eclipse 新建项目后,点击项目 右键 properties ,选择 builders ;
我们可以看到:eclipse 项目的构建方法有三种:
1、默认构建方式: Java Builder
2、maven 构建方式:特点 有 pom.xml 配置文件
3、ant 构建方式:特点 有 build.xml 配置文件
当你年老时,你是否常常想,要是年轻时多努力下该好。
eclipse 新建项目后,点击项目 右键 properties ,选择 builders ;
我们可以看到:eclipse 项目的构建方法有三种:
1、默认构建方式: Java Builder
2、maven 构建方式:特点 有 pom.xml 配置文件
3、ant 构建方式:特点 有 build.xml 配置文件
对于mysql数据库的乱码问题,有两种情况:
1. mysql数据库编码问题(建库时设定)。
2. 连接mysql数据库的url编码设置问题。
对于第一个问题,目前个人发现只能通过重新建库解决,建库的时候,选择UTF-8字符集。我试过修改现有数据库字符集为UFT-8,但是根本不起作用,插入的中文仍然乱码(中文显示成:???)。重建库时选择字符集为UTF-8之后,中文正常显示了。
补充:
第一个问题,可以单独的修改表的字符集,更可以单独的修改字段的字符集。 ALTER TABLE tbl_name DEFAULT CHARACTER SET character_name ALTER TABLE tbl_name CHANGE c_name c_name CHARACTER SET character_name
对于第二个问题,是这样的情况:我建库时设置了数据库默认字符集为UTF-8,通过mysql workbench直接插入中文显示完全正常。但是使用mybaits插入数据时,中文显示成了”???”这样的乱码。但从数据库获取的中文不会乱码。跟踪数据库操作,SQL语句中的中文还是显示正常的,但是插入到mysql数据库后就乱码了,于是判断可能是数据库连接的问题。后来在网上找了下资料,发现确实可以为mysql数据库的连接字符串设置编码方式,如下:
jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8
添加了useUnicode=true&characterEncoding=utf8参数之后,插入中文就正常了。
添加的作用是:指定字符的编码、解码格式。
例如:假设mysql数据库用的是GBK编码(也可能是其它,例如Ubuntu下就是latin1),而项目数据库用的是utf-8编码。这时候如果添加了useUnicode=true&characterEncoding=UTF-8 ,那么作用有如下两个方面:
1. 存数据时:
数据库在存放项目数据的时候会先用UTF-8格式将数据解码成字节码,然后再将解码后的字节码重新使用GBK编码存放到数据库中。
2.取数据时:
在从数据库中取数据的时候,数据库会先将数据库中的数据按GBK格式解码成字节码,然后再将解码后的字节码重新按UTF-8格式编码数据,最后再将数据返回给客户端。
注意:在xml配置文件中配置数据库utl时,要使用&的转义字符也就是&
例如:<property name="url" value="jdbc:mysql://localhost:3306/email?useUnicode=true&characterEncoding=UTF-8" />
| 显示结果 | 说明 | Entity Name | Entity Number |
| 显示一个空格 | |   | |
| < | 小于 | < | < |
| > | 大于 | > | > |
| & | &符号 | & | & |
| “ | 双引号 | " | " |
| 显示结果 | 说明 | Entity Name | Entity Number |
| © | 版权 | © | © |
| ® | 注册商标 | ® | ® |
| × | 乘号 | × | × |
| ÷ | 除号 | ÷ | ÷ |
| Properties and Descriptions |
|---|
| useUnicode
Should the driver use Unicode character encodings when handling strings? Should only be used when the driver can’t determine the character set mapping, or you are trying to ‘force’ the driver to use a character set that MySQL either doesn’t natively support (such as UTF-8), true/false, defaults to ‘true’ Default: true Since version: 1.1g |
| characterEncoding
If ‘useUnicode’ is set to true, what character encoding should the driver use when dealing with strings? (defaults is to ‘autodetect’) Since version: 1.1g |
参考:
https://blog.csdn.net/zht666/article/details/8955952
https://blog.csdn.net/afgasdg/article/details/6941712
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-reference-configuration-properties.html
Log4j是Apache的一个开源项目,通过使用Log4j,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
所以简单的来说,Log4j可以理解为一个通过配置文件进行配置的日志操作工具。
log4j框架 需要 log4j.jar 包 和 log4j配置文件。log4j 1.x 版 和log4j 2.x 代码调用和配置文件 都不一样了要注意。本文讲的 代码调用和 文件配置,都是针对1.x 版本来说的。【不是很确定,但应该是1.x 版本】
(1)log4j.properties
(2)log4j.xml
log4j文件名和文件路径都可以随意设置,只要在代码中指定好配置文件就行,这样就能加载log4j框架了。【如果配置文件取名为log4j.xml或者log4j.properties,且文件放在根目录(就是可执行二进制class文件的根目录),那么log4j会自动加载配置文件,无需写代码】
#配置根Logger log4j.rootLogger = [level] , appenderName1 , appenderName2 , … #配置日志信息输出目的地Appender log4j.appender.appenderName = fully.qualified.name.of.appender.class log4j.appender.appenderName.option1 = value1 … log4j.appender.appenderName.optionN = valueN #配置日志信息的格式(布局) log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class log4j.appender.appenderName.layout.option1 = value1 … log4j.appender.appenderName.layout.optionN = valueN
log4j.rootLogger=INFO,Console,File
#控制台日志
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%p][%t][%d{yyyy-MM-dd HH\:mm\:ss}][%C] - %m%n
#普通文件日志
log4j.appender.File=org.apache.log4j.RollingFileAppender
log4j.appender.File.File=logs/ssm.log
log4j.appender.File.MaxFileSize=10MB
#输出日志,如果换成DEBUG表示输出DEBUG以上级别日志
log4j.appender.File.Threshold=ALL
log4j.appender.File.layout=org.apache.log4j.PatternLayout
log4j.appender.File.layout.ConversionPattern=[%p][%t][%d{yyyy-MM-dd HH\:mm\:ss}][%C] - %m%n
首先对于基本格式中的配置根Logger这部分来说
log4j.rootLogger = [level] , appenderName1 , appenderName2 , …
我们的log4j.properties文件相应内容如下:
log4j.rootLogger=INFO,Console,File
其中[level]是日志输出级别分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL或者您定义的级别。Log4j建议只使用四个级别,优先级从高到低分别是ERROR、WARN、INFO、DEBUG。通过在这里定义的级别,您可以控制到应用程序中相应级别的日志信息的开关。比如在这里定义了INFO级别,则应用程序中所有DEBUG级别的日志信息将不被打印出来。
appenderName:就是指定日志信息输出到哪个地方。您可以同时指定多个输出目的地。例如:log4j.rootLogger=INFO,Console,File 配置了2个输出地方,这个名字可以任意(如上面的Console和File),但必须与我们在后面进行的设置名字对应。例如:log4j.appender.Console中的Console 和 log4j.appender.File中的File就是对应之前写的名称。
在看接下来配置日志信息输出目的地Appender和配置日志信息的格式(布局)的部分。
Appender 为日志输出目的地,Log4j提供的appender有以下几种:
org.apache.log4j.ConsoleAppender(控制台), org.apache.log4j.FileAppender(文件), org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件), org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件), org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
Layout为日志输出格式,Log4j提供的layout有以下几种:
org.apache.log4j.HTMLLayout(以HTML表格形式布局), org.apache.log4j.PatternLayout(可以灵活地指定布局模式), org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串), org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
那么,我们log4j.properties的内容是否不难理解了。
#控制台日志
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%p][%t][%d{yyyy-MM-dd HH\:mm\:ss}][%C] - %m%n
appenderName为Console的日志输出目的地为控制台,采用了可以灵活地指定布局模式的格式。
至于其他的格式可以参考文章 配置Log4j
java代码运行时,会在class文件的根目录(包名不是根目录,是class文件的一部分)寻找加载log4j.xml或者log4j.properties。一旦加载完成,就开启log4j功能了。
本地项目: 初始化log4j的日志配置,指定到src目录下(建议用2)
//1. 本地项目-属性文件配置
PropertyConfigurator.configure("src/config/log4j.properties");
//2. 本地项目-xml文件配置
DOMConfigurator.configure("src/config/log4j.xml");
//3. 本地项目-默认配置
BasicConfigurator.configure();
特别注意:
(1)、DOMConfigurator 和 PropertyConfigurator是用来加载不同类型的配置文件,别搞错了。
(2)、configure方法:里面的参数 如果是 文件夹 开头,则代表相对目录,这个相对目录是相对工程文件目录来说的,如果是 / 开头,代表根目录。获取路径可以参考java常识-获取路径的方法及注意点
(3)、当配置文件加载好后,log4j框架就已经在运行了,就已经在输出log日志了。
这是一个非常关键的问题,之前讲道我们采用配置Log4j来完成日志部分的操作,但是SSM框架是如何知道这个配置文件的存在并让它起作用呢?
java代码运行时,会在class文件的根目录(包名不是根目录,是class文件的一部分)寻找加载log4j.xml或者log4j.properties。一旦加载完成,就开启log4j功能了。
如果配置文件:改成6log4j.xml ,则在web 可以进行如下配置:
<context-param>
<param-name>log4jConfigLocation</param-name>
<param-value>classpath:6log4j.xml</param-value>
</context-param>
<listener>
<listener-class>
org.springframework.web.util.Log4jConfigListener
</listener-class>
</listener>
当然也可以额外添加一个 配置:【不添加也没有关系】
<context-param>
<param-name>log4jRefreshInterval</param-name>
<param-value>60000</param-value>
</context-param>
至于上述 log4j的配置,最好放在 org.springframework.web.context.ContextLoader前面。如果放在它后面,那么在加载org.springframework.web.context.ContextLoader这个listener的时会找不到log4j的配置文件,变会出现:
log4j:WARN No appenders could be found for logger (org.springframework.web.context.ContextLoader). log4j:WARN Please initialize the log4j system properly.
到了后面:又会继续读取 web.xml 时,又会加载 log4j 的配置了。此时,网站已具有log4j的功能。
本地项目: 初始化log4j的日志配置,指定到src目录下(建议用2)
//1. 本地项目-属性文件配置
PropertyConfigurator.configure("src/config/log4j.properties");
//2. 本地项目-xml文件配置
DOMConfigurator.configure("src/config/log4j.xml");
//3. 本地项目-默认配置
BasicConfigurator.configure();
特别注意:
(1)、DOMConfigurator 和 PropertyConfigurator是用来加载不同类型的配置文件,别搞错了。
(2)、configure方法:里面的参数 如果是 文件夹 开头,则代表相对目录,这个相对目录是相对工程文件目录来说的, 如果是 / 开头,代表根目录。获取路径可以参考java常识-获取路径的方法及注意点
(3)、当配置文件加载好后,log4j框架就已经在运行了,就已经在输出log日志了。
当我们想要打印日志时,可以直接参考下面代码:
Logger logger = Logger.getLogger(JunitTest.class);
// 记录debug级别的信息
logger.error("This is debug message.");
Java Builder 构建器
package com.test.springmvc.test;
import static org.junit.Assert.*;
import org.apache.log4j.BasicConfigurator;
import org.apache.log4j.Logger;
import org.apache.log4j.PropertyConfigurator;
import org.apache.log4j.xml.DOMConfigurator;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import com.test.springmvc.dao.EmployeeMapper;
public class JBuilderTest {
@Test
public void test() {
/*****
特别注意:
(1)、DOMConfigurator 和 PropertyConfigurator是用来加载不同类型的配置文件,别搞错了。
(2)、configure方法:里面的参数 如果是 / 开头,代表根目录,如果是 文件夹开头,则代表相对目录,这个相对目录是相对工程文件目录来说的。
(3)、当配置文件加载好后,log4j框架就已经在运行了,就已经在输出log日志了。
* ***/
// BasicConfigurator.configure();
// DOMConfigurator.configure("classpath:6log4j.xml"); //前面这个方法不行 ,后面这个方法也不行 "/classpath:6log4j.xml"
// DOMConfigurator.configure("conf/6log4j.xml");
DOMConfigurator.configure(Thread.currentThread().getContextClassLoader().getResource(".").getPath()+"6log4j.xml");
//OK DOMConfigurator.configure(Thread.currentThread().getContextClassLoader().getResource(".").getPath()+"test.log/log4j.xml");
// Logger logger = Logger.getLogger(JunitTest.class);
// // 记录debug级别的信息
// logger.error("This is debug message.");
System.out.println(Thread.currentThread().getContextClassLoader().getResource(".").getPath());
//1、创建SpringIOC容器
ApplicationContext ioc = new ClassPathXmlApplicationContext("applicationContext.xml");
//2、从容器中获取mapper
EmployeeMapper bean = ioc.getBean(EmployeeMapper.class);
System.out.println(bean.getEmps());
}
}
Maven构建器:
package com.ssm.crud.test;
import java.io.IOException;
import org.apache.log4j.PropertyConfigurator;
import org.apache.log4j.xml.DOMConfigurator;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import com.ssm.crud.mapper.DepartmentMapper;
import com.ssm.crud.mapper.EmployeeMapper;
public class CodeTest {
DepartmentMapper departmentMapper;
@Test
public void testCRUD() throws IOException{
//PropertyConfigurator.configure 与 DOMConfigurator.configure 是不同的,分别用于加载 properties 和 xml 类型的配置文件
//下面这句话,加载的配置文件路径是 xxx/target/test-classes/6log4j.xml 结果 找不到, 因为真正的路径是 xxx/target/classes/6log4j.xml
// DOMConfigurator.configure(Thread.currentThread().getContextClassLoader().getResource("").getPath()+"6log4j.xml");
//因为无法正确加载路径,所以采取了 另一种 路径方法
String config=System.getProperty("user.dir");//获取程序的当前路径
System.out.println("config="+config);
DOMConfigurator.configure(config+"/target/classes/6log4j.xml");
//要想 启用log4j 框架 只需要加载log4j配置文件就行 ,上面的代码已经加载 了
// Log4j的 调用方法,版本是 1.X 的, 因为 log4j 2.x 的版本 ,配置文件和调用方法 都变不同了。
// Logger logger = Logger.getLogger(MapperTest.class);
// // 记录debug级别的信息
// logger.error("This is debug message.");
//1、创建SpringIOC容器 ,这个地方 却可以 正确加载 路径 xxx/target/classes/springIOC.xml
//1、创建SpringIOC容器
ApplicationContext ioc = new ClassPathXmlApplicationContext("springIOC.xml");
//2、从容器中获取mapper
EmployeeMapper bean = ioc.getBean(EmployeeMapper.class);
System.out.println(bean.selectByPrimaryKey(1));
}
}
参考:https://www.jianshu.com/p/f256866a2ebe
有时配置文件会报错,主要是网络读取不到文件的原因。可以先clean project ,然后再重新update project。报错举例:
- schema_reference.4: Failed to read schema document 'http://www.springframework.org/schema/tx/spring- tx-4.3.xsd', because 1) could not find the document; 2) the document could not be read; 3) the root element of the document is not <xsd:schema>.
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" id="WebApp_ID" version="2.5"> <!--1、启动Spring的容器 --> <!-- needed for ContextLoaderListener --> <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:springIOC.xml</param-value> </context-param> <!-- Bootstraps the root web application context before servlet initialization --> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> <!--2、springmvc的前端控制器,拦截所有请求 --> <!-- The front controller of this Spring Web application, responsible for handling all application requests --> <servlet> <servlet-name>springMVC</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <!-- Map all requests to the DispatcherServlet for handling --> <servlet-mapping> <servlet-name>springMVC</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> <!-- 3、字符编码过滤器,一定要放在所有过滤器之前 --> <filter> <filter-name>CharacterEncodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>utf-8</param-value> </init-param> <init-param> <param-name>forceRequestEncoding</param-name> <param-value>true</param-value> </init-param> <init-param> <param-name>forceResponseEncoding</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <!-- 4、使用Rest风格的URI,将页面普通的post请求转为指定的delete或者put请求 --> <filter> <filter-name>HiddenHttpMethodFilter</filter-name> <filter-class>org.springframework.web.filter.HiddenHttpMethodFilter</filter-class> </filter> <filter-mapping> <filter-name>HiddenHttpMethodFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <!-- 5、直接支持put请求的拦截器,即在put请求时将请求体数据封装成map,并让springmvc能够通过request.getParameter(属性名) 来获取数据 --> <filter> <filter-name>HttpPutFormContentFilter</filter-name> <filter-class>org.springframework.web.filter.HttpPutFormContentFilter</filter-class> </filter> <filter-mapping> <filter-name>HttpPutFormContentFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>
与web.xml目录同级下创建,springMVC-servlet.xml ,这是根据web.xml中配置的springMVC 得来的。
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:mvc="http://www.springframework.org/schema/mvc" xsi:schemaLocation="http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.3.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd"> <!--SpringMVC的配置文件,包含网站跳转逻辑的控制,配置 --> <context:component-scan base-package="com.ssm.crud" use-default-filters="false"> <!--只扫描控制器。 --> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller"/> </context:component-scan> <!--配置视图解析器,方便页面返回 --> <bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <property name="prefix" value="/WEB-INF/views/"></property> <property name="suffix" value=".jsp"></property> </bean> <!--两个标准配置 --> <!-- 将springmvc不能处理的请求交给tomcat --> <mvc:default-servlet-handler/> <!-- 能支持springmvc更高级的一些功能,JSR303校验,快捷的ajax...映射动态请求 --> <mvc:annotation-driven/> </beans>
因为web.xml已经定义了:spring的容器名是 springIOC,路径是类的根目录。
所以开发的时候,就在src/main/resources 目录下创建 springIOC.xml 配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.3.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.3.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd">
<context:component-scan base-package="com.ssm.crud">
<context:exclude-filter type="annotation"
expression="org.springframework.stereotype.Controller" />
</context:component-scan>
<!-- Spring的配置文件,这里主要配置和业务逻辑有关的 -->
<!--=================== 数据源,事务控制,xxx ================-->
<context:property-placeholder location="classpath:dbconfig.properties" />
<bean id="pooledDataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="url" value="${jdbc.url}" />
<property name="driverClassName" value="${jdbc.driver}" />
<property name="username" value="${jdbc.user}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!--================== 配置和MyBatis的整合=============== -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 指定mybatis全局配置文件的位置 -->
<property name="configLocation" value="classpath:mybatis-config.xml"></property>
<property name="dataSource" ref="pooledDataSource"></property>
<!-- 指定mybatis,mapper文件的位置 -->
<property name="mapperLocations" value="classpath:mapper/*.xml"></property>
</bean>
<!-- 配置扫描器,将mybatis接口的实现加入到ioc容器中 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<!--扫描所有dao接口的实现,加入到ioc容器中 -->
<property name="basePackage" value="com.ssm.crud.mapper"></property>
</bean>
<!-- 配置一个可以执行批量的sqlSession -->
<bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory"></constructor-arg>
<constructor-arg name="executorType" value="BATCH"></constructor-arg>
</bean>
<!--============================================= -->
<!-- ===============事务控制的配置 ================-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!--控制住数据源 -->
<property name="dataSource" ref="pooledDataSource"></property>
</bean>
<!--开启基于注解的事务,使用xml配置形式的事务(必要主要的都是使用配置式) -->
<aop:config>
<!-- 切入点表达式 固定为:execution()
内部参数【 *(代表返回值类型所以) com.ssm.crud.service..(代表这个包及下面的子包) *(紧跟前面的这个星号,代表类中的所有方法) (..)(紧跟前面的这个标记,代表方法里面的参数 任意多) 】-->
<aop:pointcut expression="execution(* com.ssm.crud.service..*(..))" id="txPoint"/>
<!-- 配置事务增强 txAdvice:代表事务切入规则 txPoint:代表切入哪些方法 -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="txPoint"/>
</aop:config>
<!--配置事务增强,也就是 事务如何切入 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!-- 所有方法都是事务方法 -->
<tx:method name="*"/>
<!--以get开始的所有方法 ,认为都是查询方法,可以调优,写成 read only = true -->
<tx:method name="get*" read-only="true"/>
</tx:attributes>
</tx:advice>
<!-- Spring配置文件的核心点(数据源、与mybatis的整合,事务控制) -->
</beans>
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <typeAliases> <package name="com.ssm.crud.bean"/> </typeAliases> </configuration>
dbconfig.properties
##### <!-- http://jingyan.baidu.com/article/b7001fe197a3f60e7282dd8d.html 中文数据库存取乱码问题 ,在 xml文件中 & 要转义成 & 而到了properties中就直接用&就行了 --> jdbc.url=jdbc:mysql://localhost:3306/ssm_crud?useUnicode=true&characterEncoding=UTF-8 jdbc.driver=com.mysql.jdbc.Driver jdbc.user=root jdbc.password=Cool123!
tbl_emp
emp_id emp_name gender email d_id
tbl_dept
dept_id dept_name
1、先导入mybatis-generator-core.jar 包。
在pom.xml中,添加依赖【前面已经添加好了】
<!-- MBG --> <!-- https://mvnrepository.com/artifact/org.mybatis.generator/mybatis-generator-core --> <dependency> <groupId>org.mybatis.generator</groupId> <artifactId>mybatis-generator-core</artifactId> <version>1.3.5</version> </dependency>
2、添加 mbg.xml 配置文件
linux系统下: targetProject=”./src/main/java”
Windows系统下:targetProject=”.\src\main\java”
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd"> <generatorConfiguration> <context id="DB2Tables" targetRuntime="MyBatis3"> <commentGenerator> <property name="suppressAllComments" value="true" /> </commentGenerator> <!-- 配置数据库连接 --> <jdbcConnection driverClass="com.mysql.jdbc.Driver" connectionURL="jdbc:mysql://localhost:3306/ssm_crud" userId="root" password="Cool123!"> </jdbcConnection> <javaTypeResolver> <property name="forceBigDecimals" value="false" /> </javaTypeResolver> <!-- 指定javaBean生成的位置 --> <javaModelGenerator targetPackage="com.ssm.crud.bean" targetProject="./src/main/java"> <property name="enableSubPackages" value="true" /> <property name="trimStrings" value="true" /> </javaModelGenerator> <!--指定sql映射文件生成的位置 --> <sqlMapGenerator targetPackage="mapper" targetProject="./src/main/resources"> <property name="enableSubPackages" value="true" /> </sqlMapGenerator> <!-- 指定dao接口生成的位置,mapper接口 --> <javaClientGenerator type="XMLMAPPER" targetPackage="com.ssm.crud.mapper" targetProject="./src/main/java"> <property name="enableSubPackages" value="true" /> </javaClientGenerator> <!-- table指定每个表的生成策略 --> <table tableName="tbl_emp" domainObjectName="Employee"></table> <table tableName="tbl_dept" domainObjectName="Department"></table> </context> </generatorConfiguration>
3、执行生成代码
package com.ssm.crud.test;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.mybatis.generator.api.MyBatisGenerator;
import org.mybatis.generator.config.Configuration;
import org.mybatis.generator.config.xml.ConfigurationParser;
import org.mybatis.generator.internal.DefaultShellCallback;
public class MBGTest {
public static void main(String[] args) throws Exception {
List<String> warnings = new ArrayList<String>();
boolean overwrite = true;
File configFile = new File("mbg.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config,
callback, warnings);
myBatisGenerator.generate(null);
System.out.println("hhh");
}
}
目的是使:查询employee时,能够顺便获取到 department。
Employee.java
package com.ssm.crud.bean;
public class Employee {
private Integer empId;
private String empName;
private String gender;
private String email;
private Integer dId;
public Integer getEmpId() {
return empId;
}
public void setEmpId(Integer empId) {
this.empId = empId;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName == null ? null : empName.trim();
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender == null ? null : gender.trim();
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email == null ? null : email.trim();
}
public Integer getdId() {
return dId;
}
public void setdId(Integer dId) {
this.dId = dId;
}
//添加 Department 属性,用于关联查询
private Department department;
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
//生成自定义构造器 ,顺便 附带 无参构造器
public Employee(Integer empId, String empName, String gender, String email, Integer dId) {
super();
this.empId = empId;
this.empName = empName;
this.gender = gender;
this.email = email;
this.dId = dId;
}
public Employee() {
super();
}
}
Department.java
package com.ssm.crud.bean;
public class Department {
private Integer deptId;
private String deptName;
public Integer getDeptId() {
return deptId;
}
public void setDeptId(Integer deptId) {
this.deptId = deptId;
}
public String getDeptName() {
return deptName;
}
public void setDeptName(String deptName) {
this.deptName = deptName == null ? null : deptName.trim();
}
//创建构造器时,一定要带上 无参构造器,出于mybatis的 赋值原因
public Department(Integer deptId, String deptName) {
super();
this.deptId = deptId;
this.deptName = deptName;
}
public Department(){
}
}
package com.ssm.crud.mapper;
import com.ssm.crud.bean.Employee;
import com.ssm.crud.bean.EmployeeExample;
import java.util.List;
import org.apache.ibatis.annotations.Param;
public interface EmployeeMapper {
long countByExample(EmployeeExample example);
int deleteByExample(EmployeeExample example);
int deleteByPrimaryKey(Integer empId);
int insert(Employee record);
int insertSelective(Employee record);
List<Employee> selectByExample(EmployeeExample example);
Employee selectByPrimaryKey(Integer empId);
int updateByExampleSelective(@Param("record") Employee record, @Param("example") EmployeeExample example);
int updateByExample(@Param("record") Employee record, @Param("example") EmployeeExample example);
int updateByPrimaryKeySelective(Employee record);
int updateByPrimaryKey(Employee record);
// 为了 提供 关联查询,自己添加的 两个接口 方法
List<Employee> selectByExampleWithDept(EmployeeExample example);
Employee selectByPrimaryKeyWithDept(Integer empId);
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ssm.crud.mapper.EmployeeMapper">
<resultMap id="BaseResultMap" type="com.ssm.crud.bean.Employee">
<id column="emp_id" jdbcType="INTEGER" property="empId" />
<result column="emp_name" jdbcType="VARCHAR" property="empName" />
<result column="gender" jdbcType="CHAR" property="gender" />
<result column="email" jdbcType="VARCHAR" property="email" />
<result column="d_id" jdbcType="INTEGER" property="dId" />
</resultMap>
<sql id="Example_Where_Clause">
<where>
<foreach collection="oredCriteria" item="criteria" separator="or">
<if test="criteria.valid">
<trim prefix="(" prefixOverrides="and" suffix=")">
<foreach collection="criteria.criteria" item="criterion">
<choose>
<when test="criterion.noValue">
and ${criterion.condition}
</when>
<when test="criterion.singleValue">
and ${criterion.condition} #{criterion.value}
</when>
<when test="criterion.betweenValue">
and ${criterion.condition} #{criterion.value} and #{criterion.secondValue}
</when>
<when test="criterion.listValue">
and ${criterion.condition}
<foreach close=")" collection="criterion.value" item="listItem" open="(" separator=",">
#{listItem}
</foreach>
</when>
</choose>
</foreach>
</trim>
</if>
</foreach>
</where>
</sql>
<sql id="Update_By_Example_Where_Clause">
<where>
<foreach collection="example.oredCriteria" item="criteria" separator="or">
<if test="criteria.valid">
<trim prefix="(" prefixOverrides="and" suffix=")">
<foreach collection="criteria.criteria" item="criterion">
<choose>
<when test="criterion.noValue">
and ${criterion.condition}
</when>
<when test="criterion.singleValue">
and ${criterion.condition} #{criterion.value}
</when>
<when test="criterion.betweenValue">
and ${criterion.condition} #{criterion.value} and #{criterion.secondValue}
</when>
<when test="criterion.listValue">
and ${criterion.condition}
<foreach close=")" collection="criterion.value" item="listItem" open="(" separator=",">
#{listItem}
</foreach>
</when>
</choose>
</foreach>
</trim>
</if>
</foreach>
</where>
</sql>
<sql id="Base_Column_List">
emp_id, emp_name, gender, email, d_id
</sql>
<!-- 自动创建的是 查询员工不带部门信息的 -->
<select id="selectByExample" parameterType="com.ssm.crud.bean.EmployeeExample" resultMap="BaseResultMap">
select
<if test="distinct">
distinct
</if>
<include refid="Base_Column_List" />
from tbl_emp
<if test="_parameter != null">
<include refid="Example_Where_Clause" />
</if>
<if test="orderByClause != null">
order by ${orderByClause}
</if>
</select>
<select id="selectByPrimaryKey" parameterType="java.lang.Integer" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from tbl_emp
where emp_id = #{empId,jdbcType=INTEGER}
</select>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Integer">
delete from tbl_emp
where emp_id = #{empId,jdbcType=INTEGER}
</delete>
<delete id="deleteByExample" parameterType="com.ssm.crud.bean.EmployeeExample">
delete from tbl_emp
<if test="_parameter != null">
<include refid="Example_Where_Clause" />
</if>
</delete>
<insert id="insert" parameterType="com.ssm.crud.bean.Employee">
insert into tbl_emp (emp_id, emp_name, gender,
email, d_id)
values (#{empId,jdbcType=INTEGER}, #{empName,jdbcType=VARCHAR}, #{gender,jdbcType=CHAR},
#{email,jdbcType=VARCHAR}, #{dId,jdbcType=INTEGER})
</insert>
<insert id="insertSelective" parameterType="com.ssm.crud.bean.Employee">
insert into tbl_emp
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="empId != null">
emp_id,
</if>
<if test="empName != null">
emp_name,
</if>
<if test="gender != null">
gender,
</if>
<if test="email != null">
email,
</if>
<if test="dId != null">
d_id,
</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="empId != null">
#{empId,jdbcType=INTEGER},
</if>
<if test="empName != null">
#{empName,jdbcType=VARCHAR},
</if>
<if test="gender != null">
#{gender,jdbcType=CHAR},
</if>
<if test="email != null">
#{email,jdbcType=VARCHAR},
</if>
<if test="dId != null">
#{dId,jdbcType=INTEGER},
</if>
</trim>
</insert>
<select id="countByExample" parameterType="com.ssm.crud.bean.EmployeeExample" resultType="java.lang.Long">
select count(*) from tbl_emp
<if test="_parameter != null">
<include refid="Example_Where_Clause" />
</if>
</select>
<update id="updateByExampleSelective" parameterType="map">
update tbl_emp
<set>
<if test="record.empId != null">
emp_id = #{record.empId,jdbcType=INTEGER},
</if>
<if test="record.empName != null">
emp_name = #{record.empName,jdbcType=VARCHAR},
</if>
<if test="record.gender != null">
gender = #{record.gender,jdbcType=CHAR},
</if>
<if test="record.email != null">
email = #{record.email,jdbcType=VARCHAR},
</if>
<if test="record.dId != null">
d_id = #{record.dId,jdbcType=INTEGER},
</if>
</set>
<if test="_parameter != null">
<include refid="Update_By_Example_Where_Clause" />
</if>
</update>
<update id="updateByExample" parameterType="map">
update tbl_emp
set emp_id = #{record.empId,jdbcType=INTEGER},
emp_name = #{record.empName,jdbcType=VARCHAR},
gender = #{record.gender,jdbcType=CHAR},
email = #{record.email,jdbcType=VARCHAR},
d_id = #{record.dId,jdbcType=INTEGER}
<if test="_parameter != null">
<include refid="Update_By_Example_Where_Clause" />
</if>
</update>
<update id="updateByPrimaryKeySelective" parameterType="com.ssm.crud.bean.Employee">
update tbl_emp
<set>
<if test="empName != null">
emp_name = #{empName,jdbcType=VARCHAR},
</if>
<if test="gender != null">
gender = #{gender,jdbcType=CHAR},
</if>
<if test="email != null">
email = #{email,jdbcType=VARCHAR},
</if>
<if test="dId != null">
d_id = #{dId,jdbcType=INTEGER},
</if>
</set>
where emp_id = #{empId,jdbcType=INTEGER}
</update>
<update id="updateByPrimaryKey" parameterType="com.ssm.crud.bean.Employee">
update tbl_emp
set emp_name = #{empName,jdbcType=VARCHAR},
gender = #{gender,jdbcType=CHAR},
email = #{email,jdbcType=VARCHAR},
d_id = #{dId,jdbcType=INTEGER}
where emp_id = #{empId,jdbcType=INTEGER}
</update>
<!-- ****** 自定义的 带部门信息 的两种查询 ****** -->
<sql id="WithDept_Column_List">
e.emp_id, e.emp_name, e.gender, e.email, e.d_id,d.dept_id,d.dept_name
</sql>
<!-- List<Employee> selectByExampleWithDept(EmployeeExample example);
Employee selectByPrimaryKeyWithDept(Integer empId);
-->
<resultMap type="com.ssm.crud.bean.Employee" id="WithDeptResultMap">
<id column="emp_id" jdbcType="INTEGER" property="empId" />
<result column="emp_name" jdbcType="VARCHAR" property="empName" />
<result column="gender" jdbcType="CHAR" property="gender" />
<result column="email" jdbcType="VARCHAR" property="email" />
<result column="d_id" jdbcType="INTEGER" property="dId" />
<!-- 指定联合查询出的部门字段的封装 -->
<association property="department" javaType="com.ssm.crud.bean.Department">
<id column="dept_id" property="deptId"/>
<result column="dept_name" property="deptName"/>
</association>
</resultMap>
<!-- 查询员工同时带部门信息 -->
<select id="selectByExampleWithDept" resultMap="WithDeptResultMap">
select
<if test="distinct">
distinct
</if>
<include refid="WithDept_Column_List" />
FROM tbl_emp e
left join tbl_dept d on e.`d_id`=d.`dept_id`
<if test="_parameter != null">
<include refid="Example_Where_Clause" />
</if>
<if test="orderByClause != null">
order by ${orderByClause}
</if>
</select>
<select id="selectByPrimaryKeyWithDept" resultMap="WithDeptResultMap">
select
<include refid="WithDept_Column_List" />
FROM tbl_emp e
left join tbl_dept d on e.`d_id`=d.`dept_id`
where emp_id = #{empId,jdbcType=INTEGER}
</select>
</mapper>
需要在Maven中的pom.xml中,导入 junit.jar 包。
<!-- 一开始这里初始化 Junit 版本为3 ,
当 eclipse 创建测试用例时,我选4版本的用例,发现又添加了Junit4 依赖包
为了统一,我就在这里 改成 Juin4 依赖包,这样 eclipse创建 单元测试时就不会 重新添加依赖包了 -->
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
package com.ssm.crud.test;
import java.io.IOException;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import com.ssm.crud.mapper.DepartmentMapper;
import com.ssm.crud.mapper.EmployeeMapper;
public class CodeTest {
DepartmentMapper departmentMapper;
@Test
public void testCRUD() throws IOException{
//1、创建SpringIOC容器 ,这个地方 却可以 正确加载 路径 xxx/target/classes/springIOC.xml
//1、创建SpringIOC容器
ApplicationContext ioc = new ClassPathXmlApplicationContext("springIOC.xml");
//2、从容器中获取mapper
EmployeeMapper bean = ioc.getBean(EmployeeMapper.class);
System.out.println(bean.selectByPrimaryKey(1));
}
}
需要在Maven的pom.xml中导入 spring-test.jar 包。
<!--Spring-test 单元测试 适配框架,用于在单元测试时,无需初始化就可以使用Spring 容器,及Spring注解 --> <!-- https://mvnrepository.com/artifact/org.springframework/spring-test --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>4.3.7.RELEASE</version> </dependency>
package com.ssm.crud.test;
import java.io.IOException;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import com.ssm.crud.mapper.DepartmentMapper;
import com.ssm.crud.mapper.EmployeeMapper;
/**
* 测试dao层的工作
* @author lfy
*推荐Spring的项目就可以使用Spring的单元测试,可以自动注入我们需要的组件
*1、导入SpringTest模块
*2、@ContextConfiguration指定Spring配置文件的位置
*3、直接autowired要使用的组件即可
*/
//@RunWith这个是 junit-4.jar包 提供的注解, 而 SpringJUnit4ClassRunner.class 是spring-test 提供的类
@RunWith(SpringJUnit4ClassRunner.class)
//@ContextConfiguration 这个是 spring-test.jar包 提供的注解 , 用于启动 spring容器,方便直接获取spring容器中的bean
@ContextConfiguration(locations={"classpath:springIOC.xml"})
public class AnnotationTest {
@Autowired
DepartmentMapper departmentMapper;
@Autowired
EmployeeMapper employeeMapper;
@Autowired
SqlSession sqlSession;
/**
* 测试DepartmentMapper
*/
@Test
public void testCRUD() throws IOException{
System.out.println(employeeMapper.selectByPrimaryKey(1));
//1、插入几个部门
departmentMapper.insertSelective(new Department(null, "开发部"));
departmentMapper.insertSelective(new Department(null, "测试部"));
//2、生成员工数据,测试员工插入
employeeMapper.insertSelective(new Employee(null, "Jerry", "M", "[email protected]", 1));
//3、批量插入多个员工;批量,使用可以执行批量操作的sqlSession。
// for(){
// employeeMapper.insertSelective(new Employee(null, , "M", "[email protected]", 1));
// }
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
for(int i = 0;i<1000;i++){
String uid = UUID.randomUUID().toString().substring(0,5)+i;
mapper.insertSelective(new Employee(null,uid, "M", uid+"@atguigu.com", 1));
}
System.out.println("批量完成");
}
}
public class JUnit4ClassRunner extends SpringJUnit4ClassRunner {
static {
try {
// classpath 是 二进制 class文件 的执行根路径
Log4jConfigurer.initLogging("classpath:log4j.xml");
} catch (FileNotFoundException ex) {
System.err.println("Cannot Initialize log4j");
}
}
public JUnit4ClassRunner(Class<?> clazz) throws InitializationError {
super(clazz);
}
}
@RunWith(JUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:springIOC.xml")
public class AnnotationTest {
...
}
Junit加载spring的runner(SpringJUnit4ClassRunner)要优先于spring加载log4j【log4j的自动默认加载功能】,因此采用普通方法,无法实现spring先加载log4j后被Junit加载。所以我们需要新建JUnit4ClassRunner类,修改SpringJUnit4ClassRunner加载log4j的策略。这样加载log4j就会优先于加载spring了。

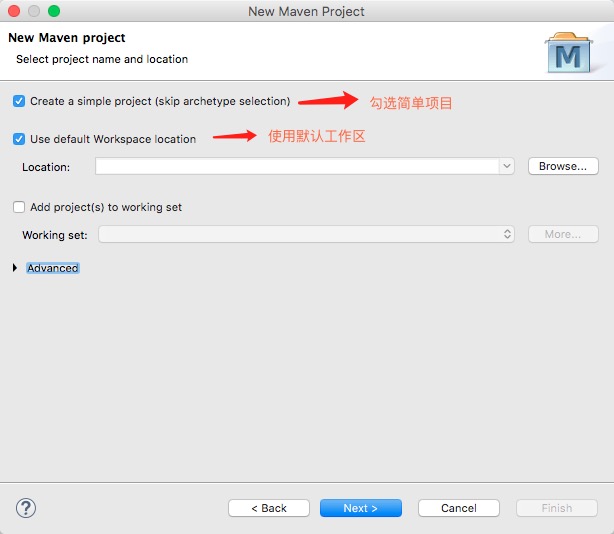
特别注意:以下这一大块文字是后期修改勘误的,maven工程新建时应该选择:webapp项目,这样后面就会自动出现,web-xml文件和目录了。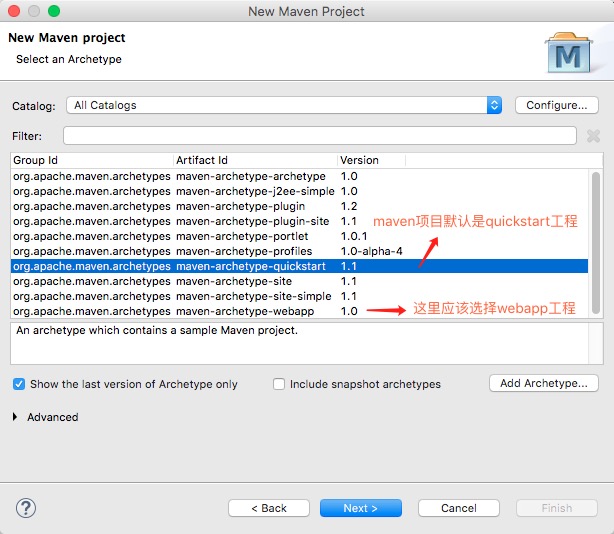
本文章下面的配置使系统自动生成WebContent目录,其实这个操作不需要,可以直接删除WebContent目录,然后运行maven clean,maven update project 来重建web 目录 ,修复项目错误,因为maven的web工程自带了src/main/webapp/WEB-INF/web.xml,以后所有的web文件都可以直接放到web-app目录中。
此外我这里默认生成的webapp/WEB-INF/web.xml 是2.3版本的。
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd" > <web-app> <display-name>Archetype Created Web Application</display-name> </web-app>
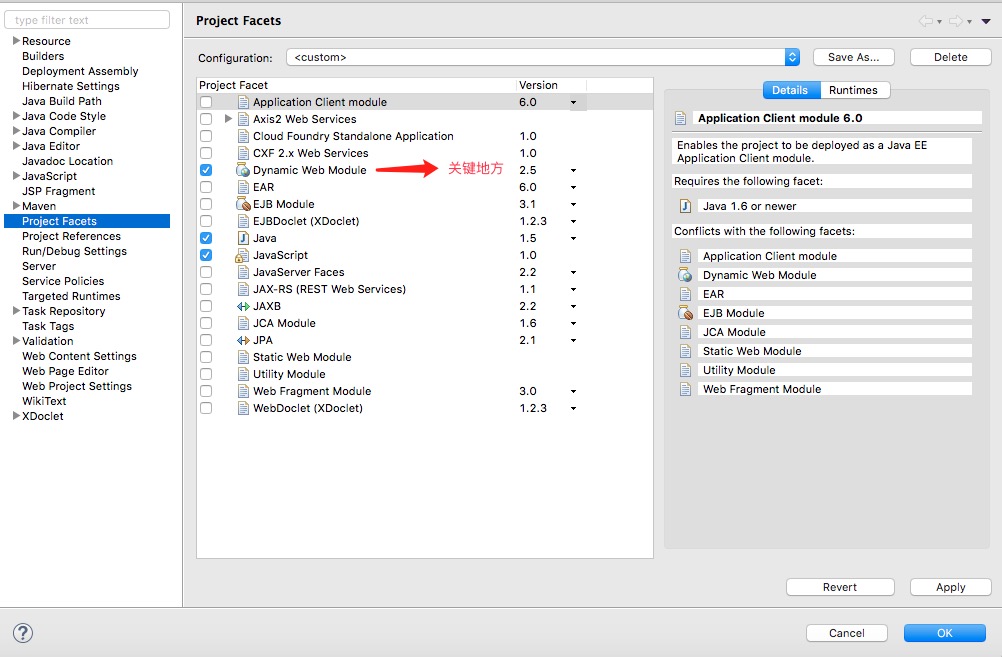
如果要修改的话,可以参看下文中的 可以点击项目,右键Properties 找到 Project Facet , 找到 Dynamic web 可以选择 3.1 版本,点击保存。但是因为bug,好像修改不了web.xml的里面的版本号。怎么办:
第一步:找到项目文件夹:有一个隐藏文件夹 .setting
查看隐藏文件夹下的文件: org.eclipse.core.resources.prefs org.eclipse.jdt.core.prefs org.eclipse.m2e.core.prefs org.eclipse.wst.common.component org.eclipse.wst.common.project.facet.core.xml org.eclipse.wst.jsdt.ui.superType.container org.eclipse.wst.jsdt.ui.superType.name org.eclipse.wst.validation.prefs 需要修改的文件是 org.eclipse.wst.common.project.facet.core.xml <?xml version="1.0" encoding="UTF-8"?> <faceted-project> <fixed facet="wst.jsdt.web"/> <installed facet="java" version="1.7"/> <installed facet="jst.web" version="2.3"/> <installed facet="wst.jsdt.web" version="1.0"/> </faceted-project> 将它改成: <?xml version="1.0" encoding="UTF-8"?> <faceted-project> <fixed facet="wst.jsdt.web"/> <installed facet="java" version="1.7"/> <installed facet="jst.web" version="3.1"/> <installed facet="wst.jsdt.web" version="1.0"/> </faceted-project>
第二步:在web.xml中,用3.1的版本信息,替换掉2.3的版本信息。
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" id="WebApp_ID" version="3.1"> <display-name>Archetype Created Web Application</display-name> </web-app>
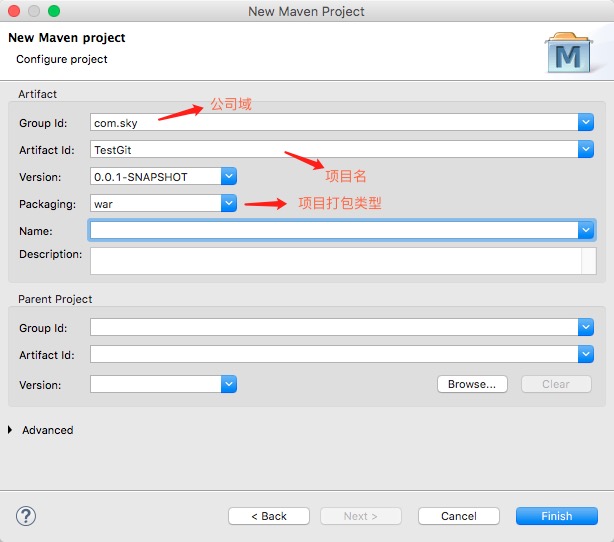
参考自:创建maven项目是其中的group id和artifact id怎么填写
groupid和artifactId被统称为“坐标”是为了保证项目唯一性而提出的,如果你要把你项目弄到maven本地仓库去,你想要找到你的项目就必须根据这两个id去查找。
groupId一般分为多个段,这里我只说两段,第一段为域,第二段为公司名称。域又分为org、com、cn等等许多,其中org为非营利组织,com为商业组织。举个apache公司的tomcat项目例子:这个项目的groupId是org.apache,它的域是org(因为tomcat是非营利项目),公司名称是apache,artigactId是tomcat。
比如我创建一个项目,我一般会将groupId设置为cn.pq,cn表示域为中国,pq是我个人姓名缩写,artifactId设置为testProj,表示你这个项目的名称是testProj,依照这个设置,你的包结构最好是cn.pq.testProj打头的,如果有个StudentPeng,它的全路径就是cn.pq.testProj.StudentPeng
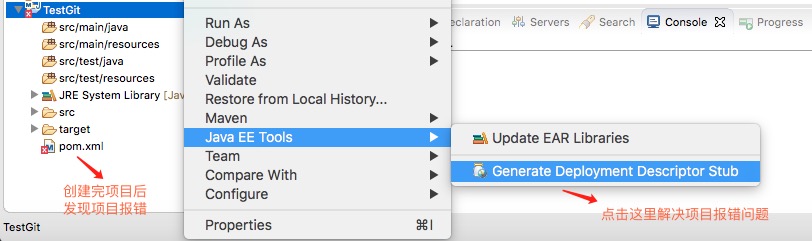
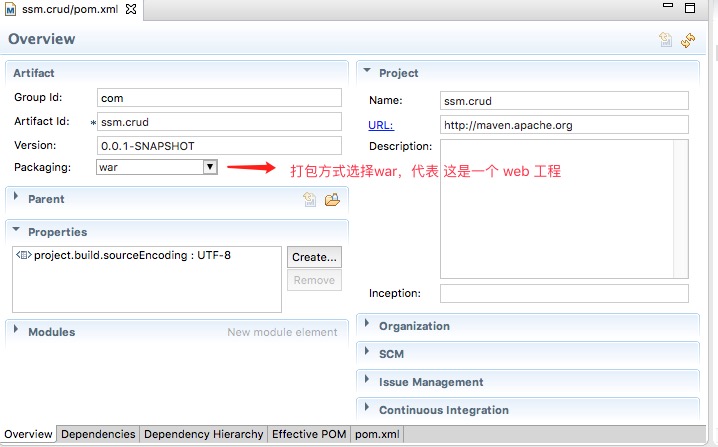
参考自:maven中packing类型 jar、war、pom 的区别
pom是maven依赖文件
jar是java普通项目打包
war是java web项目打包
pom:打出来可以作为其他项目的maven依赖,在工程A中添加工程B的pom,A就可以使用B中的类。用在父级工程或聚合工程中。用来做jar包的版本控制。
jar包:通常是开发时要引用通用类,打成jar包便于存放管理。当你使用某些功能时就需要这些jar包的支持,需要导入jar包。
war包:是做好一个web网站后,打成war包部署到服务器。目的是节省资源,提供效率。
解决新创建的项目:报错问题
下面的的1-3小步 搭建maven工程方法已经被淘汰了,请看上面的搭建方法。
1、eclipse里面 右键新建 Maven工程,选择 maven-archetype-quickstart
2、如果项目有错误,可以点击项目,右键maven –> update project
3、如果项目缺失 web.xml可以点击项目,右键Properties 找到 Project Facet 取消勾选 Dynamic web,然后重新勾选。【可能勾选后,窗口底部有个配置网站链接,点进去可以自动生成web.xml】这样就会出现 web.xml了。
4、关于maven的 镜像 和 JDK 配置
在整个eclipse的属性配置中,点击maven,会有User Settings 对话框;用来配置用户范围内的maven 属性。为了统一和方便,这里配置了镜像和 指定了jdk环境。【maven 中的 settings 文件,因为eclipse中没有自带,需要自己先下载maven,然后拷贝到相关目录。然后才能 编辑 相关配置】

因为目前的maven配置规则 都是1.0.0版本,所以配置文件都是通用的。【如下所示:】
xmlns="http://maven.apache.org/SETTINGS/1.0.0
settings配置如下:
配置镜像:
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
指定jdk:
<profiles>
<profile>
<id>jdk17</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.7</jdk>
</activation>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<maven.compiler.compilerVersion>1.7</maven.compiler.compilerVersion>
</properties>
</profile>
<profile>
<id>jdk17</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.7</jdk>
</activation>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<maven.compiler.compilerVersion>1.7</maven.compiler.compilerVersion>
</properties>
</profile>
</profiles>
maven项目内的pom.xml配置文件中,可以配置 <dependency>来配置依赖。
特别注意:下面的这个依赖项可以不添加。
<!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api --> <!-- 因为servlet包 在服务器 上是有的,在开发中没有 提供,所以这里 填scope标签,用来通知发布软件时,不需要把这个包打入到项目中。 --> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>3.0.1</version> <scope>provided</scope> </dependency>
因为只要在web项目中的build path中,add library –>server runtime–>Apache tomcat 添加好后,就有了 servlet 依赖了。
下面是具体的在pom.xml中配置<dependency>依赖项的过程:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com</groupId>
<artifactId>ssm.crud</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>
<name>ssm.crud</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!--引入项目依赖的jar包 -->
<!-- SpringMVC、Spring -->
<!-- https://mvnrepository.com/artifact/org.springframework/spring-webmvc -->
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<!--引入pageHelper分页插件 -->
<!-- https://mvnrepository.com/artifact/com.github.pagehelper/pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.7</version>
</dependency>
<!-- MBG -->
<!-- https://mvnrepository.com/artifact/org.mybatis.generator/mybatis-generator-core -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.5</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.3.7.RELEASE</version>
</dependency>
<!-- 返回json字符串的支持 -->
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.8</version>
</dependency>
<!--JSR303数据校验支持;tomcat7及以上的服务器, tomcat7以下的服务器:el表达式。额外给服务器的lib包中替换新的标准的el -->
<!-- https://mvnrepository.com/artifact/org.hibernate/hibernate-validator -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.4.1.Final</version>
</dependency>
<!--Spring-test 单元测试 适配框架,用于在单元测试时,无需初始化就可以使用Spring 容器,及Spring注解 -->
<!-- https://mvnrepository.com/artifact/org.springframework/spring-test -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.3.7.RELEASE</version>
</dependency>
<!-- Spring面向切面编程 -->
<!-- https://mvnrepository.com/artifact/org.springframework/spring-aspects -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>4.3.7.RELEASE</version>
</dependency>
<!--MyBatis -->
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.2</version>
</dependency>
<!-- MyBatis整合Spring的适配包 -->
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis-spring -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.1</version>
</dependency>
<!-- 数据库连接池、驱动 -->
<!-- Spring-Jdbc -->
<!-- https://mvnrepository.com/artifact/org.springframework/spring-jdbc -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.3.7.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.41</version>
</dependency>
<!-- (jstl,servlet-api,junit) -->
<!-- https://mvnrepository.com/artifact/jstl/jstl -->
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api -->
<!-- 因为servlet包 在服务器 上是有的,在开发中没有 提供,所以这里 填scope标签,用来通知发布软件时,不需要把这个包打入到项目中。 -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.0.1</version>
<scope>provided</scope>
</dependency>
<!-- 一开始这里初始化 Junit 版本为3 ,
当 eclipse 创建测试用例时,我选4版本的用例,发现又添加了Junit4 依赖包
为了统一,我就在这里 改成 Juin4 依赖包,这样 eclipse创建 单元测试时就不会 重新添加依赖包了 -->
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
采用bootstrap框架:需要jQuery 支持。
bootstrap框架:包括【js、css、fonts】三个文件夹。
注意web文件放在 WebContent中,在eclipse中可以正常运行。但是用maven打包时失败了,所以web文件应该放在:src/main/webapp 目录下,这样平时的运行和打包都能成功。详见本系列最后一篇文章。
一般maven项目,我们会看到这个目录:src/main/resources ,这个怎么操作呢。我们举例一下:
1、项目右键 build path / configure build path
2、点击 Add Folder
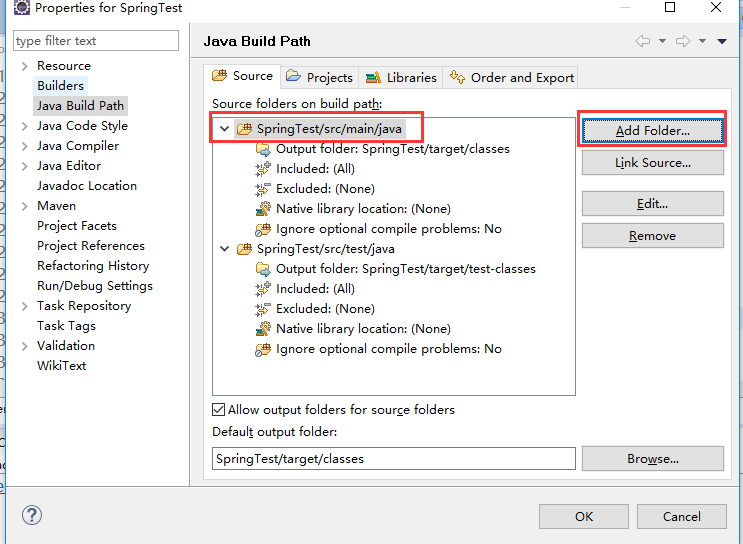
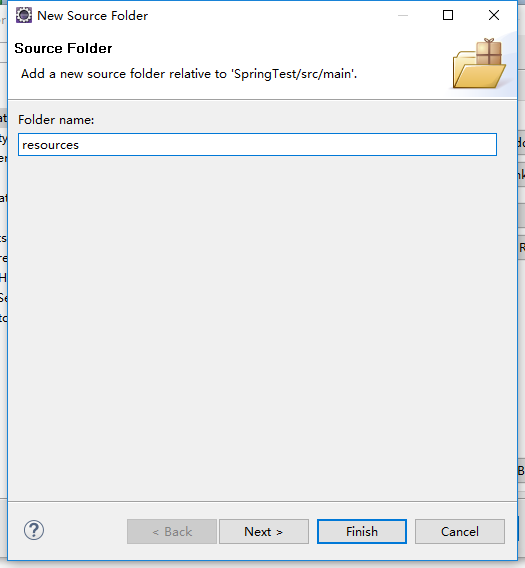
注意:这里我们可以看到src/main/java的输出目录(output folder)是target/classes , src/test/java 的输出目录是target/test-classes 。我们现在要添加的src/main/resources 输出目录也是 target/classes。如果以后需要src/test/resources 那么记得要将输出目录 修改成 target/test-classes
接下来:点击 Create New Folder
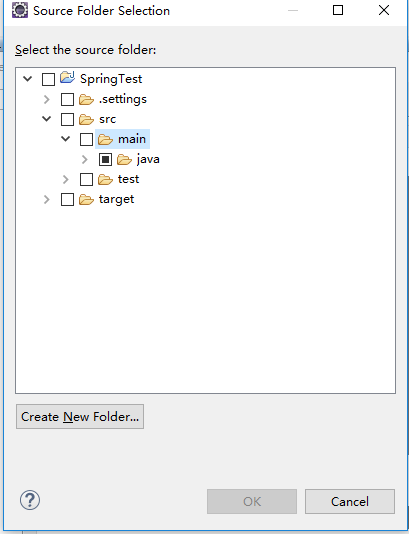
接下来:点击 Finish 就OK啦。

1、jsqlparser.jar
2、pagehelper.jar
在全局配置文件中:mybatis-config.xml中,添加
<!-- 启用自定义插件拦截器 --> <plugins> <plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin> </plugins>
直接在需要的地方,调用 PageHelper就行了。
PageHelper,Page,PageInfo,都是分页插件自带的对象。
@Test
public void test_Page() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
//会为接口自动的创建一个代理对象,代理对象去执行增删改查方法
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Page<Object> page = PageHelper.startPage(1,5);
List<Employee> emps = mapper.getEmps();
/*System.out.println("当前页码:"+page.getPageNum());
System.out.println("总记录数:"+page.getTotal());
System.out.println("每页的记录数:"+page.getPageSize());
System.out.println("总页码:"+page.getPages());*/
//传入要连续显示多少页
PageInfo<Employee> info = new PageInfo<>(emps, 5);
System.out.println("当前页码:"+info.getPageNum());
System.out.println("总记录数:"+info.getTotal());
System.out.println("每页的记录数:"+info.getPageSize());
System.out.println("总页码:"+info.getPages());
System.out.println("是否第一页:"+info.isIsFirstPage());
System.out.println("连续显示的页码:");
int[] nums = info.getNavigatepageNums();
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
for (Employee employee : emps) {
System.out.println(employee);
}
} finally {
openSession.close();
}
}
mybatis 在 处理 枚举类型 的读取和保存时,默认提供 了 两种方案:
1、mybatis 默认使用EnumTypeHandler 在处理枚举对象的时候保存的是枚举的名字。
2、 也可以改用:EnumOrdinalTypeHandler:【读取和保存都是 —》枚举的索引】
可以在mybatis-config.xml中配置,也可以在SQL映射文件中:
<typeHandlers>
<!--1、配置我们自定义的TypeHandler -->
<typeHandler handler="com.mybatis.typehandler.MyEnumEmpStatusTypeHandler" javaType="com.mybatis.typehandler.EmpStatus"/>
<!--2、也可以在处理某个字段的时候告诉MyBatis用什么类型处理器
增删改中:#{empStatus,typeHandler=xxxx}
查询中:
<resultMap type="com.atguigu.mybatis.bean.Employee" id="MyEmp">
<id column="id" property="id"/>
<result column="empStatus" property="empStatus" typeHandler=""/>
</resultMap>
注意:如果在参数位置修改TypeHandler,应该保证保存数据和查询数据用的TypeHandler是一样的。
-->
</typeHandlers>
这里用自定义枚举类型处理器举例:
EmpStatus.java
package com.mybatis.typehandler;
/**
* 希望数据库保存的是100,200这些状态码,而不是默认0,1或者枚举的名
* @author lfy
*
*/
public enum EmpStatus {
LOGIN(100,"用户登录"),LOGOUT(200,"用户登出"),REMOVE(300,"用户不存在");
private Integer code;
private String msg;
private EmpStatus(Integer code,String msg){
this.code = code;
this.msg = msg;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
//按照状态码返回枚举对象
public static EmpStatus getEmpStatusByCode(Integer code){
switch (code) {
case 100:
return LOGIN;
case 200:
return LOGOUT;
case 300:
return REMOVE;
default:
return LOGOUT;
}
}
}
EnumEmpStatusTypeHandler.java
package com.mybatis.typehandler;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.TypeHandler;
/**
* 1、实现TypeHandler接口。或者继承BaseTypeHandler
* @author lfy
*
*/
public class EnumEmpStatusTypeHandler implements TypeHandler<EmpStatus> {
/**
* 定义当前数据如何保存到数据库中
*/
@Override
public void setParameter(PreparedStatement ps, int i, EmpStatus parameter,
JdbcType jdbcType) throws SQLException {
// TODO Auto-generated method stub
System.out.println("要保存的状态码:"+parameter.getCode());
ps.setString(i, parameter.getCode().toString());
}
@Override
public EmpStatus getResult(ResultSet rs, String columnName)
throws SQLException {
// TODO Auto-generated method stub
//需要根据从数据库中拿到的枚举的状态码返回一个枚举对象
int code = rs.getInt(columnName);
System.out.println("从数据库中获取的状态码:"+code);
EmpStatus status = EmpStatus.getEmpStatusByCode(code);
return status;
}
@Override
public EmpStatus getResult(ResultSet rs, int columnIndex)
throws SQLException {
// TODO Auto-generated method stub
int code = rs.getInt(columnIndex);
System.out.println("从数据库中获取的状态码:"+code);
EmpStatus status = EmpStatus.getEmpStatusByCode(code);
return status;
}
@Override
public EmpStatus getResult(CallableStatement cs, int columnIndex)
throws SQLException {
// TODO Auto-generated method stub
int code = cs.getInt(columnIndex);
System.out.println("从数据库中获取的状态码:"+code);
EmpStatus status = EmpStatus.getEmpStatusByCode(code);
return status;
}
}
配置mybatis-config.xml,启用 EnumEmpStatusTypeHandler
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeHandlers>
<!--1、配置我们自定义的TypeHandler -->
<typeHandler handler="com.mybatis.typehandler.EnumEmpStatusTypeHandler" javaType="com.mybatis.typehandler.EmpStatus"/>
<!--2、也可以在处理某个字段的时候告诉MyBatis用什么类型处理器
增删改中:#{empStatus,typeHandler=xxxx}
查询中:
<resultMap type="com.atguigu.mybatis.bean.Employee" id="MyEmp">
<id column="id" property="id"/>
<result column="empStatus" property="empStatus" typeHandler=""/>
</resultMap>
注意:如果在参数位置修改TypeHandler,应该保证保存数据和查询数据用的TypeHandler是一样的。
-->
</typeHandlers>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mybatis" />
<property name="username" value="root" />
<property name="password" value="Kitty521!" />
</dataSource>
</environment>
</environments>
<!-- 5、databaseIdProvider:支持多数据库厂商的;
type="DB_VENDOR":VendorDatabaseIdProvider
作用就是得到数据库厂商的标识(驱动getDatabaseProductName()),mybatis就能根据数据库厂商标识来执行不同的sql;
MySQL,Oracle,SQL Server,xxxx
-->
<databaseIdProvider type="DB_VENDOR">
<!-- 为不同的数据库厂商起别名 -->
<property name="MySQL" value="mysql"/>
<property name="Oracle" value="oracle"/>
<property name="SQL Server" value="sqlserver"/>
</databaseIdProvider>
<!-- 将我们写好的sql映射文件(EmployeeMapper.xml)一定要注册到全局配置文件(mybatis-config.xml)中
如果 数据库全局文件 和 子配置文件 不在同一个目录 ,就需要 /目录/目录/.../EmployeeMapper_old.xml
-->
<mappers>
<!-- 新方法操作mybatis 需要 的配置文件 -->
<mapper resource="EmployeeMapper.xml" />
</mappers>
</configuration>
package com.mybatis.bean;
import com.mybatis.typehandler.EmpStatus;
public class Employee {
private Integer id;
private String lastName;
private String email;
private String gender;
//员工状态
private EmpStatus empStatus=EmpStatus.LOGOUT;
public EmpStatus getEmpStatus() {
return empStatus;
}
public void setEmpStatus(EmpStatus empStatus) {
this.empStatus = empStatus;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Employee(){
super();
}
public Employee(String lastName, String email, String gender) {
super();
this.lastName = lastName;
this.email = email;
this.gender = gender;
}
@Override
public String toString() {
return "Employee [id=" + id + ", lastName=" + lastName + ", email=" + email + ", gender=" + gender + "]";
}
}
package com.mybatis.mapper;
import java.util.List;
import com.mybatis.bean.Employee;
import com.mybatis.bean.ProcPage;
public interface EmployeeMapper {
public Employee getEmpById(Integer id);
public Long addEmp(Employee employee);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.mapper.EmployeeMapper">
<!--
namespace:名称空间;指定为接口的全类名
id:唯一标识
resultType:返回值类型
#{id}:从传递过来的参数中取出id值
public Employee getEmpById(Integer id);
-->
<select id="getEmpById" resultType="com.mybatis.bean.Employee">
select id,last_name lastName,email,gender,empStatus from tbl_employee where id = #{id}
</select>
<!--public Long addEmp(Employee employee); -->
<insert id="addEmp" useGeneratedKeys="true" keyProperty="id">
insert into tbl_employee(last_name,email,gender,empStatus)
values(#{lastName},#{email},#{gender},#{empStatus})
</insert>
</mapper>
注意:要分两步操作,第一步先插入数据,观察数据库中枚举的保存形式,第二步再读取数据,观察枚举的读取形式。
package com.mybatis.test;
import java.io.IOException;
import java.io.InputStream;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import com.mybatis.bean.Employee;
import com.mybatis.bean.ProcPage;
import com.mybatis.mapper.EmployeeMapper;
import com.mybatis.typehandler.EmpStatus;
/**
* 1、接口式编程
* 原生: Dao ====> DaoImpl
* mybatis: Mapper ====> xxMapper.xml
*
* 2、SqlSession代表和数据库的一次会话;用完必须关闭;
* 3、SqlSession和connection一样她都是非线程安全。每次使用都应该去获取新的对象。(就是不要放在共享成员变量里面,A线程用完释放,B线程再用就为空了)
* 4、mapper接口没有实现类,但是mybatis会为这个接口生成一个代理对象。
* (将接口和xml进行绑定)
* EmployeeMapper empMapper = sqlSession.getMapper(EmployeeMapper.class);
* 5、两个重要的配置文件:
* mybatis的全局配置文件:包含数据库连接池信息,事务管理器信息等...系统运行环境信息
* sql映射文件:保存了每一个sql语句的映射信息:
* 将sql抽取出来。
*
*/
public class MybatisTest {
public SqlSessionFactory getSqlSessionFactory() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
return new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void testEnumUse(){
EmpStatus login = EmpStatus.LOGIN;
System.out.println("枚举的索引:"+login.ordinal());
System.out.println("枚举的名字:"+login.name());
System.out.println("枚举的状态码:"+login.getCode());
System.out.println("枚举的提示消息:"+login.getMsg());
}
/**
* 默认mybatis在处理枚举对象的时候保存的是枚举的名字:EnumTypeHandler
* 改变使用:EnumOrdinalTypeHandler:【读取和保存都是 --》枚举的索引,】
* @throws IOException
*/
@Test
public void testEnum() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession openSession = sqlSessionFactory.openSession();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
// 第一遍:先执行下面四句话,数据库中新建 一条记录 ,打开数据库并查看 枚举保存类型
// Employee employee = new Employee("test_enum", "[email protected]","1");
// mapper.addEmp(employee);
// System.out.println("保存成功"+employee.getId());
// openSession.commit();
// 第二遍:当数据库执行插入操作后,观察 插入是是 那一条 ID,然后再读取出来 ,查看 枚举类型
// Employee empById = mapper.getEmpById(11);
// System.out.println(empById.getEmpStatus());
}finally{
openSession.close();
}
}
}
mybatis 在编写SQL映射文件时,要注意
返回值是 resultType和resultMap
不要搞错了,否则 运行就会报错啦。
id last_name gender email 1 mike 0 [email protected] 2 book 0 [email protected] 3 tom 1 [email protected] 4 jerry 1 [email protected] 5 hhee 1 [email protected] 6 jerry4 1 [email protected] 7 smith0x1 1 [email protected] 8 mas 1 [email protected] 9 smith0x1 1 [email protected] 10 allen0x1 0 [email protected]
USE `mybatis`; DROP PROCEDURE IF EXISTS proc_employee; DELIMITER // CREATE PROCEDURE proc_employee(IN p_start INT, IN p_end INT,OUT p_count INT) BEGIN SELECT COUNT(*) INTO p_count FROM `tbl_employee`; SELECT * FROM ( SELECT a.* FROM `tbl_employee` a WHERE a.`id` < p_end) b WHERE b.`id` >p_start; END// DELIMITER ;
特别注意点:
开头部分:DELIMITER //【这两斜杠前面有空格,需要注意】 结尾部分:DELIMITER ;【分号前面也有个空格,需要注意】 在定义过程时,使用DELIMITER // 命令将语句的结束符号从分号 ; 临时改为//,使得过程体中使用的分号被直接传递到服务器,而不会被客户端(如mysql)解释。
set @p_count=1; CALL proc_employee(1,8,@p_count); select @p_count;
-- 8-1: Stored Procedure Intro
-- http://www.artfulsoftware.com/mysqlbook/sampler/mysqled1_appe.html
-- stored procedures
-- paste this script into the mysql client
USE test;
DELIMITER | -- // permit semi-colons within SP
DROP PROCEDURE IF EXISTS worldmesgproc |
CREATE PROCEDURE worldmesgproc( IN s CHAR( 10 ) )
SELECT CONCAT_WS( ' ', s, 'world!' );
|
DROP FUNCTION IF EXISTS worldmesgfunc |
CREATE FUNCTION worldmesgfunc( s CHAR( 10 ) ) RETURNS CHAR( 20 )
RETURN CONCAT_WS( s, 'world!' );
|
DELIMITER ; -- // restore semi-colon as delimiter
CALL worldmesgproc( 'Hello' );
Hello world!
SELECT worldmesgfunc( 'Hello' );
Hello world!
CALL worldmesgfunc( 'Hi' ); -- // funcs cannot be called
ERROR 1289 at line 18: PROCEDURE worldmesgfunc does not exist
DROP PROCEDURE worldmesgproc;
DROP FUNCTION worldmesgfunc;
-- # EOF
-- 8-2: DECLARE ... HANDLER in an SP
-- # Here, because DECLARE EXIT HANDLER … instructs MySQL to exit the SP
-- # if SQLSTATE = 23000, the statement SET @err=-1 never executes. Notice that
-- # in order to be able to mark the end of the SP, the code has to set the delimiter to
-- # something other than a semi-colon; this is best done just before creating the SP,
-- # and reset immediately after. The DELIMITER command does not need a second
-- # terminator.
USE test ;
SET @err = 0 ;
SELECT 'Before running errhandlerdemo:', @err ;
CREATE TABLE IF NOT EXISTS testhandler (i INT, PRIMARY KEY(i)) ;
DELIMITER |
DROP PROCEDURE IF EXISTS errhandlerdemo ;
CREATE PROCEDURE errhandlerdemo()
BEGIN
DECLARE EXIT HANDLER FOR SQLSTATE '23000' SET @err=23000;
INSERT INTO testhandler VALUES( NULL) ;
SET @err=-1 ;
END ;
|
DELIMITER ;
CALL errhandlerdemo() |
DROP TABLE testhandler |
SELECT 'After running errhandlerdemo:', @err;
-- # EOF
-- 8-3:IF...THEN... in an SP
USE test;
DROP FUNCTION IF EXISTS is_even;
DELIMITER |
CREATE FUNCTION is_even( x INT ) RETURNS INT
BEGIN
DECLARE iRet INT DEFAULT 0;
IF x/2 = 0 THEN
SET iRet = 1;
END IF;
RETURN iRet;
END
|
DELIMITER ;
SELECT is_even( 3 );
-- #EOF
-- 8-4: CASE...WHEN...ENDCASE in an SP
USE test;
DROP PROCEDURE IF EXISTS case1proc;
DELIMITER |
CREATE PROCEDURE case1proc( IN x INT )
BEGIN
CASE x
WHEN 'string' THEN SELECT 'non-matching value will not execute';
WHEN 0 THEN SELECT 'matching value executes';
WHEN 17 THEN SELECT 'non-matching value will not execute';
END CASE;
END;
|
DROP PROCEDURE IF EXISTS case2proc |
CREATE PROCEDURE case2proc( IN x INT )
BEGIN
DECLARE s CHAR( 10 );
CASE
WHEN x < 0 THEN SET s = 'less than zero';
WHEN x < 10 THEN SET s = 'units';
WHEN x < 100 THEN SET s = 'tens';
WHEN x < 1000 THEN SET s = 'hundreds';
ELSE SET s = 'a thousand or more';
END CASE;
SELECT CONCAT( 'range is ', s );
END;
|
DELIMITER ;
CALL case1proc( 0 ); -- # output: matching value executes
CALL case2proc( 100 ); -- # output: range is hundreds
-- # EOF
-- 8-5: DO .. REPEAT
DELIMITER |
DROP PROCEDURE IF EXISTS dorepeat;
CREATE PROCEDURE dorepeat( IN imax INT )
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE s CHAR( 20 ) DEFAULT 'Loops:';
REPEAT
BEGIN
SET s = CONCAT_WS( ' ', s, i );
SET i = i + 1;
END;
UNTIL i > imax END REPEAT;
SELECT s;
END
|
DELIMITER ;
CALL dorepeat( 5 );
-- #EOF
-- 8-6: DO ... WHILE ...
USE test;
DROP PROCEDURE IF EXISTS whileproc;
DELIMITER |
CREATE PROCEDURE whileproc( IN x INT )
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE s CHAR( 20 ) DEFAULT "Loops:";
WHILE i-5 DO
BEGIN
SET i = i + 1;
SET s = CONCAT_WS( ' ', s, i );
END;
END WHILE;
SELECT s;
END;
|
DELIMITER ;
CALL whileproc( 5 ); -- output: Loops: 1 2 3 4 5
-- #EOF
-- 8-7: Cursor, handler, loop and iteration in an SP
USE test;
DROP TABLE IF EXISTS curtest1;
DROP TABLE IF EXISTS curtest2;
CREATE TABLE curtest1( i INT PRIMARY KEY, j INT, name CHAR(10) );
CREATE TABLE curtest2( x INT );
INSERT INTO curtest1 VALUES (0,0,'first'),(1,2,'second'),(2,1,'third');
DROP PROCEDURE IF EXISTS cursxmpl;
DELIMITER |
CREATE PROCEDURE cursxmpl()
BEGIN
DECLARE mi INT;
DECLARE mj INT;
DECLARE done INT DEFAULT 0;
DECLARE curs CURSOR FOR SELECT i, j FROM test.curtest1;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
OPEN curs;
loop0: WHILE NOT done DO
FETCH curs INTO mi, mj;
IF NOT done THEN
IF mi < mj THEN
INSERT INTO test.curtest2 VALUES (mi);
ELSEIF mi > mj THEN
INSERT INTO test.curtest2 VALUES (mj);
ELSE
ITERATE loop0;
END IF;
END IF;
END WHILE loop0;
CLOSE curs;
END;
|
DELIMITER ;
CALL cursxmpl();
SELECT * FROM curtest2;
-- # EOF
1、SQL映射文件中,使用select标签定义调用存储过程
(1)statementType=”CALLABLE”:表示要调用存储过程
(2){call procedure_name(params)}
2、编辑存储过程对象,用于保存存储过程的输入参数和输出参数
id last_name gender email 1 mike 0 [email protected] 2 book 0 [email protected] 3 tom 1 [email protected] 4 jerry 1 [email protected] 5 hhee 1 [email protected] 6 jerry4 1 [email protected] 7 smith0x1 1 [email protected] 8 mas 1 [email protected] 9 smith0x1 1 [email protected] 10 allen0x1 0 [email protected]
USE `mybatis`; DROP PROCEDURE IF EXISTS proc_employee; DELIMITER // CREATE PROCEDURE proc_employee(IN p_start INT, IN p_end INT,OUT p_count INT) BEGIN SELECT COUNT(*) INTO p_count FROM `tbl_employee`; SELECT * FROM ( SELECT a.* FROM `tbl_employee` a WHERE a.`id` < p_end) b WHERE b.`id` >p_start; END// DELIMITER ;
特别注意点:
开头部分:DELIMITER //【这两斜杠前面有空格,需要注意】 结尾部分:DELIMITER ;【分号前面也有个空格,需要注意】 在定义过程时,使用DELIMITER // 命令将语句的结束符号从分号 ; 临时改为//,使得过程体中使用的分号被直接传递到服务器,而不会被客户端(如mysql)解释。
set @p_count=1; CALL proc_employee(1,8,@p_count); select @p_count;
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <environments default="development"> <environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/mybatis" /> <property name="username" value="root" /> <property name="password" value="Cool123!" /> </dataSource> </environment> </environments> <!-- 5、databaseIdProvider:支持多数据库厂商的; type="DB_VENDOR":VendorDatabaseIdProvider 作用就是得到数据库厂商的标识(驱动getDatabaseProductName()),mybatis就能根据数据库厂商标识来执行不同的sql; MySQL,Oracle,SQL Server,xxxx --> <databaseIdProvider type="DB_VENDOR"> <!-- 为不同的数据库厂商起别名 --> <property name="MySQL" value="mysql"/> <property name="Oracle" value="oracle"/> <property name="SQL Server" value="sqlserver"/> </databaseIdProvider> <!-- 将我们写好的sql映射文件(EmployeeMapper.xml)一定要注册到全局配置文件(mybatis-config.xml)中 如果 数据库全局文件 和 子配置文件 不在同一个目录 ,就需要 /目录/目录/.../EmployeeMapper_old.xml --> <mappers> <!-- 新方法操作mybatis 需要 的配置文件 --> <mapper resource="EmployeeMapper.xml" /> </mappers> </configuration>
Employee.java
package com.mybatis.bean;
public class Employee {
private Integer id;
private String lastName;
private String email;
private String gender;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Employee(){
super();
}
public Employee(String lastName, String email, String gender) {
super();
this.lastName = lastName;
this.email = email;
this.gender = gender;
}
@Override
public String toString() {
return "Employee [id=" + id + ", lastName=" + lastName + ", email=" + email + ", gender=" + gender + "]";
}
}
存储过程的bean文件 ProcPage.java
package com.mybatis.bean;
import java.util.List;
/**
* 封装分页查询数据
* @author lfy
*
*/
public class ProcPage {
private int start;
private int end;
private int count;
private List<Employee> emps;
public int getStart() {
return start;
}
public void setStart(int start) {
this.start = start;
}
public int getEnd() {
return end;
}
public void setEnd(int end) {
this.end = end;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public List<Employee> getEmps() {
return emps;
}
public void setEmps(List<Employee> emps) {
this.emps = emps;
}
}
EmployeeMapper.java
package com.mybatis.mapper;
import java.util.List;
import com.mybatis.bean.Employee;
import com.mybatis.bean.ProcPage;
public interface EmployeeMapper {
public List<Employee> getPageByProcedure(ProcPage page);
}
EmployeeMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.mapper.EmployeeMapper">
<!-- public void getPageByProcedure();
1、使用select标签定义调用存储过程
2、statementType="CALLABLE":表示要调用存储过程
3、{call procedure_name(params)}
-->
<select id="getPageByProcedure" statementType="CALLABLE" databaseId="mysql" resultMap="PageEmp">
{
call proc_employee(
#{start,mode=IN,jdbcType=INTEGER},
#{end,mode=IN,jdbcType=INTEGER},
#{count,mode=OUT,jdbcType=INTEGER}
)
}
</select>
<resultMap type="com.mybatis.bean.Employee" id="PageEmp">
<id column="ID" property="id"/>
<result column="LAST_NAME" property="lastName"/>
<result column="EMAIL" property="email"/>
</resultMap>
</mapper>
package com.mybatis.test;
import java.io.IOException;
import java.io.InputStream;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import com.mybatis.bean.ProcPage;
import com.mybatis.mapper.EmployeeMapper;
/**
* 1、接口式编程
* 原生: Dao ====> DaoImpl
* mybatis: Mapper ====> xxMapper.xml
*
* 2、SqlSession代表和数据库的一次会话;用完必须关闭;
* 3、SqlSession和connection一样她都是非线程安全。每次使用都应该去获取新的对象。(就是不要放在共享成员变量里面,A线程用完释放,B线程再用就为空了)
* 4、mapper接口没有实现类,但是mybatis会为这个接口生成一个代理对象。
* (将接口和xml进行绑定)
* EmployeeMapper empMapper = sqlSession.getMapper(EmployeeMapper.class);
* 5、两个重要的配置文件:
* mybatis的全局配置文件:包含数据库连接池信息,事务管理器信息等...系统运行环境信息
* sql映射文件:保存了每一个sql语句的映射信息:
* 将sql抽取出来。
*
*/
public class MybatisTest {
public SqlSessionFactory getSqlSessionFactory() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
return new SqlSessionFactoryBuilder().build(inputStream);
}
/**
* mysql分页:
* 存储过程包装分页逻辑
* @throws IOException
*/
@Test
public void testProcedure() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession openSession = sqlSessionFactory.openSession();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
ProcPage page = new ProcPage();
page.setStart(5);
page.setEnd(8);
page.setEmps(mapper.getPageByProcedure(page));
System.out.println("总记录数:"+page.getCount());
System.out.println("查出的数据:"+page.getEmps().size());
System.out.println("查出的数据:"+page.getEmps());
}finally{
openSession.close();
}
}
}
基本和mysql相同,部分不相同。【因为存储过程不一样,存储过程对应有四个参数,导致后面的操作稍微不同】
create or replace procedure
proc_employee(p_start in int,
p_end in int,
p_count out int,
ref_cur out sys_refcursor) AS
BEGIN
select count(*) into p_count from tbl_employee;
open ref_cur for
select * from (select e.*,rownum as rn) from tbl_employee e where rownum <p_end)
where rn >p_start;
END proc_employee;
package com.mybatis.mapper;
import java.util.List;
import com.mybatis.bean.Employee;
import com.mybatis.bean.ProcPage;
public interface EmployeeMapper {
public void getPageByProcedure(ProcPage page);
}
<mapper namespace="com.mybatis.mapper.EmployeeMapper">
<!-- public void getPageByProcedure();
1、使用select标签定义调用存储过程
2、statementType="CALLABLE":表示要调用存储过程
3、{call procedure_name(params)}
-->
<select id="getPageByProcedure" statementType="CALLABLE" databaseId="oracle">
{call hello_test(
#{start,mode=IN,jdbcType=INTEGER},
#{end,mode=IN,jdbcType=INTEGER},
#{count,mode=OUT,jdbcType=INTEGER},
#{emps,mode=OUT,jdbcType=CURSOR,javaType=ResultSet,resultMap=PageEmp}
)}
</select>
<resultMap type="com.mybatis.bean.Employee" id="PageEmp">
<id column="EMPLOYEE_ID" property="id"/>
<result column="LAST_NAME" property="email"/>
<result column="EMAIL" property="email"/>
</resultMap>
</mapper>
/**
* oracle分页:
* 借助rownum:行号;子查询;
* 存储过程包装分页逻辑
* @throws IOException
*/
@Test
public void testProcedure() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession openSession = sqlSessionFactory.openSession();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
OraclePage page = new OraclePage();
page.setStart(1);
page.setEnd(5);
mapper.getPageByProcedure(page);
System.out.println("总记录数:"+page.getCount());
System.out.println("查出的数据:"+page.getEmps().size());
System.out.println("查出的数据:"+page.getEmps());
}finally{
openSession.close();
}
}