.txt"
Content-Type: text/plain
goodæ¥èOK
hello
------WebKitFormBoundarySIE2A85QOHmfv0rl
Content-Disposition: form-data; name="name-desc"
æ¥è
------WebKitFormBoundarySIE2A85QOHmfv0rl
Content-Disposition: form-data; name="name-submit"
submit
------WebKitFormBoundarySIE2A85QOHmfv0rl--
为什么,控制台打印出来的是乱码呢?
debug解析过程:
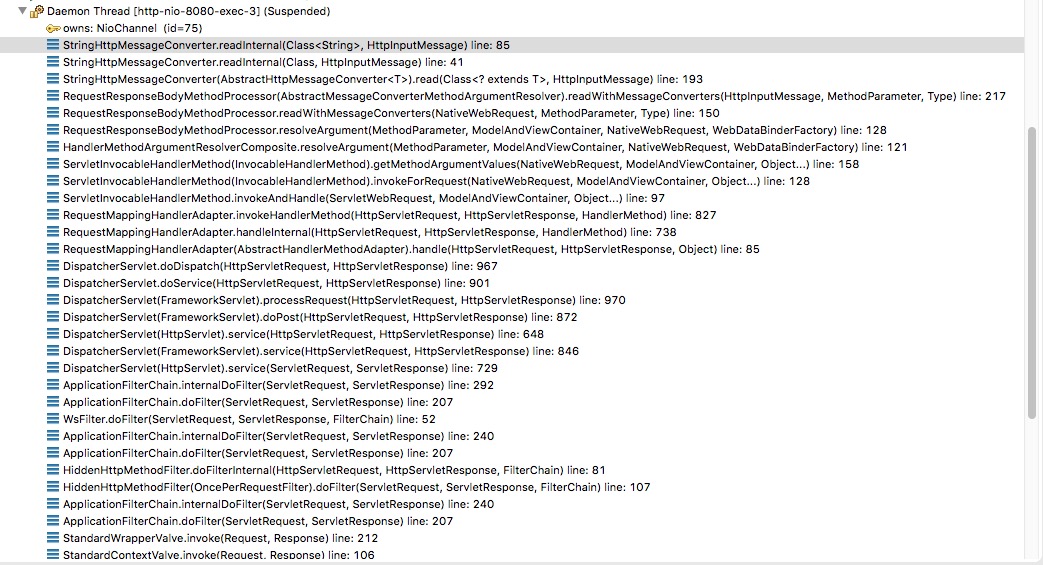
核心靠AbstractHttpMessageConverter.java 解析body
解码时,首先看请求头的编码,如果没有,则默认iso-8859-1编码。
//类方法 有删减
public class StringHttpMessageConverter extends AbstractHttpMessageConverter<String> {
public static final Charset DEFAULT_CHARSET = Charset.forName("ISO-8859-1");
private volatile List<Charset> availableCharsets;
private boolean writeAcceptCharset = true;
/**
* A default constructor that uses {@code "ISO-8859-1"} as the default charset.
* @see #StringHttpMessageConverter(Charset)
*/
public StringHttpMessageConverter() {
this(DEFAULT_CHARSET);
}
/**
* A constructor accepting a default charset to use if the requested content
* type does not specify one.
*/
public StringHttpMessageConverter(Charset defaultCharset) {
super(defaultCharset, MediaType.TEXT_PLAIN, MediaType.ALL);
}
/**
* Indicates whether the {@code Accept-Charset} should be written to any outgoing request.
* <p>Default is {@code true}.
*/
public void setWriteAcceptCharset(boolean writeAcceptCharset) {
this.writeAcceptCharset = writeAcceptCharset;
}
@Override
protected String readInternal(Class<? extends String> clazz, HttpInputMessage inputMessage) throws IOException {
Charset charset = getContentTypeCharset(inputMessage.getHeaders().getContentType());
return StreamUtils.copyToString(inputMessage.getBody(), charset);
}
@Override
protected void writeInternal(String str, HttpOutputMessage outputMessage) throws IOException {
if (this.writeAcceptCharset) {
outputMessage.getHeaders().setAcceptCharset(getAcceptedCharsets());
}
Charset charset = getContentTypeCharset(outputMessage.getHeaders().getContentType());
StreamUtils.copy(str, charset, outputMessage.getBody());
}
}
所以,解决方法也好办了:
1.客户的发送方法稍微改一下,这个方式是最好的:
connection.setRequestProperty("content-type", "text/html;charset=GBk");
2.如果发送方无论如何都没法改,只能服务器端处理的时候,要么所有接收到的数据都 new String(data.getByte(“iso-8859-1″),”GBK”),要么直接自定义StringHttpConverter,将readInternal方法中的charset获取改为不先从请求头中读取,直接硬编码为GBK(当然这样做的后果就是只能接收GBK的数据了).【好像不能自定义,不过上文提到了可以转发配置中配置,修改StringHttpConverter的默认编码值】
2、文件下载
只需要在控制器中,编辑 ResponseEntity<byte[]>就行了。
@RequestMapping("/testResponseEntity")
public ResponseEntity<byte[]> testResponseEntity(HttpSession session) throws IOException{
byte [] body = null;
ServletContext servletContext = session.getServletContext();
InputStream in = servletContext.getResourceAsStream("/files/abc.txt");
body = new byte[in.available()];
in.read(body);
HttpHeaders headers = new HttpHeaders();
headers.add("Content-Disposition", "attachment;filename=abc.txt");
HttpStatus statusCode = HttpStatus.OK;
ResponseEntity<byte[]> response = new ResponseEntity<byte[]>(body, headers, statusCode);
return response;
}
3、返回json
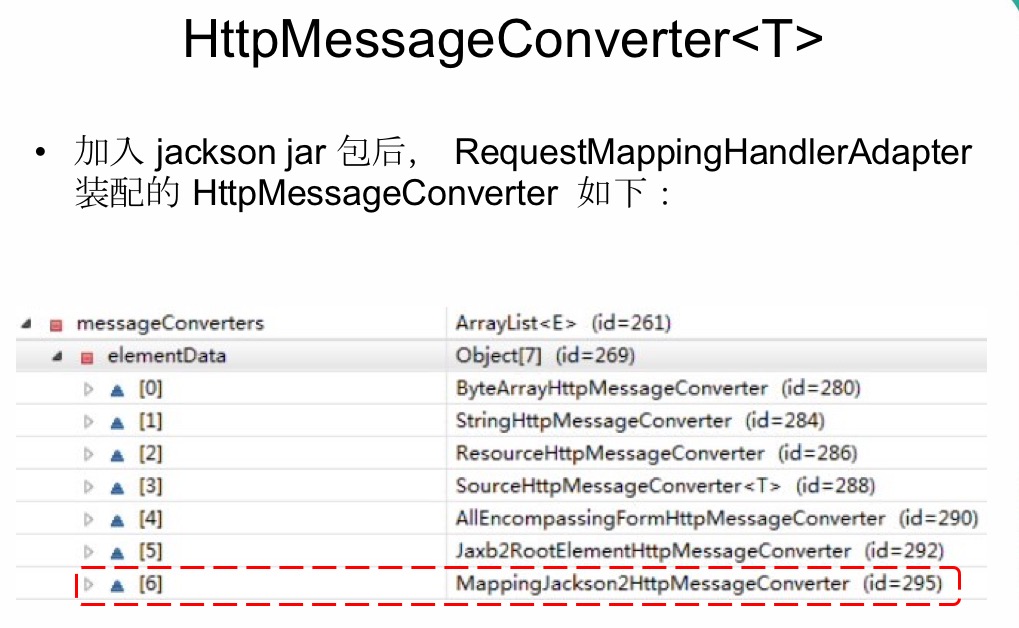
添加jackson jar包,编写控制器。【如果有中文的json,】
@ResponseBody
@RequestMapping("/testJson")
public Collection<Employee> testJson(){
return employeeDao.getAll();
}
测试链接:http://localhost:8080/springmvc-2/testJson
参考:
测试 request body 问题
https://www.cnblogs.com/chyu/p/5517788.html
https://blog.csdn.net/u013239111/article/details/51347949
http://blog.sina.com.cn/s/blog_b1f34f990102vcm4.html