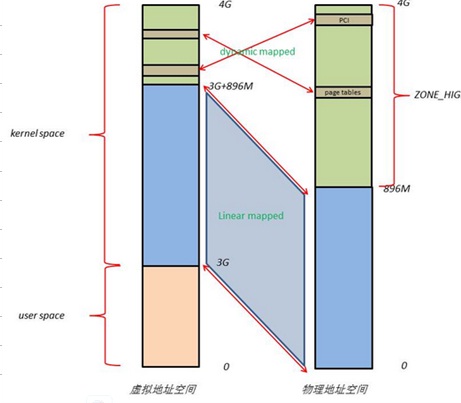
备注:维基百科下的一张long mode图片,在这篇文章中引用了两次,以后重新编辑时,注意一下。
一、逻辑/虚拟/线性/物理地址
- 逻辑地址就是 CS:IP
- 线性地址(也叫虚拟地址):由逻辑地址变化而来
- 物理地址:就是真正的内存地址,由线性地址变化而来
CS是段寄存器,IP是程序计数器也叫指令指针。
CS对应硬盘上程序文件内的代码段,数据段到内存的映射,IP就是程序文件的段内偏移。当然CS也包括程序运行时产生的堆栈段等。
程序文件头中的段重定位表,它可以包含多个数据段和代码段。程序加载到内存时:
1、8086前的CPU比如8080,没有实模式,直接CS:IP 计算出物理地址。
2、8086开始的CPU,有了实模式,即CS左移4位+IP段内偏移=物理地址。实模式下程序的物理内存地址由CS:IP指定,操作系统无法管理内存。
3、80286开始出现保护模式,操作系统加载程序后,填写到段描述表中(GDT,LDT),并将信息写回到程序内存中的段重定位表中,听说是这样的,到时再考证一下。
3.1.假如定义了多个代码段或者数据段,同一类型段的不同段中切换时,譬如data段1切换到data段2时,对DS的重新赋值,一般情况下是直接从应用程序头段中获取定义的重定位表项地址中取得。
3.2.应用程序在刚获取cpu执行权限时,首先设置堆栈空间SS\SP\DS\ES等寄存器,在设置SS\SP时应该先屏蔽中断,否则在设置SS和SP之间产生中断是个极其恐怖的事,因为有的设计中处理中断也是在当前堆栈空间中进行的。 譬如: 19. 19 00000010 [00000000]code_2_segment dd section.code_2.start ;[0x10] //从该地址中存放的内容,取出来放到CS和IP中。code_2_segment 本身是一个数据段定义。 参考资料:《X86汇编语言:从实模式到保护模式》【这个带考证是否实模式和保护模式都适用】
分段管理 = 逻辑地址变成线性地址的过程
分页管理 = 线性地址变成物理地址的过程
- 8086CPU 之前,没有分段管理,逻辑地址计算后变成物理地址=线性地址
- 8086CPU中,开始出现分段管理,线性地址 = 物理地址
- 80386CPU中,开始出现分页管理,所以线性地址≠物理地址
补充说明:
8080是8位微处理器,数据总线为8位,地址总线为16位。
8086是首枚16位微处理器,地址总线20位,数据总线16位,为了扩大内存寻址范围,才采用分段管理的方式。【补充常识:8088CPU内部数据总线16位,外部数据总线8位,仍算16位处理器】
有一个问题,8080没有采用分段,怎么解决寻址呢?
在微处理器的历史上,第一款微处理器芯片 4004 是由 Intel 推出的,那是一个 4 位 的微处理器。在 4004 之后,Intel 推出了一款 8 位处理器 8080,它有 1 个主累加器(寄存 器 A)和 6 个次累加器(寄存器 B,C,D,E,H 和 L),几个次累加器可以配对(如组成 BC, DE 或 HL)用来访问 16 位的内存地址,也就是说 8080 可访问到 64K 内的地址空间。另外,那时还没有段的概念,访问内存都要通过绝对地址, 因此程序中的地址必须进行硬编码(给出具体地址),而且也难以重定位,这就不难理 解为什么当时的软件大都是些可控性弱,结构简陋,数据处理量小的工控程序了。
二、实模式与保护模式
x86 CPU有实模式、保持模式、虚拟8086模式、系统管理模式等的分别。 x86 CPU只有在启动的时候才能进入实模式,一旦切换到保持模式就无法退出回到实模式。
80186 CPU使用的还是8086的内核,所以还是实模式,仍采用分段管理。
80286 CPU才开始出现保护模式,改进版的分段管理。
80386 CPU开始支持内存分页管理。
8086CPU(16位数据线,20位地址性)采用分段管理是为了扩大内存寻址范围。
80286CPU改进分段管理,是为了实现保护模式。
显然实模式≠分段管理,保护模式 ≠ 分页管理,那什么叫保护模式,什么叫实模式?
简单的讲,实模式就是8086CPU使用的模式。当然那时还没有实模式的叫法。只是后面出现了保护模式,所以旧的模式就叫实模式了。实模式即实际地址模式,用户写的代码中CS与IP寄存器组合成的地址即为实际的物理内存地址。
1、实模式简介:
- 16位寄存器
- 20位地址线,可访问1MB内存
- 通过CS/DS寄存器左移4位+IP寄存器的值生成20位访问地址
1M内存空间:包括了 bios-rom,引导系统,外设显存等等,需要继续,总结,整理,1M内存各事务的空间占用分布。。。
这里有两个问题值得注意:
1. CS<<4 + IP理论上来讲,最大可以表示的数值是0xFFFF0 + 0xFFFF = 0x10FFEF,即大约1M+64KB-16Bytes,然而由于地址线只有20根(A0~A19),这个地址最前面的1无法被表示,当CS=0xFFFF时,实际访问的地址0x10FFEF就变成了0xFFEF。即地址由卷回了0地址到64KB-16Bytes处。
这个问题引出了80286的A20 Gate
2. 由于程序可以任意修改当前的CS/DS值,所有程序可以使用全部1MB的内存,所以这个CPU几乎没有办法有效地支持多任务,因为两个程序一起运行的话很容易互相踩到内存。所以当时的使用的方式系统中同时运行的只有一个应用程序和一个DOS操作系统。操作系统和应用规定了各自能使用的内存地址范围,比如说DOS只使用高64KB的内存,其它的内存给应用程序使用。这样就可以互不影响。要想运行另一个应用程序必须先退出当前运行的应用程序。
这个问题引出了保护模式,保护模式的初衷就是保护一个进程的内存不被其他进程非法访问。
2、保护模式:
保护模式的目的【内存分配的控制权由程序指定变成系统分配】
1、保护一个进程的内存不被其他进程非法访问
2、方便实现多任务系统
80286的保护模式
在80286中,段式访存得到的改进,原来段寄存器+IP得到的地址不在是实际的物理地址,而是要经过一个转换层转换才变成一个物理地址。CS里面的内存不再是20位物理地址的高16位,而变成了段描述符表中的索引。
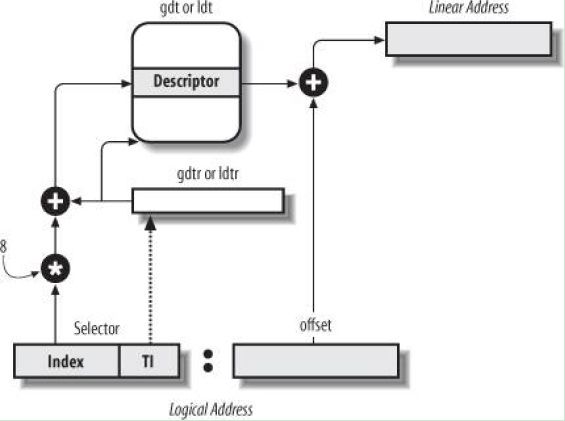
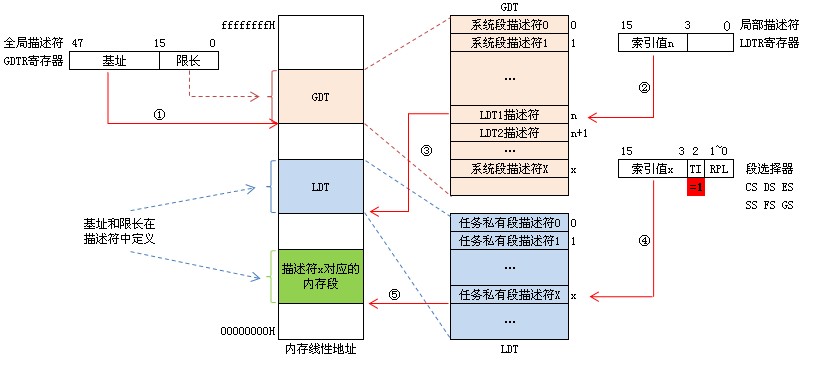
特别提醒:图中的段选择子(selector),作为索引index,查找GDT或LDT时,需要✖️8,因为段描述符(Descriptor)是64位的,占8个字节。
如图所示: 原来16位的段寄存器改名叫段选择子。现在是如何工作的,如何控制一个程序可以访问的内存范围呢?
答案: DOS系统在启动用户应用程序时先在内存中设置两个表,一个叫全局描述符表,GDT,一个叫局部描述符表LDT。表中的每个条目实际代表一段内存地址,包含这段内存的启始地址和段的长度,即base和limit。一个表的多个条目即代码这个用户程序可以访问的多块内存。
DOS系统把这两个表的内存启始地址写到LDTR和GDTR两个寄存器里。并在CS、DS寄存器中设置好一个初始的索引。
应用程序在访问内存时,CS:IP组合称为逻辑地址,CPU拿CS中的3~15位所组成的数据作为索引去LDT或GDT中找到一个描述符,拿这个描述符的base + IP做为实际的物理内存地址去访存。LDT和GDT只有DOS操作系统才能修改,因而应用程序只能访问DOS为它设置好的内存范围,而不能随意访问全部物理内存。
应用程序内存不够用时,需要调用一些系统调用,让DOS分配一段内存,把将这段内存的base, limit做成一个描述符加入到GDT或LDT中。
应用程序如果胡乱修改CS,造成无法索引到一个有效的段描述符就会发一个“段错误, segmentation fault”。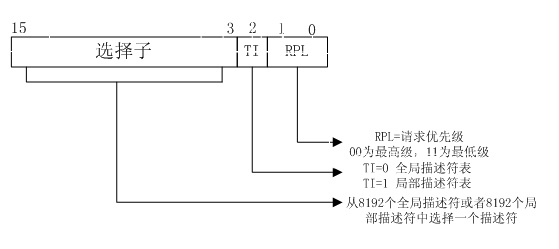
如图所示,在80286中,CS/DS/ES/FS寄存器的意义发生了变化。它的3~15位是描述符表的索引。TI用来表示索引的是哪一张表,是GDT还是LDT。RPL称为请求权限级别。RPL对应描述符中的DPL,只要RPL的级别高于(值小于)DPL时,才有权限访问这段内存。 描述符中的DPL如下图所示(都是64位的占8个字节,故计算偏移量需要index*8):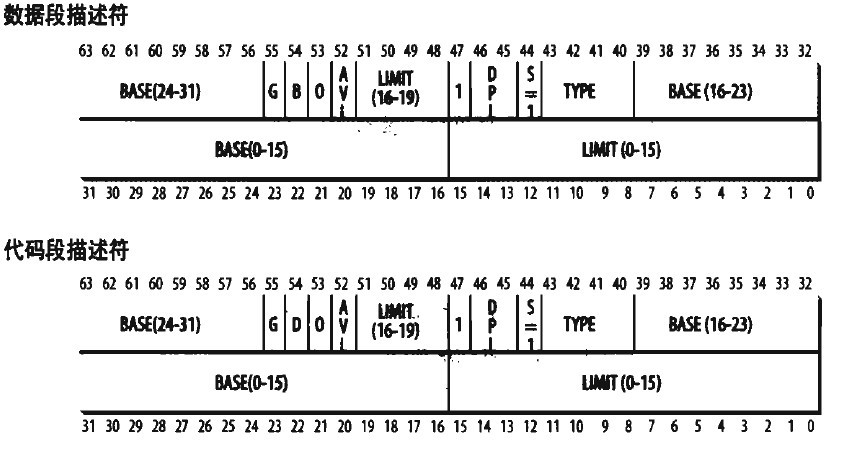
80286的多任务
借助段描述符表,系统可以为应用程序分配内存,并且限制用户对内存的访问。这时候,多任务的方式汇总如下图: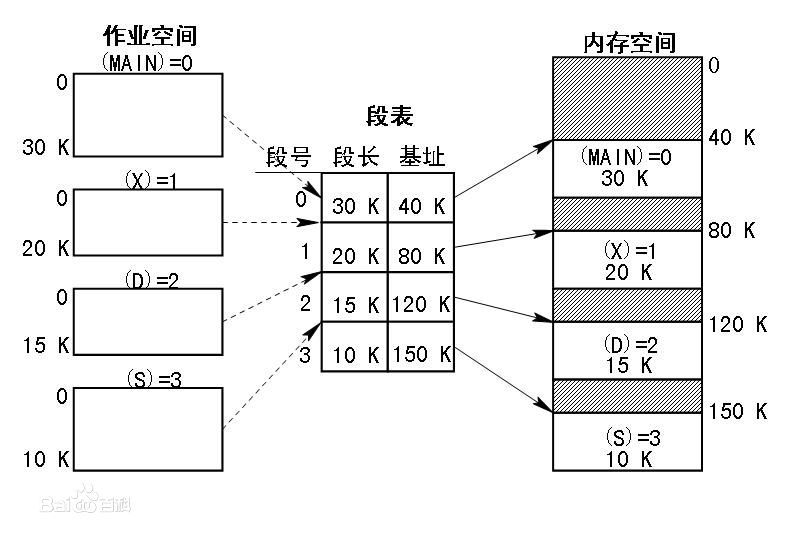
基于这种内存管理方式,用户应用程序可以实现动态链接。比如说一个程序分为代码段、数据段、零初始化段等,它依赖的库也是分段的,系统在加载程序时,只需为每个段分配一段内存,并为每个段设置一个描述符即可。 每个段的起始地址可以在加载时根据实际情况修改。
代码段设置成只读只需要其描述符的TYPE字段即可。
三、IA32介绍
从 80386 以后,Intel 的 CPU 经历了 80486、Pentium、PentiumII、PentiumIII 等型号,虽然 它们在速度上提高了好几个数量级,功能上也有不少改进,但基本上属于同一种系统结 构的改进与加强,而无本质的变化,所以我们把 80386 以后的处理器统称为 IA32(32 Bit Intel Architecture)。
IA32分段(48位逻辑地址->32位线性地址)
之前80286寻址方式大白话就是: 利用段寄存器(CS、DS、SS之类的)查找段表中的线性地址,因为没有分页,线性地址就等于物理地址。
正规点的说法:段选择子/器–> 段描述符【IA32也是这个分段思路,但是段选择器和段描述符等具体格式可能80286有所不同】
IA32分段原理图
下面的selector 就是段选择子(CS:IP中的CS),offset 就是段内偏移(CS:IP中的IP)
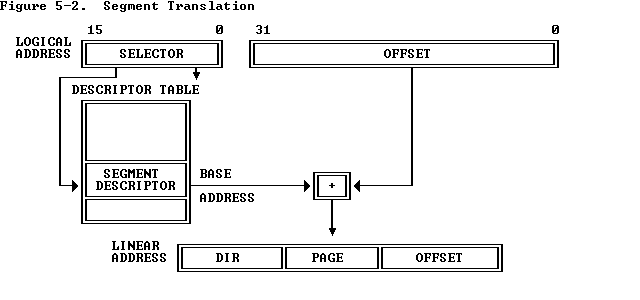
IA32段选择器
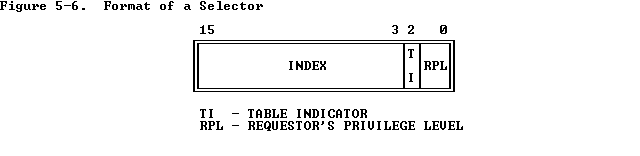
- 索引号(index):所对应的段描述符处于GDT或LDT中的索引。
- TI:TI=0表示对应段描述符保存在GDT(全局描述符表)中,TI=1表示对应的段描述符保存在LDT(局部描述符表)中。
- RPL:请求者的特权级,表示发起选择器的过程的权限级别。Selectors contain a field called the requestor’s privilege level (RPL). The RPL is intended to represent the privilege level of the procedure that originates a selector.
补充:
(1)段描述符中有DPL标记项( Descriptor Privilege Level ),这两位用于指定段的特权级。
(2)内部处理器寄存器记录当前特权级别(CPL,Current Privilege Level)。通常CPL等于处理器当前正在执行的段的DPL。当控制转移到具有不同DPL的段时,CPL会发生变化。
(3)处理器共支持4 种特权级别,分别是 0、 1、 2、 3,其中 0 是最高特权级别, 3 是最低特权级别。在linux系统中只分2级,CPL为0是最高权限(内核态使用),CPL为3是用户态使用。
(3)数据访问权限。仅当目标段的DPL在数值上大于或等于CPL和选择器的RPL的最大值时,指令才可以加载数据段寄存器(并随后使用目标段)。换句话说,过程只能访问处于相同或更低特权级别的数据。任务的可寻址域随着CPL的变化而变化。当CPL为零时,可以访问所有权限级别的数据段; 当CPL为1时,只能访问权限级别为1到3的数据段; 当CPL为3时,只能访问权限级别为3的数据段。例如,可以使用80386的此属性来防止应用程序过程读取或更改操作系统的表。
(4)代码执行权限。通常只能同级访问,除了系统调用和中断:当控制转移到符合要求的段时,CPL不会更改。这是CPL可能与当前可执行段的DPL不相等的唯一情况。
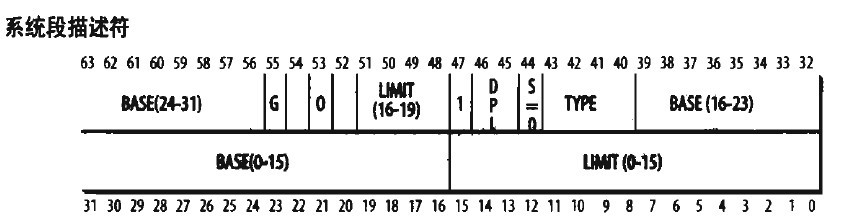
IA32段描述符
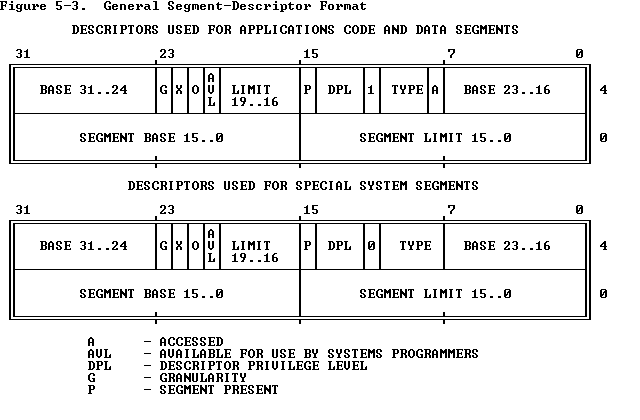
从图可以看出,一个段描述符指出了段的32位基地址和20位段界限(即段长)。
G位是粒度位,当G=0时,段长表示段格式的字节长度,即一个段最长 可达1M字节。当G=1时,段长表示段的以4K字节为一页的页的数目,即一个段最长可达 1M×4K=4G字节。
X位表示缺省操作数的大小,如果X=0,操作数为16位,如果X=1,操作数 为32位。
P位(Present) 是存在位,表示段描述符描述的这个段是否在内存中,如果在 内存中。P=1;如果不在内存中,P=0。
DPL(Descriptor Privilege Level),就是描述符特权级,它占两位,其值为0~3, 用来确定这个段的特权级即保护等级。
S位(System)表示这个段是系统段还是用户段。如果S=0,则为系统段,如果S=1,则 为用户程序的代码段、数据段或堆栈段。【S位也就是DPL后面那一位】
TYPE:它区分不同的描述符格式,它指定了段的预期用途。
A:A=1已被访问过,A=0未被访问过。
° 段描述符是一种数据结构,实际上就是段表项,分两类:
• 普通段:用户/内核的代码段和数据段描述符
• 系统控制段描述符,又分两种:
- 特殊系统控制段描述符,包括:局部描述符表(LDT)描述 --> Local Descriptor Table descriptors-->LDTD
符和任务状态段(TSS)描述符 -->Task state segment descriptors -->TSSD
- 控制转移类描述符,包括:调用门描述符、任务门描述符、
中断门描述符和陷阱门描述符
- LDT 描述符和TSS描述符,只能出现在 GDT中。
- 调用门和任务门可以出现在LDT中。
- 【特别强调一下:GDT中的存放的是 LDTD 和 TSSD,不是 LDT 和 TSS】
LDT描述符存放LDT的基地址:
linux从2.2版开始,Linux让所有的进程(或叫任务)都使用相同的逻辑地址空间,因此 就没有必要使用局部描述符表LDT。但内核中也用到LDT,那只是在VM86模式中运行 Wine,因为就是说在Linux上模拟运行Winodws软件或DOS软件的程序时才使用。
linux中所有进程共享默认 LDT 段。默认情况下,其中会包含一个空的段描述符。这个默认 LDT 段描述符存储在 GDT 中。Linux 所生成的 LDT 的大小是 24 个字节。默认有 3 个条目:
LDT[0] = 空
LDT[1] = 用户代码段
LDT[2] = 用户数据/堆栈段描述符
https://www.ibm.com/developerworks/cn/linux/l-memmod/index.html【问题是进程数限制这块内容,感觉不对啊】后来上网查询发现,linux2.2版本中,在GDT中为每个进程静态预分配了两项(一个是TSS,一个是LDT,为了符合intel 规范),因为GDT 表项有限制,所以 linux进程数有限制。
后来,linux内核改进了2.4版本,估计就演变成了 一个CPU带有一个TSS和一个GDT(GDT中带有一个默认的LDT)
http://www.newsmth.net/bbsanc.php?path=%2Fgroups%2Fcomp.faq%2FKernelTech%2Fothers%2FM.1018946573.v0
http://linux.ximizi.com/linux/linux2512.htm
TSS任务状态描述符存放任务的信息:
- 处理器寄存器状态
- I / O端口权限
- 内层堆栈指针
- 以前的TSS链接
目的是为了实现进程切换时,靠硬件实现任务信息切换,换进程就会将TSS切换。32位系统下,还有软切换:利用堆栈来保存任务信息。64位就只有软切换了,因为硬切换太慢。
该X86-64架构不支持硬件任务切换。但是,TSS仍可用于以64位扩展模式运行的机器。在这些模式中,TSS仍然有用,因为它存储:
- 堆栈指针针对每个权限级别进行寻址。
- 中断堆栈表的指针地址(上面的内层堆栈指针部分讨论了对此的需求)。
- 偏移IO权限位图的地址。
此外,在这些模式下扩展任务寄存器,以便能够保存64位基址。
每个 TSS 段 (TSS segment) 描述符都代表一个不同的进程。TSS 中保存了每个 CPU 的硬件上下文信息,它有助于有效地切换上下文。例如,在 U->K 模式的切换中,x86 CPU 就是从 TSS 中获取内核模式堆栈的地址。
进程恢复执行前必须装入寄存器的一组数据成为硬件上下文(hardware context)。硬件上下文是进程可执行上下文的一个自己,因为可执行上下文包含进程执行时所需要的所有信息。在Linux中,进程硬件上下午的一部分存放在TSS段,而剩余部分存放在内核态堆栈中。
早期Linux版本利用80×86体系结构所需提供的硬件支持,并通过far jmp指令跳到next进程TSS描述符的选择符来执行进程切换。当执行这条指令时,CPU通过自动保存原来的硬件上下文,装入新的硬件上下文来执行硬件上下文切换。但Linux2.6使用软件执行进程切换,原因有:
- 通过一组mov指令逐步执行切换,这样能较好地控制所装入的数据的合法性,一面被恶意用户伪造。far jmp指令不会有这样的检查。
- 旧方法和新方法所需时间大致相同。
进程切换值发生在内核态,在执行进程切换之前,用户态进程使用的所有寄存器内容已保存在内核堆栈上,这也包括ss和esp这对寄存器的内容。
http://guojing.me/linux-kernel-architecture/posts/process-switch/
任务状态段(TSS)
80x86体系结构包含了一个特殊的段类型,叫任务状态段(Task State Segment,TSS)来存放硬件上下文,尽管Linux并不使用硬件上下文切换,但是强制它为系统中每个不同的CPU创建一个TSS,这样做主要有两个理由:
当80x86的一个CPU从用户态切换到内核态时,它就从TSS中后去内核态堆栈的地址。
当用户态进程试图通过in或out指令访问一个I/O端口时,CPU需要访问存放在TSS中的I/O许可位图以检查该进程是否有访问端口的权利。
更确切的说,当进程在用户态执行in或out指令时,控制单元执行下列操作:
检查eflags寄存器中的2位IOPL字段,如果字段的值为3,控制单元就执行I/O指令。否则,执行下一个检查。
访问tr寄存器以确定当前的TSS和相应的I/O许可权位图。
检查I/O指令中指定的I/O端口在I/O许可权位图中对应的位,如果该位清,这条指令就执行,否则控制单元产生一个异常。
tss_struct结构描述TSS的格式,init_tss数组为系统上每个不同的CPU存放一个TSS。在每次进程切换时,内核都更新TSS的某些字段以便相应的CPU控制单元可以安全地检索到它需要的信息。因此,TSS反映了CPU上当前进程的特权级,但不必为没有在运行的进程保留TSS。
每个TSS有它自己8字节的任务状态段描述符(Task State Segment Descriptor,TSSD)。这个描述符包括指向TSS起始地址的32位Base字段,20位Limit字段。TSSD的S标志位被清0,以表示相应的TSS时系统段的事实。
Type字段被置位11或9以表示这个段实际上是一个TSS。在Intel的原始设计中,系统中的每个进程都应当指向自己的TSS;Type字段的第二个有效位叫Busy位;如果进程正由CPU执行,则该位置1,否则为0。在Linux的设计中,每个CPU只有一个TSS,因此Busy位总是为1.
由Linux创建的TSSD存放在全局描述符表(GDT)中,GDT的基地址存放在每个CPU的gdtr寄存器中。每个CPU的tr寄存器包含相应TSS的TSSD选择符,也包含了两个隐藏的非编程字段:TSSD的Base字段和Limit字段。这样,处理器就能够直接TSS寻址而不需要从GDT中检索TSS地址。
thread字段
在每次进程切换时,被替换的进程的硬件上下文必须保存在别处。不能像Intel原始设计那样保存在TSS中,因为Linux为每个处理器而不是为每个进程使用TSS。
因此,每个进程描述符包含一个类型为thread_struct的thread字段,只要进程被切换出去,内核就把其硬件上下文保存在这个结构中。随后可以看到,这个数据结构包含的字段涉及大部分CPU寄存器,但不包括eax、ebx等等这些通用寄存器。它们的值保留在内核堆栈中。
执行进程切换
进程切换可能只发生在精心定义的点:schedule()函数,这个函数很长,会在以后更长的篇幅里讲解。。这里,只关注内核如何执行一个进程切换。
进程切换由两步组成:
切换页全局目录以安装一个新的地址空间。
切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器。
综上所述,linux系统中 一个CPU 带一个GDT 和TSS (GDT中有一个默认的LDT ,并被所有进程共享,进程切换入的信息保存在TSS中,进程切换出的信息保存在thread字段中)【按intel的设计,每一个进程都该有一个LDT和TSS】
The TSS may reside anywhere in memory. A special segment register called the task register (TR) holds a segment selector that points to a valid TSS segment descriptor which resides in the GDT (a TSS descriptor may not reside in the LDT). Therefore, to use a TSS the following must be done by the operating system kernel:
Create a TSS descriptor entry in the GDT
Load the TR with the segment selector for that segment
Add information to the TSS in memory as needed
For security purposes, the TSS should be placed in memory that is accessible only to the kernel.
TR 寄存器的内容是 选择子(相当于任务门描述符中的选择子,看了下英文图文中 task gate 和 task gate descriptor 居然是一个意思)–>指向 TSS描述符(TSSD在GDT中)–>指向 内存中的 TSS
参考:https://bbs.pediy.com/thread-62510.htm
来自:http://www.logix.cz/michal/doc/i386/chp07-03.htm
80386 32-Bit Task State Segment
31 23 15 7 0
+---------------+---------------+---------------+-------------+-+
| I/O MAP BASE | 0 0 0 0 0 0 0 0 0 0 0 0 0 |T|64
|---------------+---------------+---------------+-------------+-|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| LDT |60
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| GS |5C
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| FS |58
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| DS |54
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| SS |50
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| CS |4C
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| ES |48
|---------------+---------------+---------------+---------------|
| EDI |44
|---------------+---------------+---------------+---------------|
| ESI |40
|---------------+---------------+---------------+---------------|
| EBP |3C
|---------------+---------------+---------------+---------------|
| ESP |38
|---------------+---------------+---------------+---------------|
| EBX |34
|---------------+---------------+---------------+---------------|
| EDX |30
|---------------+---------------+---------------+---------------|
| ECX |2C
|---------------+---------------+---------------+---------------|
| EAX |28
|---------------+---------------+---------------+---------------|
| EFLAGS |24
|---------------+---------------+---------------+---------------|
| INSTRUCTION POINTER (EIP) |20
|---------------+---------------+---------------+---------------|
| CR3 (PDPR) |1C
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| SS2 |18
|---------------+---------------+---------------+---------------|
| ESP2 |14
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| SS1 |10
|---------------+---------------+---------------+---------------|
| ESP1 |0C
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| SS0 |8
|---------------+---------------+---------------+---------------|
| ESP0 |4
|---------------+---------------+---------------+---------------|
|0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0| BACK LINK TO PREVIOUS TSS |0
+---------------+---------------+---------------+---------------+
----------------------------------------------------------------------------
NOTE
0 MEANS INTEL RESERVED. DO NOT DEFINE.
----------------------------------------------------------------------------
TSS Descriptor for 32-bit TSS
31 23 15 7 0
+-----------------+-+-+-+-+---------+-+-----+---------+-----------------+
| | | | |A| LIMIT | | | TYPE | |
| BASE 31..24 |G|0|0|V| |P| DPL | | BASE 23..16 | 4
| | | | |L| 19..16 | | |0|1|0|B|1| |
|-----------------+-+-+-+-+---------+-+-----+-+-+-+-+-+-----------------|
| | |
| BASE 15..0 | LIMIT 15..0 | 0
| | |
+-----------------+-----------------+-----------------+-----------------+
Task Register
+-------------------------+
| |
| |
| TASK STATE |
| SEGMENT |<---------+
| | |
| | |
+-------------------------+ |
16-BIT VISIBLE ^ |
REGISTER | HIDDEN REGISTER |
+--------------------+---------+----------+-------------+------+
TR | SELECTOR | (BASE) | (LIMT) |
+---------+----------+--------------------+--------------------+
| ^ ^
| +-----------------+ |
| GLOBAL DESCRIPTOR TABLE | |
| +-------------------------+ | |
| | TSS DESCRIPTOR | | |
| +------+-----+-----+------+ | |
| | | | | |---+ |
| |------+-----+-----+------| |
+------->| | |-------+
+------------+------------+
| |
+-------------------------+
Task Gate Descriptor
31 23 15 7 0
+-----------------+----------------+-+-----+---------+-----------------+
|##################################| | | |#################|
|############(NOT USED)############|P| DPL |0 0 1 0 1|###(NOT USED)####| 4
|##################################| | | |#################|
|----------------------------------+-+-----+---------+-----------------|
| |###################################|
| SELECTOR |############(NOT USED)#############| 0
| |###################################|
+-----------------+----------------+-----------------+-----------------+
Task Gate Indirectly Identifies Task
LOCAL DESCRIPTOR TABLE INTERRUPT DESCRIPTOR TABLE
+-------------------------+ +-------------------------+
| | | |
| TASK GATE | | TASK GATE |
+------+-----+-----+------+ +------+-----+-----+------+
| | | | | | | | | |
|------+-----+-----+------| |------+-----+-----+------|
+--| | | +--| | |
| +------------+------------+ | +------------+------------+
| | | | | |
| | | | | |
| +-------------------------+ | +-------------------------+
+----------------+ +-----------------+
| | GLOBAL DESCRIPTOR TABLE
| | +-------------------------+
| | | |
| | | TASK DESCRIPTOR |
| | +------+-----+-----+------+
| | | | | | |
| +->|------+-----+-----+------|
+---->| | |--+
+------------+------------+ |
| | |
| | |
+-------------------------+ |
|
+-------------------------+ |
| | |
| | |
| | |
| TASK STATE | |
| SEGMENT | |
| | |
| | |
| | |
+-------------------------+<-+
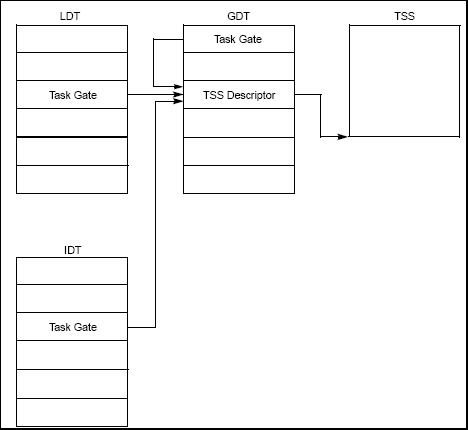
四类门描述符:
陷阱门:处理异常(除了双重故障(#DF)异常用任务门实现)
中断门:处理中断。
中断门和陷阱门只有在中断描述符表IDT中才有效。
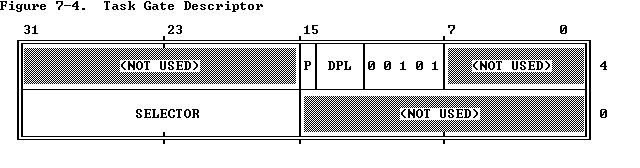
任务门:任务门指示任务。任务门内的选择子必须指示GDT中的任务状态段TSS描述符,门中的偏移无意义。任务的入口点保存在TSS中。利用段间转移指令JMP和段间调用指令CALL,通过任务门可实现任务切换。
调用门:描述某个子程序的入口。调用门内的选择子必须实现代码段描述符,调用门内的偏移是对应代码段内的偏移。利用段间调用指令CALL,通过调用门可实现任务内从外层特权级变换到内层特权级。对于在x86特权级别之间转移控制特别重要,尽管在大多数现代操作系统上都没有使用这种机制。
IA32之GDT、LDT、IDT
全局描述符表(GDT)
1、只有一个,用来存放系统内每个任务共用的
2、描述符,例如,内核代码段、内核数据段、用户代码段、用户数据段以及TSS(任务状态段)等都属于GDT中描述的段。
GDTR是指向GDT基地址的寄存器,存放的是线性地址。
局部描述符表(LDT)
存放某任务(即用户进程)专用的描述符。
LDTR是存放LDT在GDT中的描述符,相当于段选择子,里面存放的是LDT基地址的线性地址。
intel建议每一个进程都有1个LDT和TSS,当然 TSS 和 LDT 的描述符都在GDT上,按理说 用户代码段和数据段应该放在 LDT上,不过 LDT 在linux中不怎么需要,所以就用户代码和数据段都放在了GDT上。
 来自:http://ju.outofmemory.cn/entry/111444
来自:http://ju.outofmemory.cn/entry/111444
中断描述符表(IDT)
包含256个中断门、陷阱门和任务门描述符。IR寄存器存放的是IDT基地址的线性地址。
陷阱门和中断门在IDT中: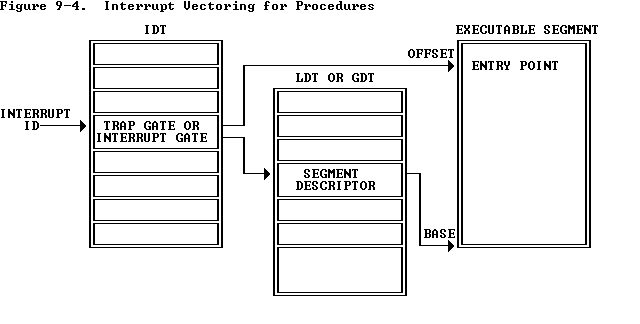
任务门在LDT或IDT中:
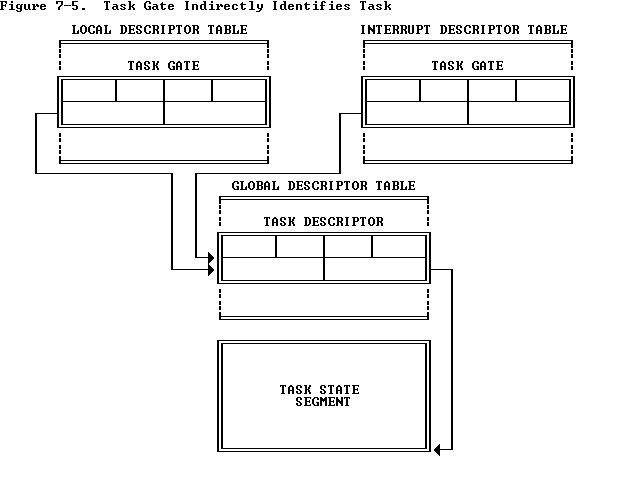
调用门在LDT和GDT中: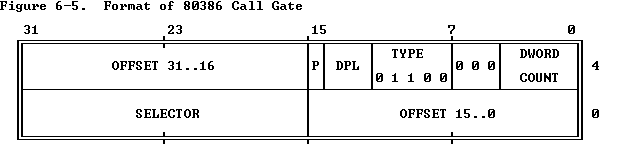
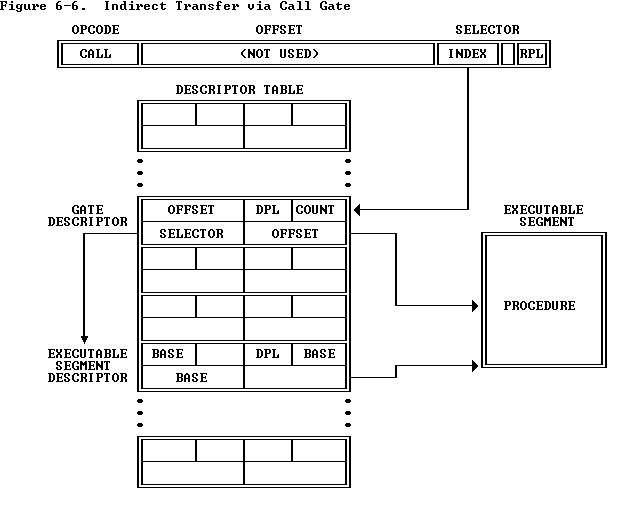
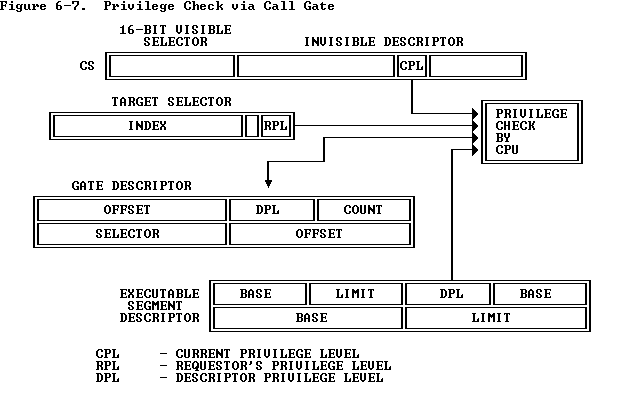 参考自:
参考自:
- https://pdos.csail.mit.edu/6.828/2005/readings/i386/s06_03.htm
- https://css.csail.mit.edu/6.858/2014/readings/i386/s07_04.htm
- https://pdos.csail.mit.edu/6.828/2005/readings/i386/s09_06.htm
IA32分段中的缓存机制
段选择器(selector)【也就是段寄存器】在查找段描述表(descriptor table)的描述符(segment descriptor)时,会将第一遍查找到的结果缓存到段选择器的不可见部分,这样后面就不用查段描述符表了,直接从段选择器的缓存中读取。
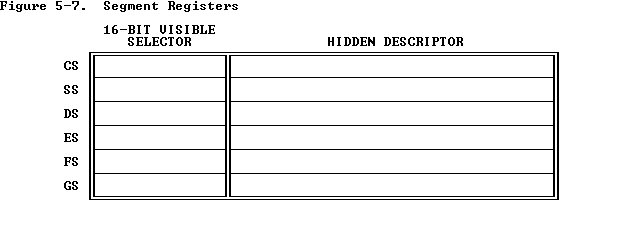
linux中的分段机制
Linux中的异常和中断处理
• Linux利用陷阱门来处理异常,利用中断门来处理中断。
• 异常和中断对应处理程序都属于内核代码段,所以,所有中断门和陷阱门
的段选择符(0x60)都指向GDT 中的“内核代码段”描述符。
• 通过中断门进入到一个中断服务程序时,CPU 会清除EFLAGS 寄存器中
的IF 标志,即关中断;通过陷阱门进入一个异常处理程序时,CPU 不会
修改IF 标志。也就是说,外部中断不支持嵌套处理,而内部异常则支持
嵌套处理。
• 任务门描述符中不包含偏移地址,只包含TSS 段选择符,这个段选择符
指向GDT 中的一个TSS 段描述符,CPU 根据TSS 段中的相关信息装载
SS 和ESP 等寄存器,从而执行相应的异常处理程序。
• Linux中,将类型号为8的双重故障(#DF)用任务门实现,而且是唯一
通过任务门实现的异常。
• 双重故障TSS 段描述符在GDT 中位于索引值为0x1f 的表项处,即13
位索引为0 0000 0001 1111,且其TI=0(指向GDT),RPL=00(内
核级代码),即任务门描述符中的段选择符为00F8H。
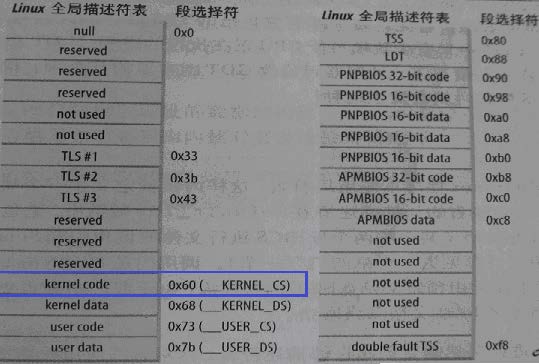
为什么 use data 是 0x7b =123 【15*8 +3】,为什么要加 3,内核段却没有加 3 https://stackoverflow.com/questions/11735729/segment-definitions-for-linux-on-x86
其实上面的0x7b =123 【15*8 +3】 是用户数据段的选择子 selector,而GDT中用户数据段的描述符descriptor地址是 GDT基地址+15*8
也就是说GDT中的描述符不存在内存空隙,都是紧密排列的。除了GDT中第一项8个字节留空。
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8+3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8+3)
其实是 理解问题:
GDT中的USER_DS 的descriptor是 基地址 + index * 8【因为一个GDT项占8个字节】
而用户程序的DS ,即数据段寄存器 是【高13位是索引,位3是指向GDT还是LDT,低2位是权限】
即 【 0000 0000 0111 1011 】 高13位是index索引 ,乘8是左移3位的意思,
011 中 0代表指向GDT表,11代表RPL的权限是用户态。
所以 GDT_ENTRY_DEFAULT_USER_DS*8+3 结果是 数据段的选择子(符)【selector】
至于KERNEL_DS,因为 位3是0代表指向GDT,低2位都是0,代表RPL是内核态。所以只要index*8就行了
参考:https://wenku.baidu.com/view/9b369289680203d8ce2f24d4.html
唯一的问题是:CS:IP。因为设置成CS=0,那么IP成了线性地址,每个进程的线性地址都不同,难道IP重定位了。
因为很多RISC处理器并不支持段机制。但是对段机制相关知识的了解是进入 Linux内核的必经之路。
从2.2版开始,Linux让所有的进程(或叫任务)都使用相同的逻辑地址空间,因此 就没有必要使用局部描述符表LDT。但内核中也用到LDT,那只是在VM86模式中运行 Wine,因为就是说在Linux上模拟运行Winodws软件或DOS软件的程序时才使用。
Linux的设计人员让段的基地址为0,而段的界限为 4GB,这时任意给出一个偏移量,则等式为“0+偏移量=线性地址”,也就是说“偏移量 =线性地址”。另外由于段机制规定“偏移量 < 4GB”,所以偏移量的范围为0H~ FFFFFFFFH,这恰好是线性地址空间范围,也就是说虚拟地址直接映射到了线性地址, 我们以后所提到的虚拟地址和线性地址指的也就是同一地址。
Linux在启动的过程中设置了段寄存器的值和全局描述符表GDT的内容,段的定义在 include/asm-i386/segment.h中:
#define __KERNEL_CS 0x10 /*内核代码段,index=2,TI=0,RPL=0*/
#define __KERNEL_DS 0x18 /*内核数据段, index=3,TI=0,RPL=0*/
#define __USER_CS 0x23 /*用户代码段, index=4,TI=0,RPL=3*/
#define __USER_DS 0x2B /*用户数据段, index=5,TI=0,RPL=3*/
从定义看出,没有定义堆栈段,实际上,Linux内核不区分数据段和堆栈段,这也体 现了Linux内核尽量减少段的使用。因为没有使用LDT,因此,TI=0,并把这4个段都放在 GDT中, index就是某个段在GDT表中的下标。内核代码段和数据段具有最高特权,因此其 RPL为0,而用户代码段和数据段具有最低特权,因此其RPL为3。可以看出,Linux内核再次简化了特权级的使用,使用了两个特权级而不是4个。
全局描述符表的定义在arch/i386/kernel/head.S中:
ENTRY(gdt_table)
.quad 0x0000000000000000 /* NULL descriptor */
.quad 0x0000000000000000 /* not used */
.quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at
0x00000000 */
.quad 0x00cf92000000ffff /* 0x18 kernel 4GB data at
0x00000000 */
.quad 0x00cffa000000ffff /* 0x23 user 4GB code at
0x00000000 */
.quad 0x00cff2000000ffff /* 0x2b user 4GB data at
0x00000000 */
.quad 0x0000000000000000 /* not used */
.quad 0x0000000000000000 /* not used */
/*
* The APM segments have byte granularity and their bases
* and limits are set at run time.
*/
.quad 0x0040920000000000 /* 0x40 APM set up for bad BIOS's
*/
.quad 0x00409a0000000000 /* 0x48 APM CS code */
.quad 0x00009a0000000000 /* 0x50 APM CS 16 code (16 bit) */
.quad 0x0040920000000000 /* 0x58 APM DS data */
.fill NR_CPUS*4,8,0 /* space for TSS's and LDT's */
从代码可以看出,GDT放在数组变量gdt_table中。按Intel规定,GDT中的第一项为空, 这是为了防止加电后段寄存器未经初始化就进入保护模式而使用GDT的。第二项也没用。从 下标2到5共4项对应于前面的4种段描述符值。从描述符的数值可以得出:
段的基地址全部为0x00000000
段的上限全部为0xffff
段的粒度G为1,即段长单位为4KB
段的D位为1,即对这四个段的访问都为32位指令
段的P位为1,即四个段都在内存。
按Intel的规定,每个进程有一个任务状态段(TSS)和局部描述符表LDT,但Linux 也没有完全遵循Intel的设计思路。如前所述,Linux的进程没有使用LDT,而对TSS的使用也非常有限,每个CPU仅使用一个TSS。
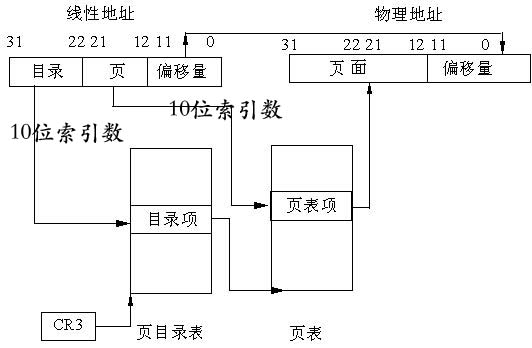
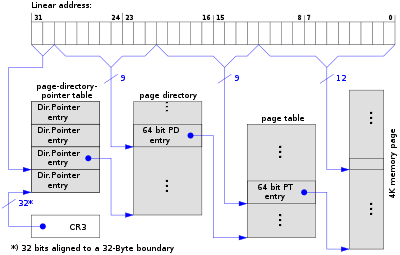
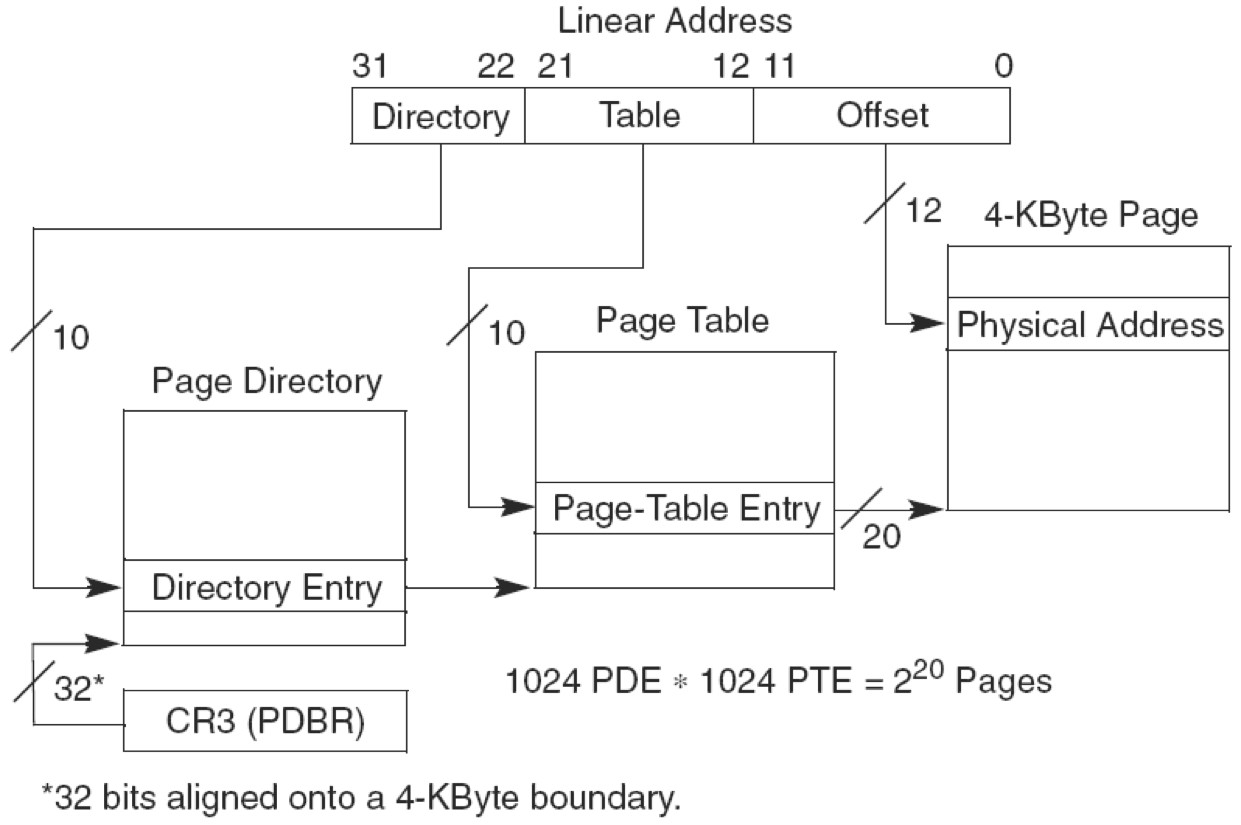
IA32分页(32位线性地址->32位物理地址)
有《深入理解LINUX内存管理》到时去看看。
分段情况:
linux 从2.2版开始,Linux让所有的进程(或叫任务)都使用相同的逻辑地址空间,也就是基地址 =0,偏移地址 =线性地址。
分页情况:
一个问题:0.12版本的linux 只有 1张页目录表,cr3 就一个值。现在一个进程一张页目录表,cr3切换多个值。https://www.zhihu.com/question/24622613
看了一下书,大致说,线性地址相同的进程,采用了不同的页目录,所以两者的物理地址是不同的。这就是CR3 多个的解释。
Linux内核软件架构习惯与分成硬件相关层和硬件无关层。对于页表管理,2.6.10以前(包括2.6.10)在硬件无关层使用了3级页表目录管理的方式,它不管底层硬件是否实现的也是3级的页表管理:
linux在 x86 架构上,pmd 在硬件中并不存在,但是在内核代码中它是与 pgd 合并在一起的。
为了支持大内存区域,Linux 也采用了这种三级分页机制。在不需要为大内存区域时,即可将 pmd 定义成“1”,返回两级分页机制。
linux分页级别是在编译时进行优化的,我们可以通过启用或禁用中间目录来启用两级和三级分页(使用相同的代码)。32 位处理器使用的是 pmd 分页,而 64 位处理器使用的是 pgd 分页。
Page Global Directory (PGD)
Page Middle Directory (PMD)
Page Table (PTE)
从2.6.11开始,为了配合64位CPU的体系结构,硬件无关层则使用了4级页表目录管理的方式:
Page Global Directory (PGD)
Page Upper Directory (PUD)
Page Middle Directory (PMD)
Page Table (PTE)
IA32分页寄存器
参考:
http://blog.sina.com.cn/s/blog_85998e38010122wq.html 【不准确】
https://en.wikipedia.org/wiki/Control_register
CR0(32位中最高位PG代表是否分页,最低位PE代表是否分段)
x86_32的CR0为32bit。X86_64下为64bit,其中低32bit与x86_32的CR0保持一致,高32bit没有定义,作保留使用,除了bit4其他所有位都是可读可写的。
Protected-Mode Enable (PE) Bit. Bit 0. PE=0,表示CPU处于实模式; PE=1表CPU处于保护模式,并使用分段机制。
Paging Enable (PG) Bit. Bit 31. 该位控制分页机制,PG=1,启动分页机制;PG=0,不使用分页机制。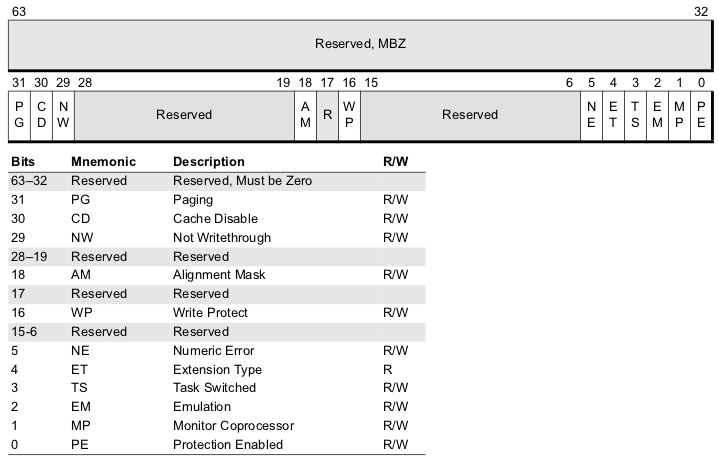
CR2(存放发生页错误时的虚拟地址)
下面应该是32位和64位的情况下

CR3(存放最高级页目录地址(物理地址)或页目录指针地址)
各级页表项中存放的也是物理地址。格式如下:【PAE 代表 物理地址扩展技术】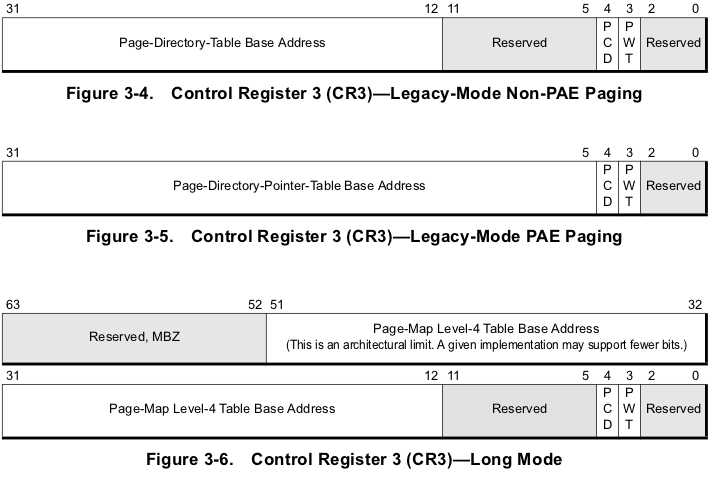
Page-Level Writethrough (PWT) Bit. Bit 3. Page-level writethrough indicates whether the highest-level page-translation table has a writeback or writethrough caching policy. When PWT=0, the table has a writeback caching policy. When PWT=1, the table has a writethrough caching policy.
Page-Level Cache Disable (PCD) Bit. Bit 4. PCD=1,表示最高目录表不可缓存,PCD=0,相反。
图3-4中不使用PAE技术,有两层页表。最高层为页目录有1024项,占用4KB。page_directory_table base address为物理地址,指向4KB对齐的页目录地址。
图3-5中,使用PAE技术,三层页表寻址。最高层为页目录指针,4项,占用32B空间。所以 page_directory_table base address为27位,指向32B对齐的页目录指针表。
Typically, the upper 20 bits of CR3 become the page directory base register (PDBR), which stores the physical address of the first page directory entry. If the PCIDE bit in CR4 is set, the lowest 12 bits are used for the process-context identifier(PCID).
CR4(legacy mode 下低32位与x86_32的CR4一致)
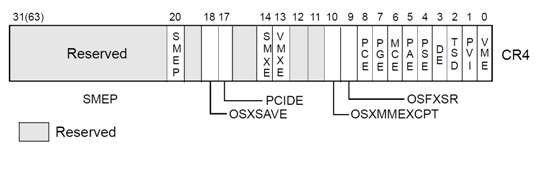
- Page-Size Extensions (PSE) Bit. Bit 4. PSE=1,启用PSE,PSE=0,不启用。
- Physical-Address Extension (PAE) Bit. Bit 5.PAE=1,启用PAE,支持2MB的超级页(superpage);PAE=0,不启用PAE。
| Bit |
Name |
Full Name |
Description |
| 0 |
VME |
Virtual 8086 Mode Extensions |
If set, enables support for the virtual interrupt flag (VIF) in virtual-8086 mode. |
| 1 |
PVI |
Protected-mode Virtual Interrupts |
If set, enables support for the virtual interrupt flag (VIF) in protected mode. |
| 2 |
TSD |
Time Stamp Disable |
If set, RDTSC instruction can only be executed when in ring 0, otherwise RDTSC can be used at any privilege level. |
| 3 |
DE |
Debugging Extensions |
If set, enables debug register based breaks on I/Ospace access. |
| 4 |
PSE |
Page Size Extension |
If unset, page size is 4 KiB, else page size is increased to 4 MiBIf PAE is enabled or the processor is in x86-64 long mode this bit is ignored. |
| 5 |
PAE |
Physical Address Extension |
If set, changes page table layout to translate 32-bit virtual addresses into extended 36-bit physical addresses. |
| 6 |
MCE |
Machine Check Exception |
If set, enables machine check interrupts to occur. |
| 7 |
PGE |
Page Global Enabled |
If set, address translations (PDE or PTE records) may be shared between address spaces. |
| 8 |
PCE |
Performance-Monitoring Counter enable |
If set, RDPMC can be executed at any privilege level, else RDPMC can only be used in ring 0. |
| 9 |
OSFXSR |
Operating system support for FXSAVE and FXRSTOR instructions |
If set, enables Streaming SIMD Extensions (SSE) instructions and fast FPU save & restore. |
| 10 |
OSXMMEXCPT |
Operating System Support for Unmasked SIMD Floating-Point Exceptions |
If set, enables unmasked SSE exceptions. |
| 11 |
UMIP |
User-Mode Instruction Prevention |
If set, the SGDT, SIDT, SLDT, SMSW and STR instructions cannot be executed if CPL > 0. |
| 12 |
LA57 |
(none specified) |
If set, enables 5-Level Paging. |
| 13 |
VMXE |
Virtual Machine Extensions Enable |
see Intel VT-x x86 virtualization. |
| 14 |
SMXE |
Safer Mode Extensions Enable |
see Trusted Execution Technology (TXT) |
| 16 |
FSGSBASE |
Enables the instructions RDFSBASE, RDGSBASE, WRFSBASE, and WRGSBASE. |
| 17 |
PCIDE |
PCID Enable |
If set, enables process-context identifiers (PCIDs). |
| 18 |
OSXSAVE |
XSAVE and Processor Extended States Enable |
|
| 20 |
SMEP |
Supervisor Mode Execution Protection Enable |
If set, execution of code in a higher ring generates a fault. |
| 21 |
SMAP |
Supervisor Mode Access PreventionEnable |
If set, access of data in a higher ring generates a fault. |
| 22 |
PKE |
Protection Key Enable |
See Intel 64 and IA-32 Architectures Software Developer’s Manual. |
EFER(Extended Feature Enable Register)-Additional Control registers in x86-64 series
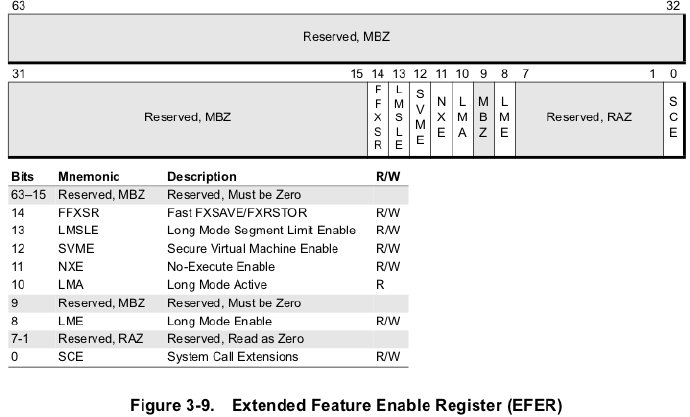
Long Mode Enable (LME) Bit. Bit 8. LME=1,启用long mode,注意必须先将CR0.PG=0后才能设置LME=1,然后再设置CR0.PG=1,则进入long mode。LME=0 ,使用legacy mode。【CPU的 long mode 给 64位操作系统用,legacy mode给32位或16位操作系统用】维基百科中有详细解释Long mode 和 Legacy mode
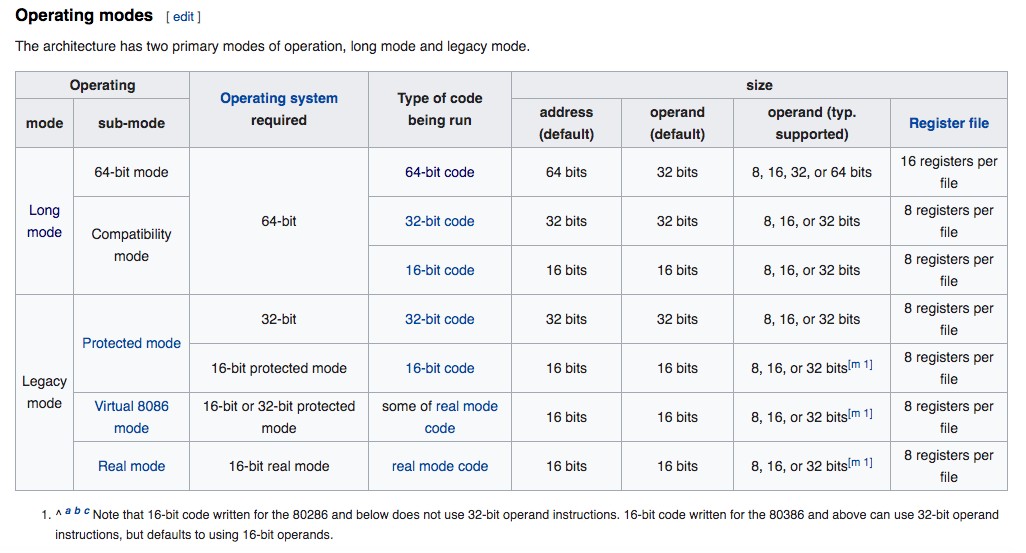
IA32分页模型
分页控制器总结:
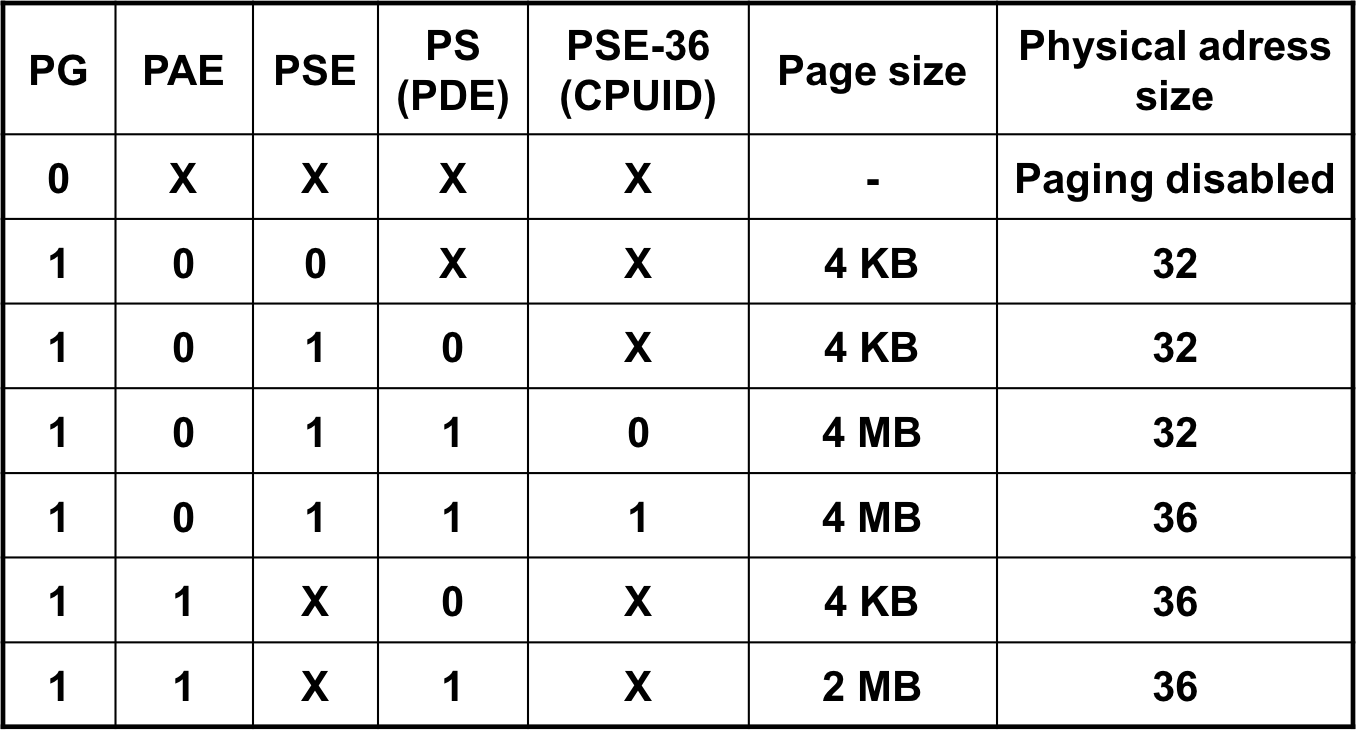
概况一下:
1、要开启分页,必须 激活 PG位。
2、PAE 未激活下,必须同时开启PSE和PE,页大小才能变成4MB,如果还开启PSE-36,则物理地址还会变成36位。
3、开始PAE后,物理地址就直接变成了36位,至于页大小直接看PS是否激活。
常规分页:
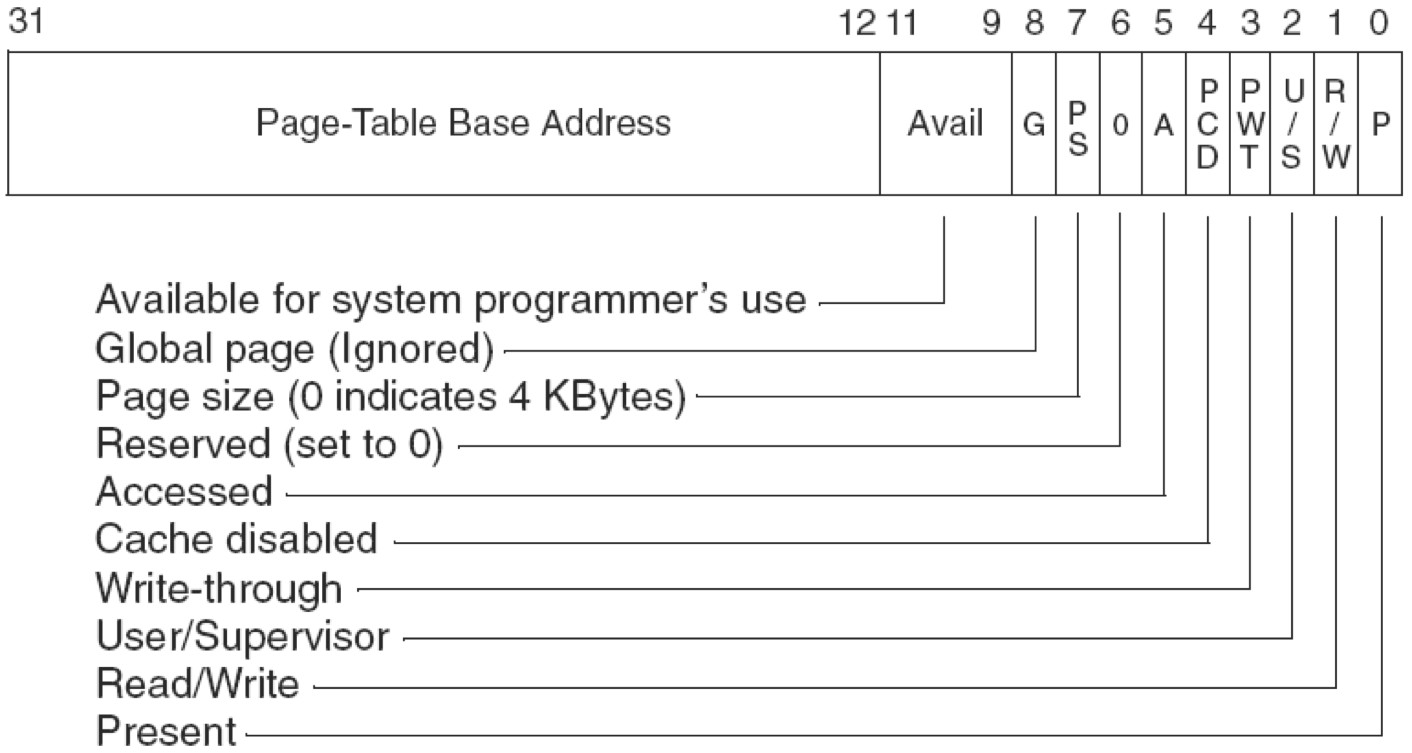
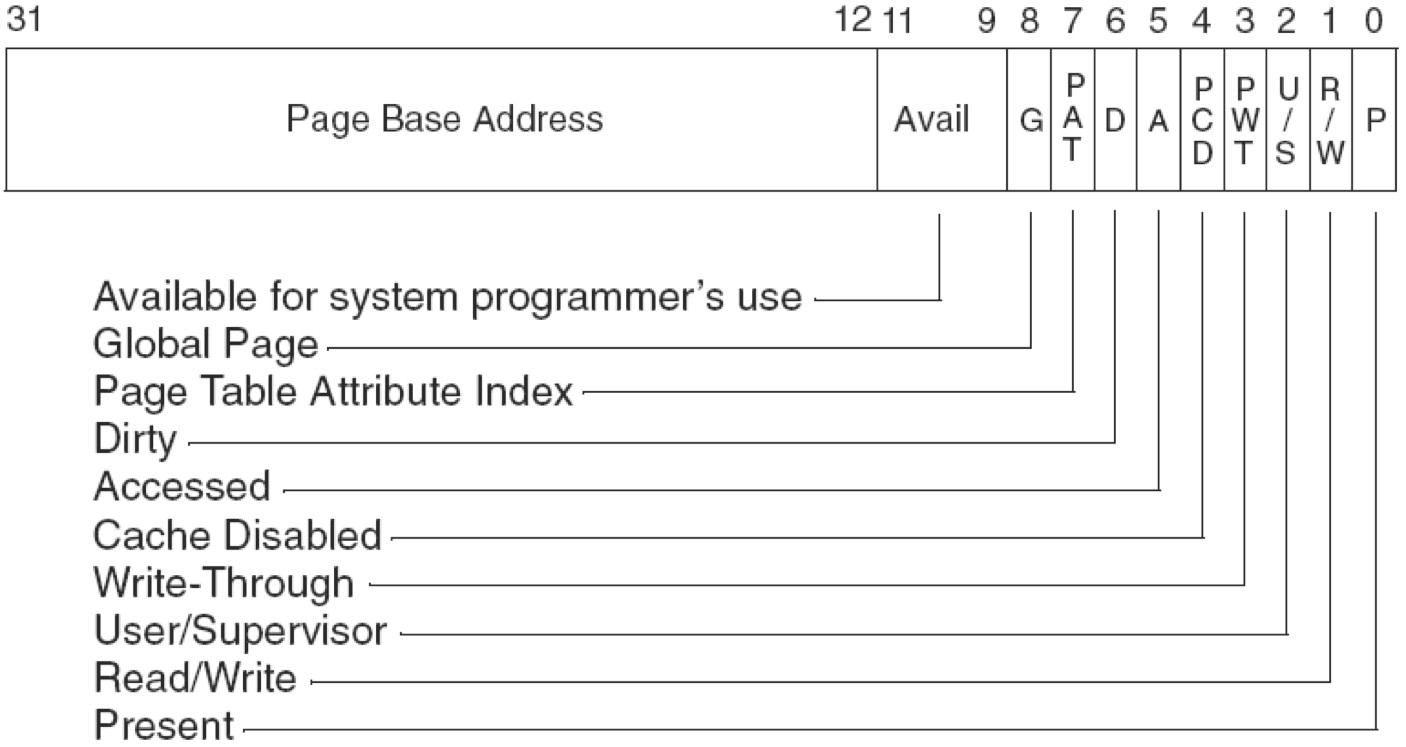
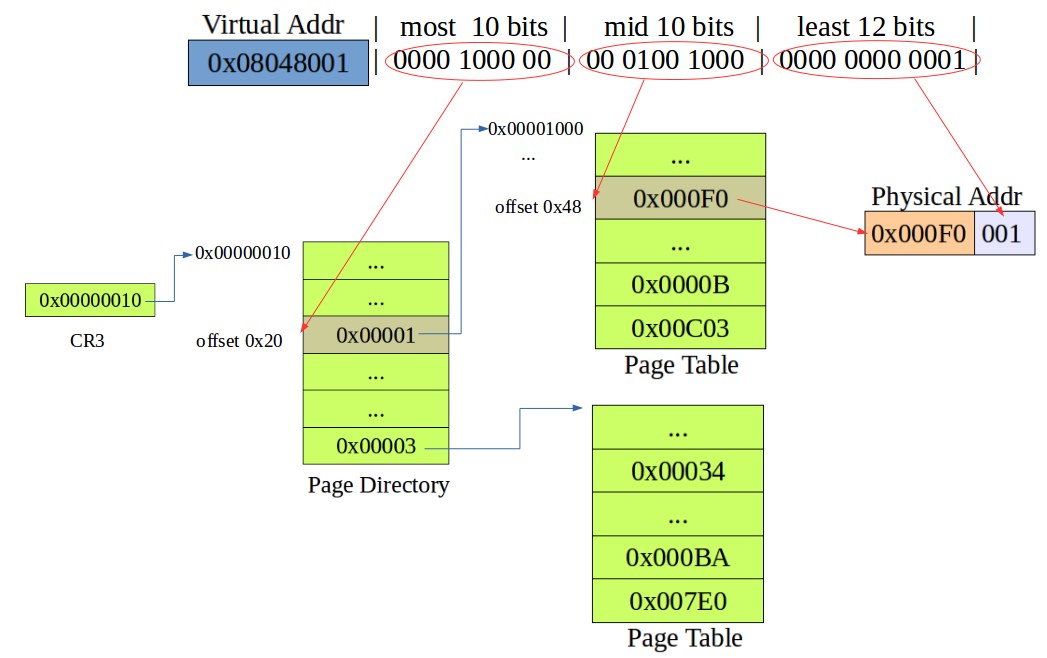
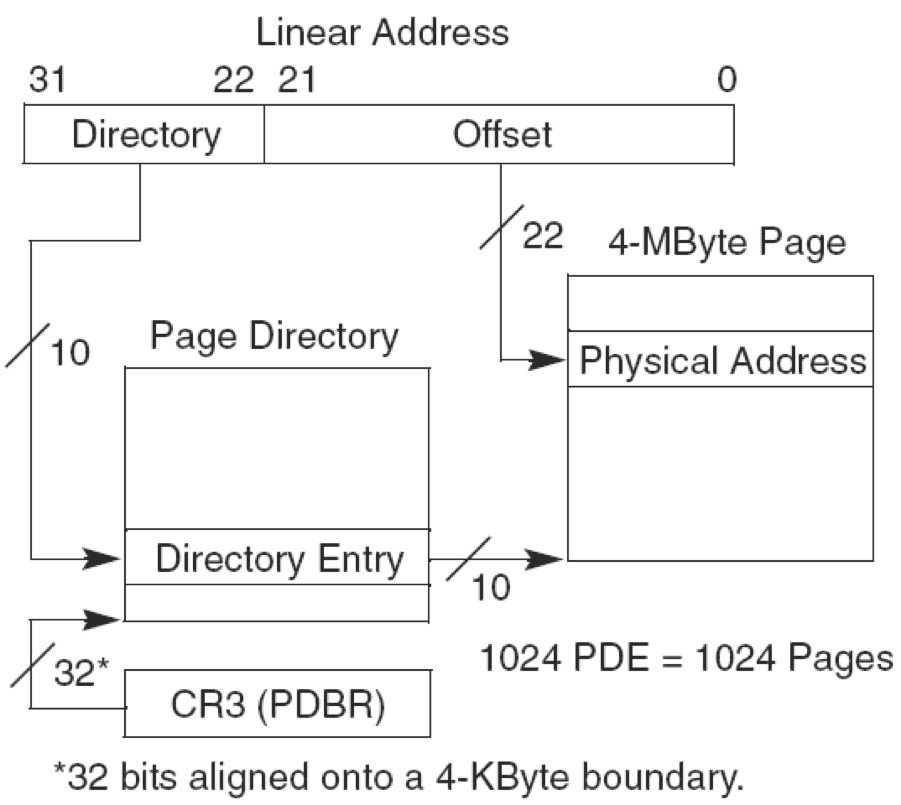
PSE(Page Size Extension)分页:就是扩展页框大小的
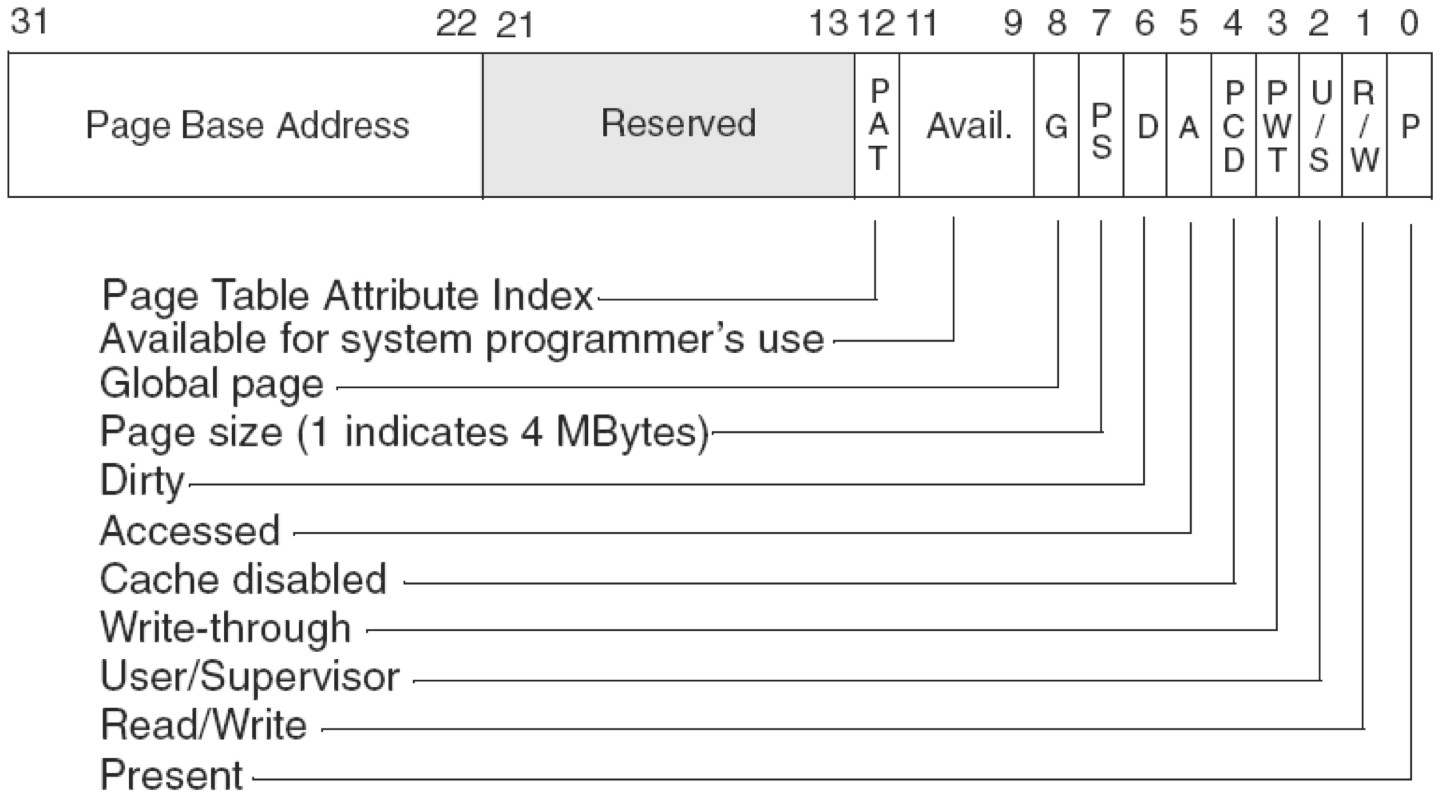
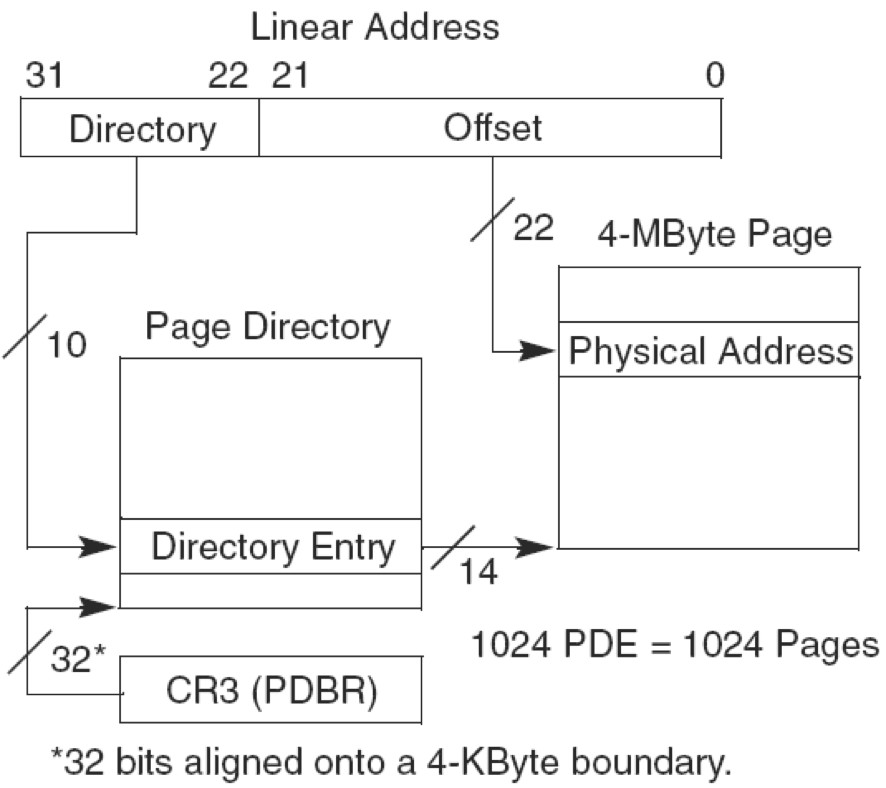
PSE-36分页:不仅增加页框大小还扩展了物理地址位数
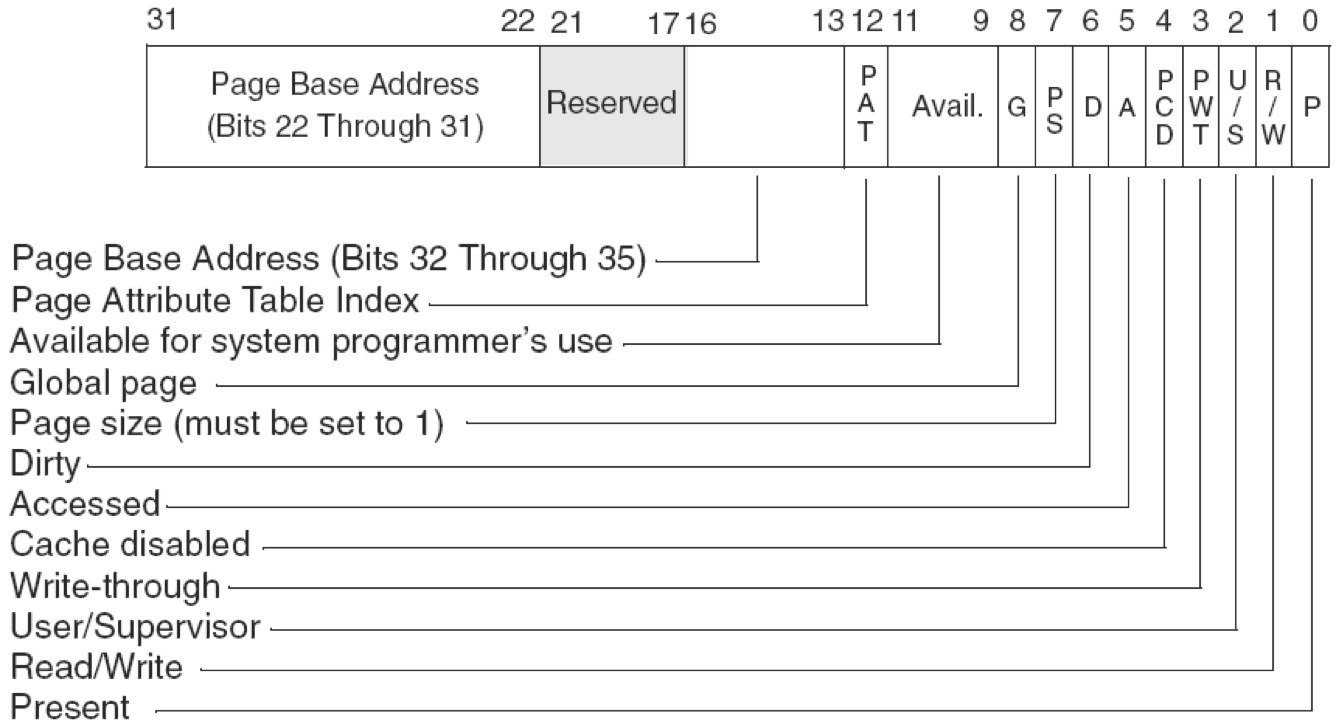
PAE (Physical Address Extention)分页:用来扩展物理地址位数的
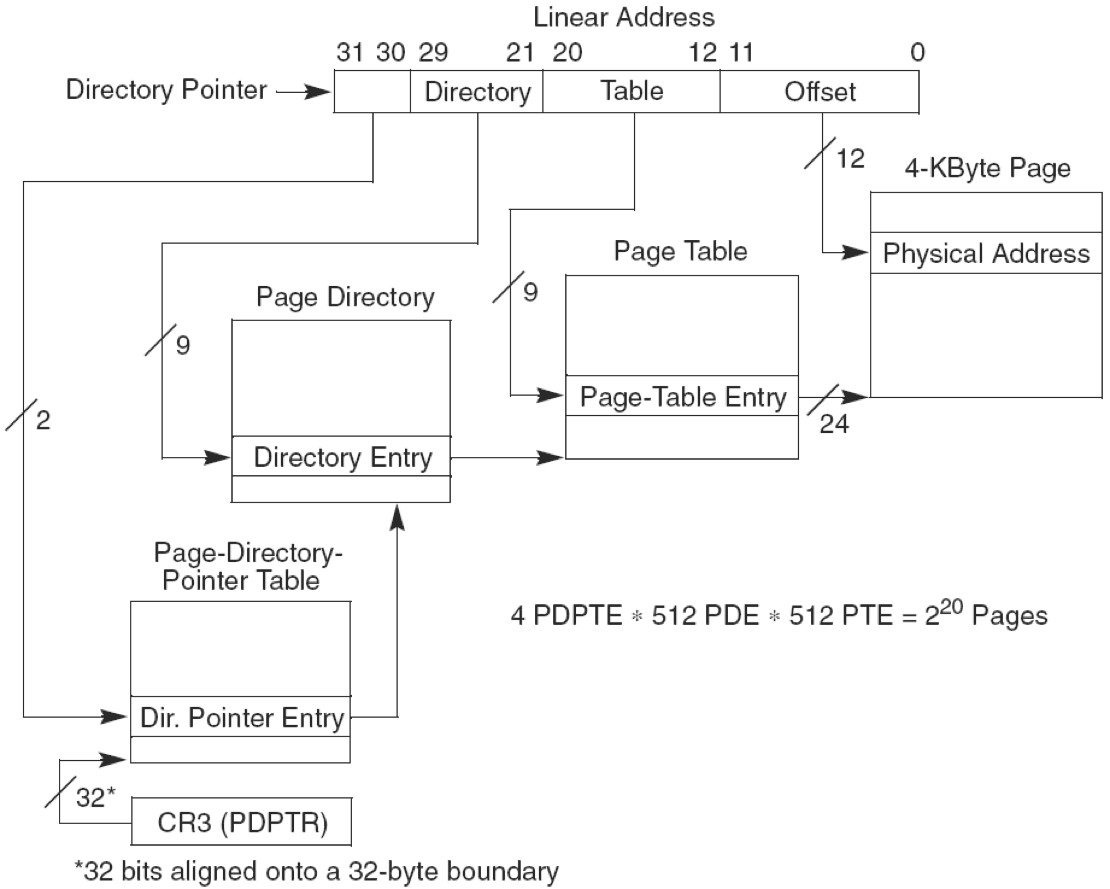

PAE+PSE分页:即扩展物理地址位数又增加页框大小
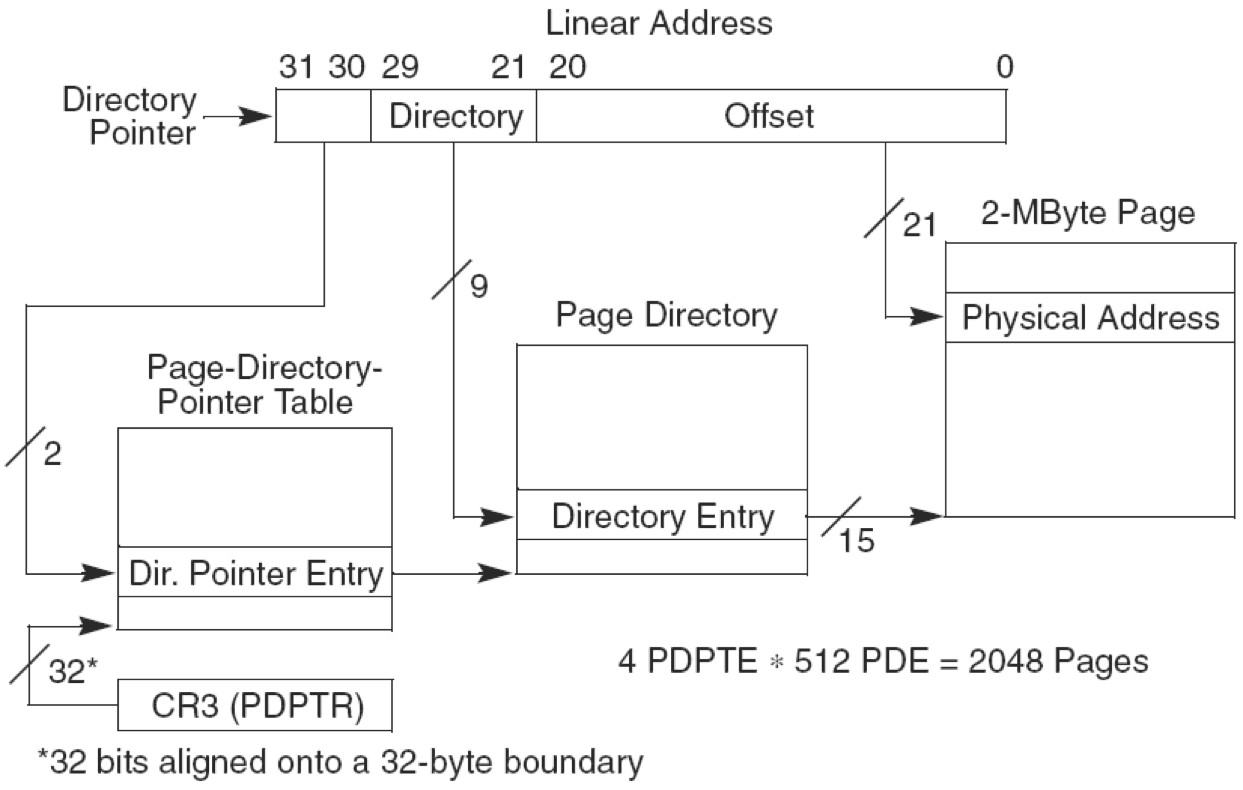
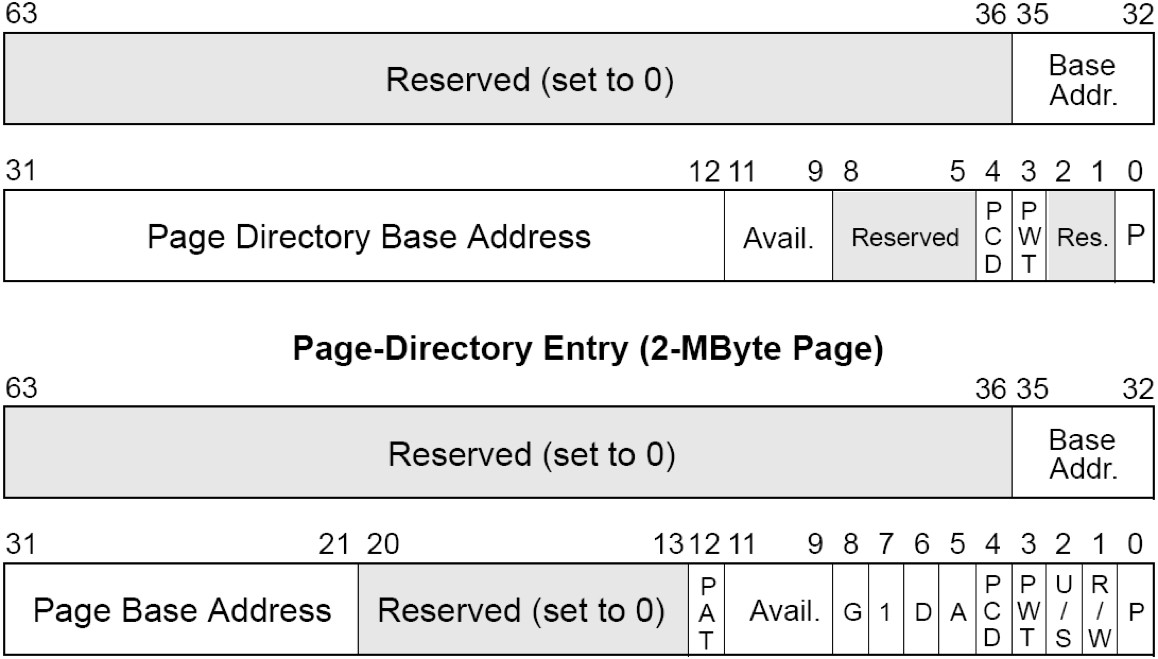
PAE与PSE介绍
PSE就是设置页框大小的,由 CR4寄存器的PSE位+PDE中的PS位 来控制。从实际情况来看,只要页框大小发生改变都属于运用了PSE技术。
PAE就是用来扩展物理地址的,但是线性地址不变。https://docs.microsoft.com/en-us/previous-versions/windows/hardware/design/dn613969(v=vs.85)
文章提到:PAE 只用于32位系统。后文将提到x64的长模式,其实是运用了 extends PAE ,然后 64位模式中,有三种页框大小,可以说也运用了PSE技术。【长模式中的extends PAE是针对 64位模式还是兼容模式呢,估计应该是64位模式吧】https://en.wikipedia.org/wiki/X86-64
查看和启用PAE:我们这里说的是32位的系统,因为64位的长模式默认是extends PAE。
Windows平台:
先查看cpu是否支持 PAE,然后再 boot.ini 或BCD 文件夹中,启用PAE。(Everest Ultimate Edition 软件可以查看CPU 是否支持PAE)可以查看我的电脑属性,观察是否启用了物理地址扩展。
linux平台:
centos下载地址 http://mirror.nsc.liu.se/centos-store/5.6/isos/i386/
32位centos5情况:我看了一下发行版就一个安装包,估计是系统安装器会自动根据 CPU情况,选择采用 PAE 内核,还是 NONPAE 内核
但是有 https://blog.csdn.net/chinalinuxzend/article/details/1759112 提到,centos4会自动选择内核版本,但是centos5 没有那么智能只会默认安装nonpae版本。
1,centos5下的内存变少了?
这个问题始于一台dell 2950的系统安装
dell 2950,双至强1.160GHZ
4G内存
安装完centos5之后只能看到3.3G的内存,少了700多MB,
用free和top两个命令都发现是3.3G, 咦,内存跑到哪儿去了?
咦,内存跑到哪儿去了?
问了dell的服务支持,对方答可以正常支持redhat4这个版本
安装centos4.4后,内存显示为4.1G,正常,
为什么centos5就不可以?
2,使用PAE核心
centos 5.0 默认安装 for i386的内核不支持 4g+的内存
需要安装上kernel-PAE
进入centos安装盘,rpm -ivh kernel-PAE*
然后修改grub设置
vi /boot/grub/grub.conf
找到:
title CentOS (2.6.18-8.el5PAE)
root (hd0,0)
kernel /vmlinuz-2.6.18-8.el5PAE ro root=/dev/VolGroup00/LogVol00
initrd /initrd-2.6.18-8.el5PAE.img
修改此记录所对应的一项为默认启用的核心即可
如:
default=0
保存退出,重新启动机器,设置生效,
在centos5下可以看到4.1G内存了
查看CPU是否支持PAE
[madhatta@www ~]$ grep -i pae /proc/cpuinfo
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm constant_tsc pni monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr lahf_lm
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm constant_tsc pni monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr lahf_lm
^^^
查看系统内核是否支持PAE:[centos5 的内核版本号有标明是否支持 PAE]
[madhatta@www ~]$ uname -r
2.6.18-194.32.1.el5PAE
参考:https://serverfault.com/questions/247080/how-do-i-find-out-if-pae-is-enabled
32位centos6情况:发行版还是一个软件,看情况是说内核默认是PAE版本,没有NONPAE版本,如果要安装在不支持PAE的CPU上需要修改替换内核。
具体参考:
https://www.centos.org/forums/viewtopic.php?t=67337
https://www.centos.org/forums/viewtopic.php?t=2157
centos6 版本,使用 uname -r 命令显示的内核字符串,已经不会显示是否支持 PAE 了。
但仍可以在 /boot 目录下,查看到【 config-内核字符串 】文件
如果该文件支持PAE ,会有 CONFIG_X86_PAE=y 配置项
============ 举例如下 ===========
[root@localhost ~]# uname -r
2.6.32-220.el6.i686
[root@localhost ~]# ls /boot
System.map-2.6.32-220.el6.i686 initramfs-2.6.32-220.el6.i686.img
config-2.6.32-220.el6.i686 lost+found
efi symvers-2.6.32-220.el6.i686.gz
grub vmlinuz-2.6.32-220.el6.i686
[root@localhost ~]# cat /boot/config-2.6.32-220.el6.i686 | grep PAE
CONFIG_X86_PAE=y
[root@localhost ~]#
有一个奇怪的地方,虚拟机设置了禁用CPU的pae功能,但是32位的centos6还是能发现CPU支持PAE。在32位的centos7中,只要虚拟机禁用了CPU的pae功能,系统就认为CPU不支持PAE。
方法一下载第三方nonpae内核
https://www.liangzl.com/get-article-detail-917.html
装完系统后,仍从安装光盘进入 Rescue Installed system,接着进入命令行。
从 Rescue Shell 进入bash 【 /mnt/sysimage/ 是系统提示给出的】
chroot /mnt/sysimage/ /bin/bash
安装nonpae内核
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-6-8.el6.elrepo.noarch.rpm
yum --enablerepo=elrepo-kernel install kernel-lt-NONPAE
检查系统已安装的内核
rpm -qa|grep kernel
退出当前 Chroot Shell 和 Rescure Shell
exit
exit
方法二自己编译nonpae内核
http://www.digitage.co.uk/digitage/library/linux/installing-centos-6-4-on-non-pae-hardware
https://my.oschina.net/colben/blog/1456759
32位centos7情况:发行版还是一个软件。虚拟机设置CPU成PAE还是NONPAE都能成功安装,并且系统的 cat /proc/cpuinfo 能正确识别CPU 是否支持PAE功能。【以此推理,centos7 下的内核要么PAE和非PAE 都支持,要么就只支持非PAE】
参考: https://centosfaq.org/centos/centos-7-i386-pae-kernel/
最暴力的手段就是编译内核模块,查看CR4 寄存器 是否开启了PAE功能。具体可以看本文第5节 Linux内存地址映射实验
补充:关于如何启用PAE,这其实没有实际意义的。因为安装器会自动判断系统需要nonpae还是pae内核。就算是centos6版本,要安装的也是nonpae内核。前面centos5的文章链接,https://blog.csdn.net/chinalinuxzend/article/details/1759112。提到过一种现象,需要进一步了解。
### 安装 pae 内核方法
yum install kernel-PAE
### 后面重启服务器就行
查看 CPU信息,内存信息,内核信息
查看CPU信息
cat /proc/cpuinfo
查看内存信息 条目解释 参考 http://linuxperf.com/?p=142
cat /proc/meminfo
查看版本信息
[root@localhost ~]# cat /proc/version
Linux version 3.10.0-957.21.3.el7.centos.plus.i686 ([email protected]) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Tue Jun 18 18:05:09 UTC 2019
[root@localhost ~]# uname -a
Linux db1.xxx.com 2.6.18-194.el5xen #1 SMP Fri Apr 2 15:34:40 EDT 2010 x86_64 x86_64 x86_64 GNU/Linux
依次是
操作系统名称: Linux uname -s 可以单独看到这个信息
计算机名: db1.xxx.com uname -n 可以单独看到这个信息
操作系统发行编号: 2.6.18-194.el5xen uname -r 可以单独看到这个信息
操作系统发行时间: #1 SMP Fri Apr 2 15:34:40 EDT 2010 uname -v 可以单独看到这个信息
计算机类型,进程类型,硬件平台:x86_64 uname –m,uname –p,uname -i 可以单独看到这个信息
操作系统信息:GNU/Linux uname -o 可以单独看到这个信息
下面是32位linux系统内存1G下的情况:
[root@localhost ~]# cat /proc/meminfo
MemTotal: 1027020 kB
MemFree: 728684 kB
MemAvailable: 762276 kB
Buffers: 2108 kB
Cached: 166804 kB
SwapCached: 0 kB
Active: 94164 kB
Inactive: 137300 kB
Active(anon): 62768 kB
Inactive(anon): 6728 kB
Active(file): 31396 kB
Inactive(file): 130572 kB
Unevictable: 0 kB
Mlocked: 0 kB
HighTotal: 139208 kB
HighFree: 103120 kB
LowTotal: 887812 kB
LowFree: 625564 kB
SwapTotal: 839676 kB
SwapFree: 839676 kB
Dirty: 24 kB
Writeback: 0 kB
AnonPages: 62556 kB
Mapped: 21576 kB
Shmem: 6944 kB
Slab: 28172 kB
SReclaimable: 13316 kB
SUnreclaim: 14856 kB
KernelStack: 968 kB
PageTables: 716 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 1353184 kB
Committed_AS: 298248 kB
VmallocTotal: 122880 kB
VmallocUsed: 32164 kB
VmallocChunk: 88156 kB
AnonHugePages: 24576 kB
CmaTotal: 0 kB
CmaFree: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 4096 kB
DirectMap4k: 49144 kB
DirectMap4M: 860160 kB
[root@localhost ~]#
#########################
DirectMap4k: DirectMap4M: 是TLB缓存 所指向的内存大小 40M + 840M = 890M 接近1GB = 系统内存
AnonHugePages统计的是 Transparent HugePages (THP),THP与Hugepages不是一回事,区别很大。
标准大页管理是预分配的方式,而透明大页管理则是动态分配的方式。
THP 是一个抽象层, 可以自动创建、管理和使用传统大页的大多数方面。
查看CPU信息:address sizes : 36 bits physical, 48 bits virtual 【应该是CPU最大支持 36位物理地址,48位虚拟地址。的确是这样,同样的CPU 在64位系统中,也显示 36位物理地址,48位虚拟地址】【备注这里的32位linux虚拟机关了CPU的PAE功能】
[root@localhost ~]# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz
stepping : 9
microcode : 0x19
cpu MHz : 2494.316
cache size : 3072 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fdiv_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht rdtscp constant_tsc xtopology nonstop_tsc eagerfpu pni pclmulqdq monitor ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx rdrand hypervisor lahf_lm fsgsbase
bogomips : 4988.63
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
[root@localhost ~]# cat /proc/cpuinfo
IA32分页缓存机制
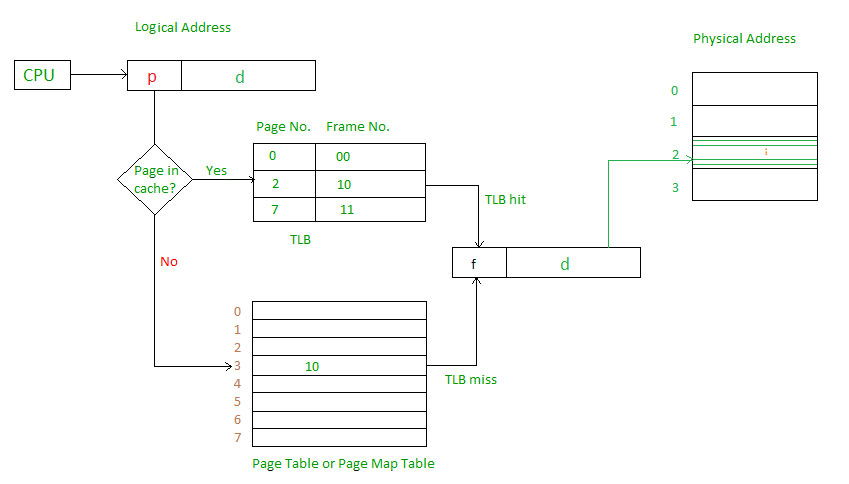
处理器引入MMU后,读取指令、数据需要访问两次内存:首先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。为了减少因为MMU导致的处理器性能下降,引入了TLB,TLB是Translation Lookaside Buffer的简称,可翻译为“地址转换后援缓冲器”,也可简称为“快表”。简单地说,TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
TLB大致原理图:
四、x86-64
x86-64 (also known as x64, x86_64, AMD64 and Intel 64[note 1]) is the 64-bit version of the x86 instruction set.
但 x86-64 ≠ IA-64 ,IA-64,又称英特尔安腾架构(Intel Itanium architecture),使用在Itanium处理器家族上的64位元指令集架构,由英特尔公司与惠普公司共同开发。IA是Intel Architecture(英特尔架构)的缩写,64指64位系统。使用这种架构的CPU,包括Itanium和Itanium 2。此架构与x86及x86-64并不相容,操作系统与软件需使用IA-64专用版本。
注意一下,开64位虚拟机的时候,设置禁止CPU的pae功能,但是centos 还是能发现系统支持pae,即cat /proc/cpuinfo 还是能看到pae参数。
x86-64分段
64位系统下,运行的是long mode。64位软件运行64位模式,32位和16位软件运行兼容模式。
在长模式下,段的影响取决于处理器是否运行在兼容模式还是64位模式。
- 在兼容模式下,分段功能好像在传统模式,并使用传统32位或16位的保护模式语义。
- 在64位模式下,分段是禁止的,建立64位虚拟地址空间(flat memory model吧,估计偏移地址就是线性地址的意思)。某些寄存器的一定功能,特别是系统段寄存器可持续在64位模式下运行。各种段寄存器都设置成0。至于GS/FS 是系统定义用法的寄存器,没有设置成0。


【估计逻辑地址就是线性地址了,而且目前线性地址是48位的。为什么是48位线性地址,这涉及到线性地址的空间分配问题:分为用户空间和内核空间:如下图所示:】
===========================================================================================
Start addr | Offset | End addr | Size | VM area description
===========================================================================================
| | | |
0000000000000000 | 0 | 00007fffffffffff | 128 TB | user-space virtual memory
__________________|____________|__________________|_________|______________________________
| | | |
0000800000000000 | +128 TB | ffff7fffffffffff | ~16M TB | non-canonical
__________________|____________|__________________|_________|______________________________
| | | |
ffff800000000000 | -128 TB | ffffffffffffffff | 128 TB | kernel-space virtual memory
__________________|____________|__________________|_________|______________________________
参考:
维基百科X86_memory_segmentation
64位微处理器系统编程
The x86-64 architecture does not use segmentation in long mode (64-bit mode).
Four of the segment registers: CS, SS, DS, and ES are forced to 0, and the limit to 264.
The segment registers FS and GS can still have a nonzero base address.
This allows operating systems to use these segments for special purposes.
Unlike the global descriptor table mechanism used by legacy modes,
the base address of these segments is stored in a model-specific register.
The x86-64 architecture further provides the special SWAPGS instruction,
which allows swapping the kernel mode and user mode base addresses.
For instance, Microsoft Windows on x86-64 uses the GS segment to point to the Thread Environment Block,
a small data structure for each thread, which contains information
about exception handling, thread-local variables, and other per-thread state.
Similarly, the Linux kernel uses the GS segment to store per-CPU data.
x86-64分页
参考:https://bbs.pediy.com/thread-203391.htm
x64的PAE的问题
在64位centos中,我在虚拟机界面关了CPU的PAE功能,但是在系统的命令行中,仍可以显示支持PAE功能。【64位系统我设置了双核CPU,所以下面可以看到两个CPU信息】
下面这个是在本地64位虚拟机上测试的(cpu支持36位物理地址,48位线性地址)
[coolguy@localhost ~]$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz
stepping : 9
microcode : 0x19
cpu MHz : 2494.316
cache size : 3072 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx rdrand hypervisor lahf_lm fsgsbase
bogomips : 4988.63
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz
stepping : 9
microcode : 0x19
cpu MHz : 2494.316
cache size : 3072 KB
physical id : 0
siblings : 2
core id : 1
cpu cores : 2
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt aes xsave avx rdrand hypervisor lahf_lm fsgsbase
bogomips : 4988.63
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
[coolguy@localhost ~]$
下面这个是在64位服务器上测试的(你看cpu支持40位物理地址,48位线性地址)
[root@superguy ~]# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2697 v4 @ 2.30GHz
stepping : 1
microcode : 0x1
cpu MHz : 2299.994
cache size : 16384 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds
bogomips : 4601.65
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
[root@superguy ~]#
core与xeon的比较
Core i7处理器被认为是Intel的“性能”CPU系列。与更具价值导向的Core i5系列相比,Core i7芯片具有更多可用内核,更高频率和更大的缓存分配,因此其速度快,响应速度足以支持当今最苛刻的应用。他们缺乏Xeon对纠错内存的支持(见下文),但对于高级用户,Core i7 CPU可以超频暂时以高于额定速度运行,而Xeon型号则不能。
英特尔至强CPU提供与Core i7系列类似的频率和高速缓存大小,以及更高的最大核心数。但最重要的区别是支持纠错码(ECC)内存,这是一种服务器级功能,使Xeon芯片在执行要求苛刻的任务关键型计算的工作站中特别有价值。ECC内存有助于在导致问题之前找到并修复99.999%的软内存错误,这可以大大减少数据损坏和破坏系统崩溃的工作。
x64的线性地址结构

在x64体系中只实现了48位的virtual address,高16位被用作符号扩展,这高16位要么全是0,要么全是1。
64位系统中因为页表项,页目录项之类的,变成了64位【32位系统中常规页表项是32位】,为了满足原来的4K的页面,就从原来的 2^10 x 32 =4K 变成 2^9 x 64 =4k ,所以索引地址由32位下的10位,变成了9位。
x64的常规分页模型
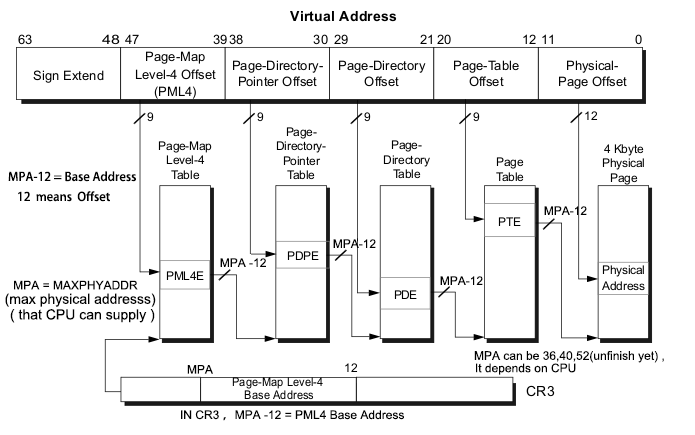
PML4T(Page Map Level4 Table)及表内的PML4E结构,每个表为4K,内含512个PML4E结构,每个8字节
PDPT (Page Directory Pointer Table)及表内的PDPTE结构,每个表4K,内含512个PDPTE结构,每个8字节
PDT (Page Directory Table) 及表内的PDE结构,每个表4K,内含512个PDE结构,每个8字节
PT(Page Table)及表内额PTE结构,每个表4K,内含512个PTE结构,每个8字节。
每个table entry 的结构都是8个字节64位宽,而virtual address中每个索引值都是9位,因此每个table都是512 x 8 = 4K字节。
x64的最大物理地址(MAXPHYADDR)
在Intel中使用MAXPHYADDR来表示最大的物理地址,我们可以通过CPUID的指令来获得处理支持的最大物理地址,然而这已经不在此次的讨论范围之内,我们需要知道的只是:
当MAXPHYADDR 为36位,在Intel平台的桌面处理器上普遍实现了36位的最高物理地址值,也就是我们普通的个人计算机,可寻址64G空间;
当MAXPHYADDR 为40位,在Inter的服务器产品和AMD 的平台上普遍实现40位的最高物理地址,可寻址达1TB;
当MAXPHYADDR为52位,这是x64体系结构描述最高实现值,目前尚未有处理器实现。
而对下级表的物理地址的存储4K页面寻址遵循如下规则:
① 当MAXPHYADDR为52位时,上一级table entry的12~51位提供下一级table物理基地址的高40位,低12位补零,达到基地址在4K边界对齐;
② 当MAXPHYADDR为40位时,上一级table entry的12~39位提供下一级table物理基地址的高28位,此时40~51是保留位,必须置0,低12位补零,达到基地址在4K边界对齐;
③ 当MAXPHYADDR为36位时,上一级table entry的12~35位提供下一级table物理基地址的高24位,此时36~51是保留位,必须置0,低12位补零,达到基地址在4K边界对齐。
x64页转换模型
X64,准确的说应该是IA32e paging 模型提供了三种页转换模型,
① 4K页面的转换表结构;
② 2M 页面的转换结构;
③ 1G页面的转换结构;
在64位模式下,处理器将48位的虚拟地址转化为物理地址,在兼容模式下,转化32位的虚拟地址。
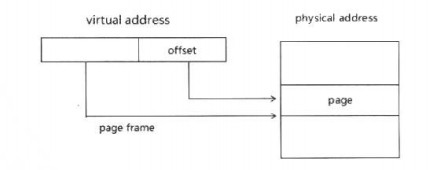
三种模型都是物理页帧的基地址加上页偏移得到物理地址,不同只是在于页帧的大小划分不同:
①4K页面: 使用PML4T,PDPT,PDT和PT 四级页转化表结构;
②2M页面:使用PML4T,PDPT 和PDT三级页转化表结构;
③1G 页面:使用PML4T和PDPT二级页表转化结构。
而在这里我们主要讨论的是4K页面大小的寻址方式,因为在个人计算机上,普遍都是4K
页面寻址,其他的方式也主要就是页面大小的差异。
x64页转换过程
CR3
(1)当CR4.PCIDE = 0时,CR3的结构如图

CR3可以使用64位宽,但是它表示的PML4T的物理基地址同样受到之前所说的MAXPHYADDR的约束,图示的只是理想的MAXPHYADDR为52位时的情况。
(2)而当CR4.PCIDE = 1的时,CR3的结构如图
 CR3的低12位提供一个PCID值,用来定义当前Process Context ID.
CR3的低12位提供一个PCID值,用来定义当前Process Context ID.
当对CR3进行更新时,CR3第63位决定是否需要处理器的TLB和paging-struct cache,这不在我们此次谈论的范围之内。
PML4E
接着再看PML4E的结构,如图:
PML4E并没有PS标志位,因此第7位是保留的,而PML4E提供的PDPT的物理基地址也受之前的MAXPHYADDR规则的约束。
PDPTE
然后就是PDPTE结构:
由于新增了1G 页面,因此在PDPTE结构里将控制1G的页面转化,由PDPTE.PS标志位进行转换,如图: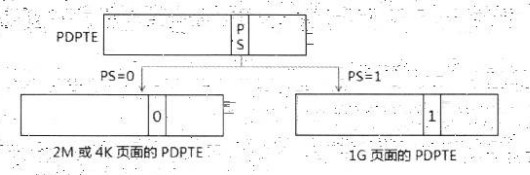
当PDPTE.PS=1,也就是PDPTE的第7位为1时,PDPTE将提供1G的物理页面地址;当PDPTE.PS=0,也就是PDPTE的第7位为0时,使用非1G的页面,将提供下一级的PDT的物理基地址,同样受MAXPHYADDR规则的约束。
1G页面下的PDPTE 的结构解析如下: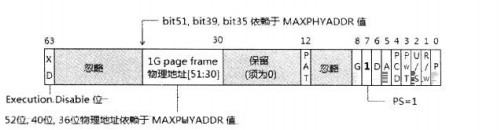
同样地,PDPTE提供的1G页面的物理地址也遵守MAXPHYADDR的规则,1G页面的地址低30将补0,意味着1G边界上对齐。
4K和2M页面下的PDPTE结构解析如下:
 将提供下一级PDT的物理基地址,同样也遵循MAXPHYADDR规则,那么再根据PDE.PS再决定是使用2M页面还是4K页面。
将提供下一级PDT的物理基地址,同样也遵循MAXPHYADDR规则,那么再根据PDE.PS再决定是使用2M页面还是4K页面。
PDE
PDE的结构和PDPTE类似,也是用PS(第7位)表示是使用2M的页面还是4K 的页面,下面是2M 页面的PDE结构解析:
同样对于页面的物理基地址也遵循MAXPHYAD原则。
接下来是4K 页面的 PDE 结构解析,也遵循MAXPHYADDR 规则。

PTE
PTE的结构解析如下,同样遵循MAXPHYADDR规则。
五、Linux内存地址映射实验
参考资料:
基础概念介绍:http://malgenomeproject.org/os2018fall/09_linux_paging_example.pdf
linux32位系统内存实验
http://ilinuxkernel.com/?p=1276 文档 Linux内存地址映射(32位)
实验相关源码下载地址:Memory_Address_Mapping
关于linux查看寄存器如CR3,看了一下需要自己编写内核moudle ,然后加载调用。
下面代码(注意:本源码是32位系统)可用来读取CRn控制寄存器的值。来自https://ilinuxkernel.com/?p=606
#include <linux/module.h>
#include <linux/proc_fs.h>
static char modname[] = "cr4";
static int cr4;
static int my_get_info( char *buf, char **start, off_t off, int count )
{
int len = 0;
asm(" movl %cr4, %ebx \n movl %ebx, cr4 ");
len += sprintf( buf+len, "cr4=%08X ", cr4 );
len += sprintf( buf+len, "PSE=%X ", (cr4>>4)&1 );
len += sprintf( buf+len, "PAE=%X ", (cr4>>5)&1 );
len += sprintf( buf+len, "\n" );
return len;
}
int init_module( void )
{
printk( "<1>\nInstalling \'%s\' module\n", modname );
create_proc_info_entry( modname, 0, NULL, my_get_info );
return 0;
}
void cleanup_module( void )
{
remove_proc_entry( modname, NULL );
printk( "<1>Removing \'%s\' module\n", modname );
}
MODULE_LICENSE("GPL");
内核模块编写教程:
http://tldp.org/LDP/lkmpg/2.6/html/lkmpg.html
https://www.cnblogs.com/wrjvszq/p/4260996.html
linux64位系统内存实验
64位系统,分段产生的虚拟地址是48位,因为段寄存器都设置成0,估计是偏移地址是48位的【GS和FS两个段寄存器没有设置成0,这两个是保留给操作系统自己定义和使用的,CPU没有指定这两个寄存器的功能】,然后看分页情况,映射到物理地址可能是36,40,52位物理地址。
http://ilinuxkernel.com/?p=1303 文档 Linux内核在x86_64 CPU中地址映射
实验相关源码下载地址:Memory_Address_Mapping_x86-64
EMS (Expanded Memory Specification)
扩充内存(expand memory)与扩展内存(extend memory)
看了一下维基百科:(扩充内存被扩展内存取代了)
https://en.wikipedia.org/wiki/Expanded_memory#EMS
《微型计算机技术》 《微型计算机接口技术》
EMS 好像是一种 实地址模式下的内存扩充技术。
后话
内存分页机制还是需要自己写简单的操作系统,才能更好的明白。
操作系统demo:其实bios 自带了基本的 的驱动,包括磁盘和显示器。【比如进入bios界面,我们就能打开显示器上面的字符,所以编写操作系统时,不需要磁盘驱动,引导代码也只是一段简单的汇编。bios的磁盘驱动是识别扇区,操作系统的文件系统是对扇区的抽象】
独自一人编写一个操作系统是什么概念?
操作系统真象还原 https://github.com/seaswalker/tiny-os
《30 天自制操作系统》中文源码
畅销书《 自己动手写操作系统》再版——《 Orange’S:一个操作系统的实现》
JOS 系统教程
https://github.com/kiukotsu/ucore https://www.xuetangx.com/courses/TsinghuaX/30240243X/2015_T1/about
http://malgenomeproject.org/os2018fall/
os resources
micron教你如何开发OS:http://code.google.com/p/micron
来自台湾的BenOS:http://ben6.blogspot.tw/search/label/osdev
The Operating System resource center:http://www.nondot.org/sabre/os/articles
SGOS at Xiaoxia:http://code.google.com/p/sgos/
非常尼克斯推荐的实现内核相关文档: http://verynix.com/os-dev-book.html
How to write a simple operating system: http://mikeos.berlios.de/write-your-own-os.html
OS Dev Wiki: http://wiki.osdev.org/Main_Page
Write your own operating system: http://geezer.osdevbrasil.net/osd/index.htm
https://www.kernel.org/doc/ols/2014/ols2014-barbalace.pdf (a replicated-kernel OS which is based on Linux)
指尖操作系统: http://os-z.com/
魔芋——OS入门堂: http://blog.csdn.net/flyback/article/category/126349
GridOS(曾经是Future Alpha的网站):http://www.woos.cn/index.htm
miaowangjian的OS专栏:http://blog.csdn.net/miaowangjian
迷途知返的汇编学习笔记:http://pwwang.com/tag/%E6%B1%87%E7%BC%96%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
IT元素的实模式到保护模式的切换:http://www.ourys.com/post/gdt-descriptor-table.html
MIT couse 6.828 operating system engieering:http://pdos.csail.mit.edu/6.828/2012/
参考:
《x86/x64体系探索及编程》
80286与保护模式
80386的分段机制、分页机制和物理地址的形成
【OS修炼指南目录】—-《X86汇编语言-从实模式到保护模式》读书笔记目录表
https://pdos.csail.mit.edu/6.828/2005/readings/i386/toc.htm
http://www.kerneltravel.net/chenlj/lecture4.pdf
Linux内核源代码情景分析(上册)
关于分段分页的
https://slideplayer.com/slide/9995089/
https://medium.com/hungys-blog/linux-kernel-memory-addressing-a0d304283af3
http://www.scs.stanford.edu/05au-cs240c/notes/l2.pdf
http://www.rcollins.org/ddj/May96/
http://www.rcollins.org/articles/2mpages/2MPages.html
https://yajin.org/os2018fall/09_linux_paging_example_x86_64.pdf
http://www.cs.albany.edu/~sdc/CSI500/Spr10/Classes/C15/intelpaging83-94.pdf
https://blog.csdn.net/SHU15121856/article/details/78868968
http://www.renyujie.net/articles/article_ca_x86_5.php
关于PAE问题:
https://docs.microsoft.com/en-us/previous-versions/windows/hardware/design/dn613969(v=vs.85)
http://www.voidcn.com/article/p-bmzsqmdy-bek.html
https://serverfault.com/questions/247080/how-do-i-find-out-if-pae-is-enabled
关于查看服务器信息的:
https://blog.csdn.net/u012625036/article/details/17397507
https://blog.csdn.net/ghj1976/article/details/6158953