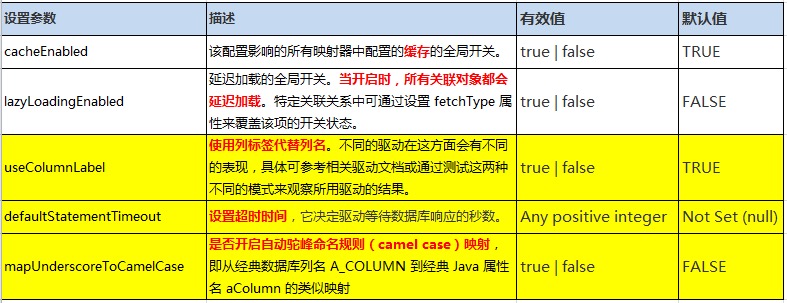
mappers 是用来进行 sql映射注册的。
方法一,文件映射方法:
1、文件路径查看

2、编辑全局映射文件:
<mappers> <!-- mapper:注册一个sql映射 ,方法一注册配置文件 resource:引用类路径下的sql映射文件【resource路径,就是以二进制bin文件夹根目录为起始目录,来计算子目录下的路径】 mybatis/mapper/EmployeeMapper.xml eclipse 源码文件夹路径 到最后都会合并到类路径下。 url:引用网路路径或者磁盘路径下的sql映射文件 file:///var/mappers/AuthorMapper.xml --> <mapper url="file:///Users/jerry/Documents/workspace/Mybatis_02/conf/EmployeeMapper_new.xml"/> <mapper resource="mykkk/EmployeeMapper_old.xml"/> </mappers>
3、sql映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.mapper.EmployeeMapper">
<!--
上面的 namespace:名称空间;指定为接口的全类名
下面的 id:唯一标识被规定为接口方法名 【public Employee getEmpById(Integer id);】
下面的 resultType:返回值类型
下面的 #{id}:从传递过来的参数中取出id值
-->
<select id="getEmpById" resultType="EmployEE">
<!--
1、之前没有在mybatis的全局配置文件中,开启驼峰转化 setting ,
因此执行 select * from tb1_employee where id = #{id} 时,
那时 数据库的字段 last_name 无法直接映射 到bean 中的lastName ,
查询结果导致数据库 last_name 无法赋值给employee bean中的lastName
所以,employee 中的 lastName 是空值,
所以需要在 这里的sql语句中取别名
select id,last_name lastName,email,gender from tbl_employee where id = #{id}
2、现在已经开启了驼峰转化,所以就不需要 在sql语句中 取别名了
下面的sql语句 也可以 直接写成:select * from tb1_employee where id = #{id}
-->
select id,last_name,email,gender from tbl_employee where id = #{id}
</select>
<!--
默认有一个 没有添加 databaseId 的sql语句,然后是 各厂家的sql语句,调用sql语句时,选择 最匹配的sql语句 调用。
-->
<select id="getEmpById" resultType="com.mybatis.bean.Employee"
databaseId="mysql">
select * from tbl_employee where id = #{id}
</select>
<select id="getEmpById" resultType="com.mybatis.bean.Employee"
databaseId="oracle">
select EMPLOYEE_ID id,LAST_NAME lastName,EMAIL email
from employees where EMPLOYEE_ID=#{id}
</select>
</mapper>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mybatis.hhh.EmployeeMapper">
<!--
上面的 namespace:名称空间;名字随便写
下面的 id:唯一标识
下面的 resultType:返回值类型
下面的 #{id}:从传递过来的参数中取出id值
-->
<select id="selectEmp" resultType="com.mybatis.bean.Employee">
<!--
1、之前没有在mybatis的全局配置文件中,开启驼峰转化 setting ,
因此执行 select * from tb1_employee where id = #{id} 时,
那时 数据库的字段 last_name 无法直接映射 到bean 中的lastName ,
查询结果导致数据库 last_name 无法赋值给employee bean中的lastName
所以,employee 中的 lastName 是空值,
所以需要在 这里的sql语句中取别名
select id,last_name lastName,email,gender from tbl_employee where id = #{id}
2、现在已经开启了驼峰转化,所以就不需要 在sql语句中 取别名了
下面的sql语句 也可以 直接写成:select * from tb1_employee where id = #{id}
-->
select id,last_name,email,gender from tbl_employee where id = #{id}
</select>
</mapper>
4、测试文件(和原来没有差别,只是将mybatis-config.xml改了一下目录)
@Test
public void test_old() throws IOException {
String resource = "bky/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//获取sqlSession实例 ,能直接执行已经映射的sql语句。
// sql的唯一标识:statement Unique identifier matching the statement to use.
// 执行sql要用的参数:parameter A parameter object to pass to the statement.
SqlSession openSession = sqlSessionFactory.openSession();
try{
//唯一标识符可以直接写 selectEmp 但为了防止 和别可能有的冲突,添加了命名空间
Employee employee = openSession.selectOne("com.mybatis.hhh.EmployeeMapper.selectEmp",1);
System.out.println(employee);
}catch (Exception e) {
// TODO: handle exception
}finally {
openSession.close();
}
}
/********************************************************************/
public SqlSessionFactory getSqlSessionFactory() throws IOException {
String resource = "bky/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
return new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void test_new() throws IOException {
// 1、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
// 2、获取sqlSession对象
SqlSession openSession = sqlSessionFactory.openSession();
try {
// 3、获取接口的实现类对象
//会为接口自动的创建一个代理对象,代理对象去执行增删改查方法
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Employee employee = mapper.getEmpById(1);
System.out.println(mapper.getClass());
System.out.println(employee);
} finally {
openSession.close();
}
}
方法二,接口映射方法
1、全局配置文件:
<mappers>
<!-- 旧方法操作mybatis 的配置文件,不存在接口文件,无法使用 class标签 -->
<mapper resource="mykkk/EmployeeMapper_old.xml" />
<!-- 新方法操作mybatis 的配置文件,存在接口文件,可以使用 class标签
但是必须保障 在指定的class类路径下,同名的接口文件 和 同名的sql映射文件都存在 才行
-->
<mapper class="com.mybatis.mapper.EmployeeMapper" />
<!-- 如果指定目录下,有多个接口类和对应的映射文件 需要用class标签配置 ,
可以用批量配置方法,直接写 接口类的 包名就行
比如上面的 可以写成 <package name="com.mybatis.mapper"/>
-->
</mappers>
2、文件目录
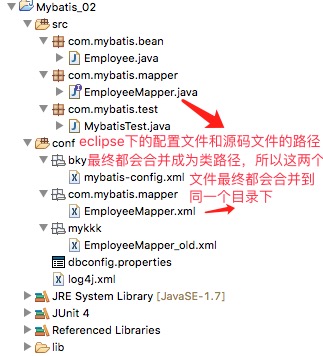
3、Junit测试代码(和原来的没有区别)
4、当然 Mapper中 的class标签 ,不是一定需要 接口文件和 sql映射文件,都存在同一个目录。可以 采用对接口 注解的方式,来取消sql映射文件。
比如:对EmployeeMapper.java 接口修改并添加注解,来取消 sql映射文件。
package com.mybatis.mapper;
import org.apache.ibatis.annotations.Select;
import com.mybatis.bean.Employee;
public interface EmployeeMapper {
@Select("select * from tbl_employee where id=#{id}")
public Employee getEmpById(Integer id);
}