一、编码国际化产生原因:
全世界很多个国家都在为自己的文字编码,并且互不想通,不同的语言字符编码值相同却代表不同的符号(例如:韩文编码EUC-KR中“한국어”的编码值正好是汉字编码GBK中的“茄惫绢”)。因此,同一份文档,拷贝至不同语言的机器,就可能成了乱码,这给各国和各地区交换信息带来了很大的困难,同时也给国际化(本地化)编程造成了很大的麻烦。
二、UNICODE和UCS方案
于是人们就想:我们能不能定义一个超大的字符集,它可以容纳全世界所有的文字字符,再对它们统一进行编码,让每一个字符都对应一个不同的编码值,从而就不会再有乱码了。
如果说“各个国家都在为自己文字独立编码”是百家争鸣,那么“建立世界统一的字符编码”则是一统江湖,谁都想来做这个武林盟主。早前就有两个机构试图来做这个事:
(1) 国际标准化组织(ISO),他们于1984年创建ISO/IEC JTC1/SC2/WG2工作组,试图制定一份“通用字符集”(Universal Character Set,简称UCS),并最终制定了ISO 10646标准。
(2) 统一码联盟,他们由Xerox、Apple等软件制造商于1988年组成,并且开发了Unicode标准(The Unicode Standard,这个前缀Uni很牛逼哦—Unique, Universal, and Uniform)。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。1991年,不包含CJK统一汉字集的Unicode 1.0发布。随后,CJK统一汉字集的制定于1993年完成,发布了ISO 10646-1:1993,即Unicode 1.1。
从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。不过由于Unicode这一名字比较好记,因而它使用更为广泛。
备注:
ISO 10646 定义了 UCS-4 和UCS-2 两种编码形式。
其中UCS-4其编码固定占用4个字节,UCS-2其编码固定占用2个字节
Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point)。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0016到1016,共计17个平面。且第一个平面称为“基本多语言平面”(Basic Multilingual Plane,简称BMP)【ISO 10646 不会超出这些平面赋值,0016代表二进制0000 0000,1016代表二进制0001 0000,所以Unicode 17个平面只占用了三个字节不到,也就是占了21位 编码位】
UCS 是所有其他字符集标准的一个超集. 它保证与其他字符集是双向兼容的. 就是说, 如果你将任何文本字符串翻译到 UCS格式, 然后再翻译回原编码, 你不会丢失任何信息。UCS 包含了用于表达所有已知语言的字符。对于还没有加入的语言,由于正在研究怎样在计算机中最好地编码它们, 因而最终它们都将被加入。
1、编码方式产生原因
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如UTF-8是Unicode的实现方式之一。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
2、编码方式分类
UTF-32与UCS-4
在Unicode与ISO 10646合并之前,ISO 10646标准为“通用字符集”(UCS)定义了一种31位的编码形式(即UCS-4),其编码固定占用4个字节(实际上只用了31位,最高位必须为0),编码空间为0x00000000~0x7FFFFFFF(可以编码20多亿个字符)。下面让我们做一些简单的数学游戏:
UCS-2有2^16=65536个码位,UCS-4有2^31=2147483648个码位。
UCS-4有20多亿个编码空间,但实际使用范围并不超过0x10FFFF,并且为了兼容Unicode标准,ISO也承诺将不会为超出0x10FFFF的UCS-4编码赋值。由此UTF-32编码被提出来了,它的编码值与UCS-4相同,只不过其编码空间被限定在了0~0x10FFFF之间。因此也可以说:UTF-32是UCS-4的一个子集。备注: UTF-32编码长度是固定的,UTF-32中的每个32位值代表一个Unicode码位,并且与该码位的数值完全一致。
UTF-16与UCS-2
除了UCS-4,ISO 10646标准为“通用字符集”(UCS)定义了一种16位的编码形式(即UCS-2),其编码固定占用2个字节,它包含65536个编码空间(可以为全世界最常用的63K字符编码,为了兼容Unicode,0xD800-0xDFFF之间的码位未使用)。例:“汉”的UCS-2编码为6C49。
UCS-2对于ascii里的那些“半角”字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于“半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
但俩个字节并不足以正真地“一统江湖”(a fixed-width 2-byte encoding could not encode enough characters to be truly universal),于是UTF-16诞生了,与UCS-2一样,它使用两个字节为全世界最常用的63K字符编码,不同的是,它使用4个字节对不常用的字符进行编码。UTF-16属于变长编码。
前面提到过:Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point),而第一个平面称为“基本多语言平面”(Basic Multilingual Plane,简称BMP),其余平面称为“辅助平面”(Supplementary Planes)。其中“基本多语言平面”(0~0xFFFF)中0xD800~0xDFFF之间的码位作为保留,未使用。UCS-2只能编码“基本多语言平面”中的字符,此时UTF-16与UCS-2的编码一样(都直接使用Unicode的码位作为编码值),例:“汉”在Unicode中的码位为6C49,而在UTF-16编码也为6C49。另外,UTF-16还可以利用保留下来的0xD800-0xDFFF区段的码位来对“辅助平面”的字符的码位进行编码,因此UTF-16可以为Unicode中所有的字符编码。
UTF-16中如何对“辅助平面”进行编码呢?
Unicode的码位区间为0~0x10FFFF,除“基本多语言平面”外,还剩0xFFFFF个码位(并且其值都大于或等于0x10000)。对于“辅助平面”内的字符来说,如果用它们在Unicode中码位值减去0x10000,则可以得到一个0~0xFFFFF的区间(该区间中的任意值都可以用一个20-bits的数字表示)。该数字的前10位(bits)加上0xD800,就得到UTF-16四字节编码中的前两个字节;该数字的后10位(bits)加上0xDC00,就得到UTF-16四字节编码中的后两个字节。例如:
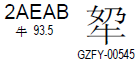 (这个字念啥?^_^)
(这个字念啥?^_^)
上面这个汉字的Unicode码位值为2AEAB,减去0x10000得到1AEAB(二进制值为0001 1010 1110 1010 1011),前10位加上D800得到D86B,后10位加上DC00得到DEAB。于是该字的UTF-16编码值为D86BDEAB(该值为大端表示,小端为6BD8ABDE)。
UTF-16是Unicode字符集的一种转换方式,即把Unicode的码位转换为16比特长的码元串行,以用于数据存储或传递。UTF-16编码规则如下:
2.2.1 从U+D800到U+DFFF的码位(代理区)
因为Unicode字符集的编码值范围为0-0x10FFFF,而大于等于0x10000的辅助平面区的编码值无法用2个字节来表示,所以Unicode标准规定:基本多语言平面内,U+D800..U+DFFF的值不对应于任何字符,为代理区。因此,UTF-16利用保留下来的0xD800-0xDFFF区段的码位来对辅助平面的字符的码位进行编码。
但是在使用UCS-2的时代,U+D800..U+DFFF内的值被占用,用于某些字符的映射。但只要不构成代理对,许多UTF-16编码解码还是能把这些不符合Unicode标准的字符映射正确的辨识、转换成合规的码元. 按照Unicode标准,这种码元串行本来应算作编码错误.
2.2.2 从U+0000至U+D7FF以及从U+E000至U+FFFF的码位
第一个Unicode平面(BMP),码位从U+0000至U+FFFF(除去代理区),包含了最常用的字符。UTF-16与UCS-2编码在这个范围内的码位为单个16比特长的码元,数值等价于对应的码位。BMP中的这些码位是仅有的码位可以在UCS-2被表示。
2.2.3 从U+10000到U+10FFFF的码位
辅助平面(Supplementary Planes)中的码位,大于等于0x10000,在UTF-16中被编码为一对16比特长的码元(即32bit,4Bytes),称作 code units called a 代理对(surrogate pair),具体方法是:
Ø 码位减去0x10000, 得到的值的范围为20比特长的0..0xFFFFF(因为Unicode的最大码位是0x10ffff,减去0x10000后,得到的最大值是0xfffff,所以肯定可以用20个二进制位表示),写成二进制形式:yyyy yyyy yyxx xxxx xxxx。
Ø 高位的10比特的值(值的范围为0..0x3FF)被加上0xD800得到第一个码元或称作高位代理(high surrogate), 值的范围是0xD800..0xDBFF。由于高位代理比低位代理的值要小,所以为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates)。
Ø 低位的10比特的值(值的范围也是0..0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate), 现在值的范围是0xDC00..0xDFFF。 由于低位代理比高位代理的值要大,所以为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
Ø 最终的UTF-16(4字节)的编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD,第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。上面所说的从U+D800到U+DFFF的码位(代理区),就是为了将一个WORD(2字节)的UTF-16编码与两个WORD的UTF-16编码区分开来。
由于高位代理、低位代理、BMP中的有效字符的码位,三者互不重叠,搜索是简单的: 一个字符编码的一部分不可能与另一个字符编码的不同部分相重叠。这意味着UTF-16是自同步(self-synchronizing):可以通过仅检查一个码元就可以判定给定字符的下一个字符的起始码元。 UTF-8也有类似优点,但许多早期的编码模式就不是这样,必须从头开始分析文本才能确定不同字符的码元的边界。
由于最常有的字符都在基本多文种平面中,许多软件的处理代理对的部分往往得不到充分的测试。这导致了一些长期的bug与潜在安全漏洞,甚至在广为流行得到良好评价的应用软件。
UTF-8
从前述内容可以看出:无论是UTF-16/32还是UCS-2/4,一个字符都需要多个字节来编码,这对那些英语国家来说多浪费带宽啊!(尤其在网速本来就不快的那个年代。。。)由此,UTF-8产生了。在UTF-8编码中,ASCII码中的字符还是ASCII码的值,只需要一个字节表示,其余的字符需要2字节、3字节或4字节来表示。
UTF-8的编码规则:
(1) 对于ASCII码中的符号,使用单字节编码,其编码值与ASCII值相同(详见:U0000.pdf)。其中ASCII值的范围为0~0x7F,所有编码的二进制值中第一位为0(这个正好可以用来区分单字节编码和多字节编码)。
(2) 其它字符用多个字节来编码(假设用N个字节),多字节编码需满足:第一个字节的前N位都为1,第N+1位为0,后面N-1 个字节的前两位都为10,这N个字节中其余位全部用来存储Unicode中的码位值。
| 字节数 | Unicode | UTF-8编码 |
|---|---|---|
| 1 | 000000-00007F | 0xxxxxxx |
| 2 | 000080-0007FF | 110xxxxx 10xxxxxx |
| 3 | 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8 有以下编码规则:
- 如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 – 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
- 如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
- 如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节
3、编码方式总结
(1) 简单地说:Unicode属于字符集,不属于编码,UTF-8、UTF-16等是针对Unicode字符集的编码。
(2) UTF-8、UTF-16、UTF-32、UCS-2、UCS-4对比:
| 对比 | UTF-8 | UTF-16 | UTF-32 | UCS-2 | UCS-4 |
|---|---|---|---|---|---|
| 编码空间 | 0-10FFFF | 0-10FFFF | 0-10FFFF | 0-FFFF | 0-7FFFFFFF |
| 最少编码字节数 | 1 | 2 | 4 | 2 | 4 |
| 最多编码字节数 | 4 | 4 | 4 | 2 | 4 |
| 是否依赖字节序 | 否 | 是 | 是 | 是 | 是 |
4、编码的储存和传输
- windows换装: 从前多种字符集存在时,那些做多语言软件的公司遇上过很大麻烦,他们为了在不同的国家销售同一套软件,就不得不在区域化软件时也加持那个双字节字符集咒语,不仅要处处小心不要搞错,还要把软件中的文字在不同的字符集中转来转去。UNICODE 对于他们来说是一个很好的一揽子解决方案,于是从 Windows NT 开始,MS 趁机把它们的操作系统改了一遍,把所有的核心代码都改成了用 UNICODE 方式工作的版本,从这时开始,WINDOWS 系统终于无需要加装各种本土语言系统,就可以显示全世界上所有文化的字符了。
- UNICODE和DBCS的转换: 但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得 GBK 与UNICODE 在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从UNICODE编码和另一种编码进行转换,这种转换必须通过查表来进行。
- BMP
- UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个plane。每个plane根据第3个字节分为256行 (rows),每行包含256个cells。当然同一行的cells只是最后一个字节不同,其余都相同。
- group 0的plane 0被称作Basic Multilingual Plane, 即BMP。或者说UCS-4中,高两个字节为0的码位被称作BMP。
- UTF: UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从UNICODE到UTF时并不是直接的对应,而是要过一些算法和规则来转换。
- UCS和UTF的区别: UCS规定了怎么用多个字节表示各种文字。怎样传输这些编码,是由UTF(UCS Transformation Format)规范规定的,常见的UTF规范包括UTF-8、UTF-7、UTF-16。
- Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
- 这里就有两个严重的问题
- 第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
- 它们造成的结果是:
- 出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。
- unicode在很长一段时间内无法推广,直到互联网的出现。
- UTF-8
- 互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
- UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
- 下面是Unicode和UTF-8转换的规则
1 Unicode 2 3 UTF-8 4 5 0000 - 007F 6 7 0xxxxxxx 8 9 0080 - 07FF 10 11 110xxxxx 10xxxxxx 12 13 0800 - FFFF 14 15 1110xxxx 10xxxxxx 10xxxxxx
例如”汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 1100 0100 1001,将这个比特流按三字节模板的分段方法分为0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,这就是其UTF8的编码。
三、ANSI编码方案
- 字节: 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为”字节”。
- 每个字节可表示256个不同的状态: 再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为”计算机”。开始时,计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。
- 控制码: 在ASCII码中,第0~31号及第127号(共33个)是控制字符或通讯专用字符,如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(振铃)等;通讯专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等。
- ASCII: 他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做“Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
- 扩展字符集: 后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称“扩展字符集”。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
- 疑问:ANSI编码是什么
-
- ANSI,American National Standard Institite,美国国家标准协会。
- ANSI编码是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。
- ANSI编码 为使计算机支持更多语言,通常使用 0x80~0xFFFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
- 不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。
- 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。ANSI编码表示英文字符时用一个字节,表示中文用两个或四个字节。
-
很长, 终于讲完了我想要说后些名字和细节,但是还有一些名词在上边没有提到,这里再单独解释一下。
大白话:关于代码页(code page)问题。处理多语言的编码方案有两种。
1、将所有语言的每一个符号都统一编码到一个字符集里面。如Unicode方案。
2、将文件编码抽象成一种,根据系统语言环境,再用具体的编码保存。如ANSI方案。但“ANSI编码”确实只存在于Windows系统。ANSI其实是多种编码的集合,具体的编码与解码方案则是根据代码页(code page)来实现的。而code page 则与本地计算机的 语言有关。
那么Windows系统是如何区分ANSI背后的真实编码的呢?
微软用一个叫“Windows code pages”(在命令行下执行chcp命令可以查看当前code page的值)的值来判断系统默认编码,比如:简体中文的code page值为936(它表示GBK编码,win95之前表示GB2312,详见:Microsoft Windows’ Code Page 936),繁体中文的code page值为950(表示Big-5编码)。
我们能否通过修改Windows code pages的值来改变“ANSI编码”呢?
命令提示符下,我们可以通过chcp命令来修改当前终端的active code page,例如:
(1) 执行:chcp 437,code page改为437,当前终端的默认编码就为ASCII编码了(汉字就成乱码了);
(2) 执行:chcp 936,code page改为936,当前终端的默认编码就为GBK编码了(汉字又能正常显示了)。
上面的操作只在当前终端起作用,并不会影响系统默认的“ANSI编码”。(更改命令行默认codepage参看:设置cmd的codepage的方法)。
Windows下code page是根据当前系统区域(locale)来设置的,要想修改系统默认的“ANSI编码”,我们可以通过修改系统区域来实现(“控制面板” =>“时钟、语言和区域”=>“区域和语言”=>“管理”=>“更改系统区域设置…”):
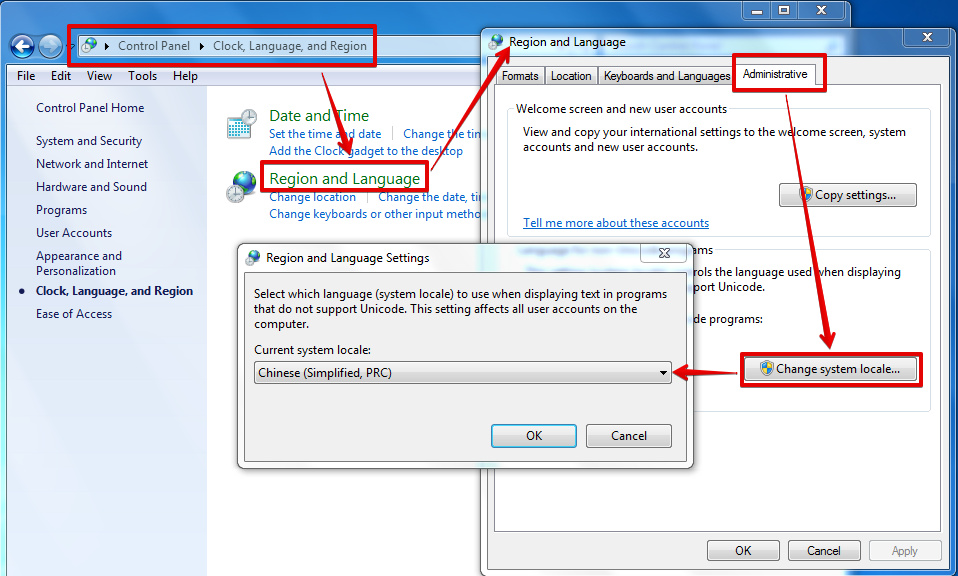
图中的系统locale为简体中文,意味着当前“ANSI编码”实际是GBK编码。当你把它改成Korean(Korea)时,“ANSI编码”实际是EUC-KR编码,“한국어”就能正常显示了;当你把它改成English(US)时,“ANSI编码”实际是ASCII编码,“汉字”和“한국어”都成乱码了。(改了之后需要重启系统的。。。)
说明:locale是国际化与本地化中重要的概念,本文不深入讲解该内容。
- 内码: 字符必须编码后才能被计算机处理。 计算机使用的缺省编码方式就是计算机的内码。上文提到的ASCII, GB2312, big5等都可以叫做内码
- Code page
- UNICODE跟Code Page应该说是显示全世界语言的两个解决方案
- 前一个方案是将全世界的语言的每一个编码都映射成一个编号
- 后一种解决方案则是根据不同的采取重复的编号,根据不同的Code Page来决定一个编号是什么字符。同一个编号在不同的Code Page下代表不同的字符
- 如果你安装的是英文版的XP,Code Page选择的是简体中文,那么你可以正常显示Unicode字符和Code page为中文的编号,无法显示Code Page为繁体和日语的编号。如果要显示后者,则必须切换成相应的Code page,或者将字符编码换成Unicode。
- 字符集和代码页
对于ANSI编码方式,存在不同的字符集(Charset)。同样的字节序列,在不同的字符集下表示的字符不一样。要正确解析一个ANSI字符串,还要选择正确的字符集,否则就可能导致所谓的乱码现象。不同语言版本的操作系统,都有一个默认的字符集。在不指定字符集的情况下,系统会使用此字符集来解析 ANSI 字符串。也就是说,如果我们在简体中文版的Windows下打开了一个由日文操作系统保存的 ANSI 文本文件(仅包含 ANSI 字符串的文本文件),我们看到的将是乱码。但是,如果我们使用Visual Studio之类的带编码选择的文本编辑器打开此文件,并且选择正确的字符集,我们将可以看到它的原貌。注意:简体中文字符集中的繁体字和繁体中文字符集中的繁体字,编码不一定相同(事实证明,似乎是完全不同)。
每个字符集都有一个唯一的编号,称为代码页(Code Page)。简体中文(GB2312)的代码页为936,而系统默认字符集的代码页为0,它表示根据系统的语言设置来选择一个合适的字符集。