Windows操作系统,使用的编码是不是UTF-16
答案:应该是utf-16编码。
实验验证:
- 新建一个txt文本文档,然后写一段英文字符 比如 helloword,默认保存方式是ANSI也就是常见的ASCII编码。
- 保存完再重新打开该文档。接着打开Cheat Engine ,选择注入文本编辑器的进程,然后搜索hellword字符串,记得勾选utf-16,找到内存地址后,选择查看内存空间,记住该文本内容存放在内存中的地址是虚拟地址(也叫线性地址),且内存上存放文本内容采用的是utf-16 编码,不再是ANSI编码了。
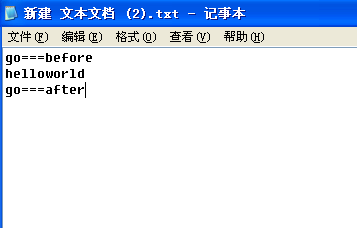 用notepad++ 查看十六进制代码如下:
用notepad++ 查看十六进制代码如下:
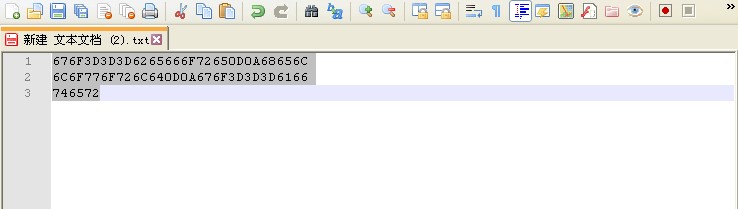
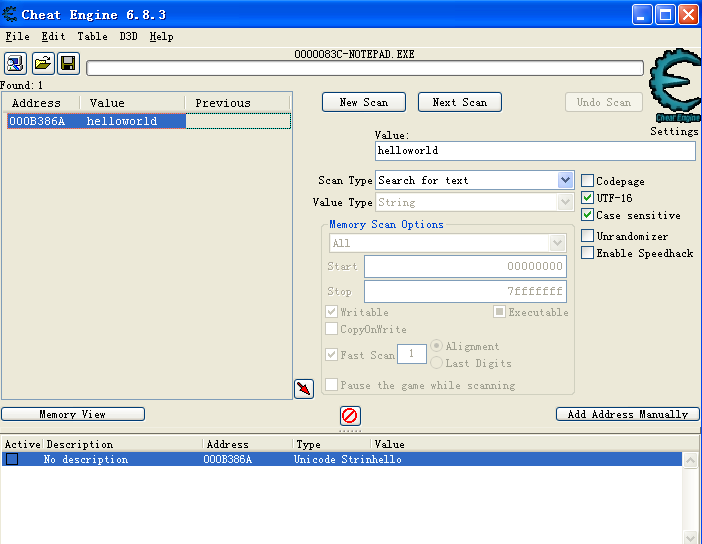
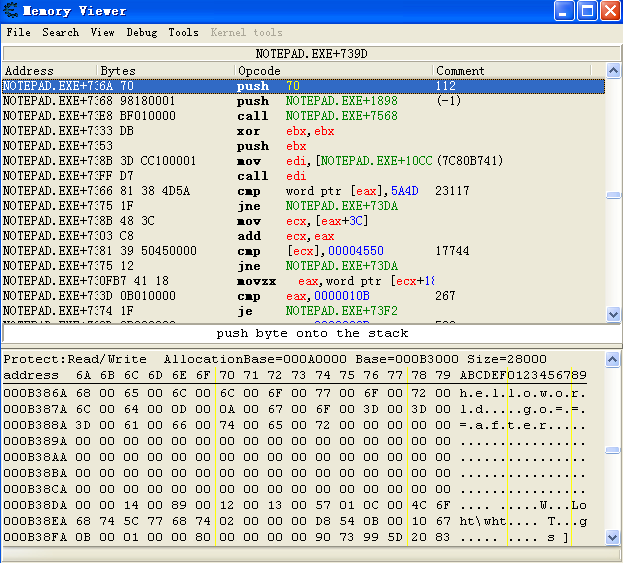
这里我们可以看到 hellword 字符串在内存中的虚拟地址(即线性地址)是000B386A
参考文章链接:https://social.microsoft.com/Forums/zh-TW/dc75573f-85c3-47a1-b761-97dda06ee847/windows2580520316319953247965292203512999230340325343072126159199?forum=windowsxpzhchs
windows操作系统区别于大多数其他操作系统的特点之一是,它的大多数内部文本串是以16位宽的Unicode字符来存储和处理的。Unicode(统一的字符编码标准)是一个国际字符集标准,它为世界上绝大多数一直的字符集定义了唯一的16位值(有关Unicode的更多信息,请参考www.unicode.org以及MSDN Library中有关的程序车技文档)
因为许多应用程序只处理8位(单字节)ANSI字符串,所以,接受字符串参数的windows的函数都有两个入口点:一个Unicode(宽字符,16位)和一个ANSI(窄字符,8位)。windows的以下几个版本,即windows95、windows98、windowsME,并没有为所有的windows函数实现Unicode的接口,所有如果所设计的应用程序要考虑到运行在这些操作系统之上,则往往使用窄字符版本。如果你调用一个windows函数的窄字符版本,则输入的字符串参数在被系统处理之前,先转成Unicode,而输出的参数则在被返回给应用程序之前,从Unicode转成ANSI字符串。因此,如果你有一个老的服务程序或者一段代码需要运行在windows上,而这份代码是按照ANSI字符串来编写的,那么windows将把ANSI字符转成Unicode,以便于内部使用。然而,windows永远不会转换文件内部的数据——由应用程序来决定是否要存储为Unicode或者ANIS。
在windows的以前版本中,亚洲和中东版本是美国和欧洲核心版本的一个超集,其中也包含了额外的windows函数,它可以满足处理更加复杂的文本输入和排版需求(比如从右至左的文本输入)。到了windows2000,所有语种的版本都包含同样的windows函数。windows不再使用单独的语言版本,而是有一份全球统一的二进制代码,因此,同一份安装可以支持多种语言(只需求加入各种语言包即可)。应用程序也可以利用这一套windows函数,做到同一份应用程序二进制代码可以支持多种语言!