一、数据链路层含义
数据链路层是OSI参考模型中的第二层,介乎于物理层和网络层之间。数据链路层在物理层提供的服务的基础上向网络层提供服务,其最基本的服务是将源自网络层来的数据可靠地传输到相邻节点的目标机网络层。
封装成帧,将数据链路层的帧,直接交给物理层就行。物理层会自动添加首尾(物理层头部一定会加的,尾部不确定),并编码。
二、数据链路层协议分类
1.面向字符的链路层协议
ISO的IS1745,基本型传输控制规程及其扩充部分(BM和XBM)
IBM的二进制同步通信规程(BSC)
DEC的数字数据通信报文协议(DDCMP)
PPP(同步传输模式面向位,异步传输模式面向字符)
等等
2.面向比特的链路层协议
HDLC的产生背景
在计算机通信的早期人们就已发现,对于经常产生误码的实际链路,只要加上合适的控制规程,就可以使通信变为比较可靠的。那时 ARPANET 和 IBM 公司分别使用了各自的控制规程,它们分别是:IMP-IMP 协议和 BSC 规程(也可称为 BISYNC,即 BInary SYNchronous Communication 的缩写)。这些规程都是数据链路层的协议。
上述的两种协议都是面向字符的。所谓面向字符就是说在链路上所传送的数据必须是由规定字符集(例如 ASCII 码)中的字符所组成。不仅如此,在链路上传送的控制信息也必须由同一个字符集中的若干指定的控制字符构成。这种面向字符的链路控制规程在计算机网络的发展过程中曾起了重要的作用。
但随着计算机通信的发展,这种面向字符的链路控制规程就逐渐暴露出其弱点。就以著名的 BSC 规程来说,其主要限制是:
(l)通信线路的利用率低,因为它采用的是停止等待协议,收发双方交替地工作。
(2)所有通信的设备必须使用同样字符代码,而不同版本的 BSC 规程要求使用不同的代码。
(3)只对数据部分进行差错控制,若控制部分出错就无法控制,因而可靠性较差。
(4)不易扩展。每增加一种功能就需要设定一个新的控制字符。
此外,它还存在其他一些缺点。由此可见,需要设计出一种新的链路控制规程来代替旧的面向字符的链路规程。
1974年,IBM 公司推出了著名的体系结构 SNA。在 SNA 的数据链路层规程采用了面向比特的规程 SDLC( Synchronous Data Link Control)。后来 IBM 将此规程提交美国国家标准协会 ANSI 和国际标准化组织 ISO,建议能成为国家和国际标准。ANSI 把 SDLC 修改为 ADCCP(Advanced Data Communication Control Procedure)作为美国国家标准,而 ISO 把 SDLC 修改后称为 HDLC(High-level Data Link Control),译为高级数据链路控制,作为国际标准 ISO 3309。我国的相应国家标准是 GB 7496。 CCITT 则将 HDLC 再修改后称为链路接入规程 LAP(Link AccessProcedure),并作为 X.25 建议书的一部分(即有关数据链路层协议的部分)。不久,HDLC 的新版本又把 LAP 修改为 LAPB,“B” 表示平衡型(Balanced),所以 LAPB 叫做链路接入规程(平衡型)。这样X.25的数据链路层就叫做LAPB了。
上述这几个面向比特的链路规程均大同小异。ADCCP 与 HDLC 没有多少区别。SDLC 虽然最早提出,但它实际上是 HDLC 的一个子集。
LLC是为了使数据链路层更好地适应各种局域网标准,由802委员会做出决定将数据链路层拆分为2个子层,即LLC Logical Link control逻辑链路控制子层和MAC Mdedium Access Control媒体接入控制子层。将于接入到传输媒体有关的内容都放在MAC子层,而LLC子层则与传输媒体无关。 而到了上个世纪90年代后,以太网中的DIX Ethernet V2已经成为了事实上的业界标准,并且也不属于802委员会所规定的几种以太网标准之一。所以等于说标准落后于实际生产了,这个时候LLC已经失去了作用。 从那往后,大多数的网卡上都不装LLC协议,而只有MAC协议了。 所以我们现在一般在座比较的时候,直接来比较HDLC和MAC两个层控制协议以及他们所控制的的数据结构就可以了。LCC基本上已经消失了。
三、数据链路层功能
1、帧同步
大白话就是,从数据链路层中,准确识别并提取 数据链路层 的帧信息。(和之前提到的,群同步、异步传输等于帧同步 ,不是特别对,反正大致意思明白就行,人家的百科 群同步 等于 帧同步 等于 异步传输,本来就写得不妥)
用到的方法有:
(1)字节计数法:这是一种以一个特殊字符表示一帧的起始并以一个专门字段来标明帧内字节数的帧同步方法。接收方可以通过对该特殊字符的识别从比特流中区分出帧的起始并从专门字段中获知该帧中随后跟随的数据字节数,从而可确定出帧的终止位置。
(2)使用字符填充的首尾定界符法:该法用一些特定的字符来定界一帧的起始与终止,为了不使数据信息位中出现的与特定字符相同的字符被误判为帧的首尾定界符,可以在这种数据字符前填充一个转义控制字符(DLE)以示区别,从而达到数据的透明性。但这种方法使用起来比较麻烦,而且所用的特定字符过份依赖于所采用的字符编码集,兼容性比较差。
(3)使用比特填充的首尾标志法:该法以一组特定的比特模式(如01111110)来标志一帧的起始与终止。本章稍后要详细介绍的HDLC规程即采用该法。为了不使信息位中出现的与特定比特模式相似的比特串被误判为帧的首尾标志,可以采用比特填充的方法。比如,采用特定模式01111110,则对信息位中的任何连续出现的五个“1”,发送方自动在其后插入一个“0”,而接收则做该过程的逆操作,即每接收到连续五个“1”,则自动删去其后所跟的“0”,以此恢复原始信息,实现数据传输的透明性。比特填充很容易由硬件来实现,性能优于字符填充方法。
(4)违法编码法:该法在物理层采用特定的比特编码方法时采用。例如,一种被称作曼彻斯特编码的方法,是将数据比特“1”编码成“高-低”电平对,而将数据比特“0”编码成“低-高”电平对。而“高-高”电平对和“低-低”电平对在数据比特中是违法的。可以借用这些违法编码序列来定界帧的起始与终止。局域网IEEE 802标准中就采用了这种方法。违法编码法不需要任何填充技术,便能实现数据的透明性,但它只适用于采用冗余编码的特殊编码环境。由于字节计数法中COUNT字段的脆弱性以及字符填充法实现上的复杂性和不兼容性,较普遍使用的帧同步法是比特填充和违法编码法。
=========================================================
以太网 V2 没有帧长度 , 如何识别 物理层 如何识别?
The Ethernet II frame format does not contain a length field, and I’d like to understand how the end of a frame can be detected without it.
来自:https://stackoverflow.com/questions/3416990/how-to-determine-the-length-of-an-ethernet-ii-frame
The length field inside the frame is not needed for layer1.Layer1 uses other means to detect the end of a frame which vary depending on the type of physical layer.
- with 10Base-T a frame is followed by a TP_IDL waveform. The lack of further Manchester coded data bits can be detected.
- with 100Base-T a frame is ended with an End of Stream Delimiter bit pattern that may not occur in payload data (because of its 4B/5B encoding).
A rough description you can find e.g. here:http://ww1.microchip.com/downloads/en/AppNotes/01120a.pdf “Ethernet Theory of Operation”
网友答案:
LLC只出现在802.3以太网的格式中,802.3的MAC层没有字段指明上层协议字段,但是指明了数据包长度,所以上层协议需要LLC指明。
在ETHERNET_II帧中,把802.3的长度字段改为了type。由Type字段区分上层协议,这时候就没有必要实现LLC子层,仅包含一个MAC子层。
只是现在厂商都用ETHERNET_II。实际效果和802.3+LLC是一样的。
如何区分两种帧
根据源地址段后的前两个字节的类型不同。
如果值大于1500(0x05DC),说明是以太网类型字段,EthernetII帧格式。值小于等于1500,说明是长度字段,IEEE802.3帧格式。因为类型字段值最小的是0x0600。而长度最大为1500。
那么问题来了,802.3是有长度标志的,LLC表示上层协议,Ethernet_II没有长度标志,至少现在都不用了,那么判定一个数据包是不是发送完了呢。
解答:
因为以太网帧使用4B/5B编码,出现5bit固定类型的二进制,表示此数据包结束,正常传输中是不会出现这5bit的特定序列,如果有也是经过反码或者补码什么的替换掉了,学过计算机组成原理的同学就知道了。所以不需要协议里面有长度字段。当然具体还有很多细节,喜欢深究的同学可以自行脑补。【100M以太网的情况下看来是】
=========================================================
2、差错控制
为了防止在传输过程中发生错误,数据发送方的网卡会计算一个校验码,覆盖整个以太网帧,并放在以太网帧尾部,发送出去,接收网卡需要对其进行校验,来决定是否接收。而如果不校验,一个错误的帧可能要到TCP、UDP才能被发现出来,这样的话会浪费很多CPU资源。CPU会说:屁大点的事都搞不定,还要劳烦朕,可以去自宫了。而如果网卡来进行校验,错了就默默地丢弃,不惊动高层,高层肯定偷偷乐开了花。
大白话就是:数据链路层帧的FCS,就是用来检查帧有没有传错的,一般FCS里面用的是CRC检错法。因为以太网帧和PPP帧都没有重传机制,所以的重传控制只能由tcp/udp 的传输控制里面去了。而下面的方法,都是基于确认帧的。
FCS检查完后,正确的接收,错误的丢弃。这叫做无差错接收。
后面的差错帧重传,这样才算可靠传输【数据帧 的 无差错,无丢失】。
数据链路层的FCS检查是针对整个帧进行检查的。
IP帧的校验码只覆盖IP头,【16位首部校验和,可以查看ip报头】保证关键信息如目的IP在传输过程没有差错,可以到达目的地,至于里面封装内容则由目的地主机负责校验,可以减少路由器的处理时间,提高转发效率。所以IP层不能发现IP包的损坏。
所以以太网的差错重传,只能靠传输层的tcp/udp 进行控制了。因为数据链路层 和 ip层 差错重传都 不管。
关于以太网的CSMA/CD ,这个是解决 共享传输介质下 如何独占 收发信息。以太网在全双工下,也会出现 传输的帧出 差错,但是因为概率小,所以就没有用确认帧。
1. 差错的产生原因

当数据信号从发送端出发到物理线路时,由于物理线路存在噪声,因此数据信号经过物理线路到达接收端时,接收信号必然是数据信号和噪声信号的叠加,这就是差错的产生原因。
2. 差错的控制方法
2.1 误码率的定义
误码率(Pe):指二进制比特在数据传输系统中被传错的概率
N为传输的二进制比特总数,Ne为传错的比特数
Pe = Ne / N
2.2 差错控制
差错控制:检测和纠正 比特流传输错误的方法,目的是为了减少物理线路的传输错误
差错控制的两种策略:
纠错码:每个传输的分组带上足够的冗余信息,接收端能发现并自动纠正传输差错
检测码:分组仅包含足以使接收端发现差错的冗余信息,接收端能发现出错,但不能确定哪一比特是错的,并且自己不能纠正传输差错
纠错码实现困难,而检错码方法虽然可以通过重传机制达到纠错目的,但是实现简单,所以广泛采用检错码策略。
2.3 检错码:循环冗余编码(CRC)
检错码又分为两种,奇偶校检码和循环冗余编码,而循环冗余编码是广泛使用的检错码方法,它检错能力强,实现容易。
循环冗余编码(CRC)的工作原理:
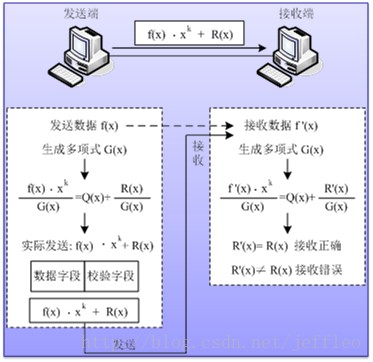
- 首先收发双方约定一个**生成多项式**G(x)
- 发送端把数据看成一个多项式f(x)
- 把f(x) 乘以生成多项式的最高次幂,f(x) * xk,目的是为了左移k位,用来放余数
- f(x) * xk/G(x),求得余数
- 将f(x) * xk+R(x)作为整体,发送到接收端
- 接收端用接收到的数据f′(x)采用相同的算法,去除约定好的G(x),得到余数R′(x)。如果R′(x)等于 R(x),表示发送没有出错;否则,说明传输出错,例如:1100111001 / 11001 = 0。
举例:发送数据110011
1. 约定G(x)=x4+x3+1,则对应G(x)的二进制代码为: 11001(N = 5,k = 4)
2. 发送数据比特序列为110011,其对应的多项式为f(x)=x5+x4+x1+1
3. G(x)的最高次幂为4,f(x) * x4 = 1100110000
4. f(x) * xk/G(x),余数为:R(x) = 1001
5. 将f(x) * xk+R(x)作为整体,发送到接收端:1100111001
6. 接收端解码:1100111001 / 11001 = 0,说明传输成功
========================================================
用以使发送方确定接收方是否正确收到了由它发送的数据信息的方法称为反馈差错控制。通常采用反馈检测和自动重发请求(ARQ)两种基本方法实现。
反馈检测法
反馈检测法也称回送校验或“回声”法,主要用于面向字符的异步传输中,如终端与远程计算机间的通信,这是一种无须使用任何特殊代码的错误检测法。双方进行数据传输时,接收方将接收到的数据(可以是一个字符,也可以是一帧)重新发回发送方,由发送方检查是否与原始数据完全相符。若不相符,则发送方发送一个控制字符(如DEL)通知接收方删去出错的数据,并重新发送该数据;若相符,则发送下一个数据。反馈检测法原理简单、实现容易,也有较高的可靠性,但是,每个数据均被传输两次,信道利用率很低。一般,在面向字符的异步传输中,信道效率并不是主要的,所以这种差错控制方法仍被广泛使用。
自动重发法
(ARQ法):实用的差错控制方法,应该既要传输可靠性高,又要信道利用率高。为此让发送方将要发送的数据帧附加一定的冗余检错码一并发送,接收方则根据检错码对数据帧进行错误检测,若发现错误,就返回请求重发的答,发送方收到请求重发的应答后,便重新传送该数据帧。这种差错控制方法就称为自动请求法(Automatic Repeat reQuest),简称ARQ法。ARQ法仅返回很少的控制信息,便可有效地确认所发数据帧是否被正确接收。ARQ法有若干种实现方案,如空闲重发请求(Idle RQ)和连续重请求(Continuous RQ)是其中最基本的两种方案。
空闲重发请求
(Idle RQ):空闲重发请求方案也称停等(stop-and -wait)法,该方案规定发送方每发送一帧后就要停下等待接收方的确认返回,仅当接收方确认正确接收后再继续发送下一帧。空闲重发请求方案的实现过程如下: 发送方每次仅将当前信息帧作为待确认帧保留在缓冲存储器中。当发送方开始发送信息帧时,随即启动计时器。 当接收方检测到一个含有差错的信息帧时,便舍弃该帧。当接收方收到无差错的信息帧后,即向发送方返回一个确认帧。 若发送方在规定时间内未能收到确认帧(即计时器超时),则应重发存于缓冲器中待确认信息帧。若发送方在规定时间内收到确认帧,即将计时器清零,继而开始下一帧的发送。从以上过程可以看出,空闲RQ方案的收、发双方仅须设置一个帧的缓冲存储空间,便可有效地实现数据重发并保证收接收方接收数据不会重份。空闲RQ方案最主要的优点就是所需的缓冲存储空间最小,因此在链路端使用简单终端的环境中被广泛采用。
连续重发请求
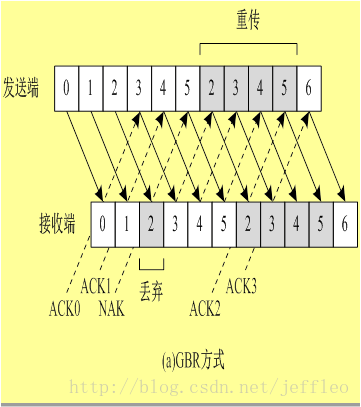
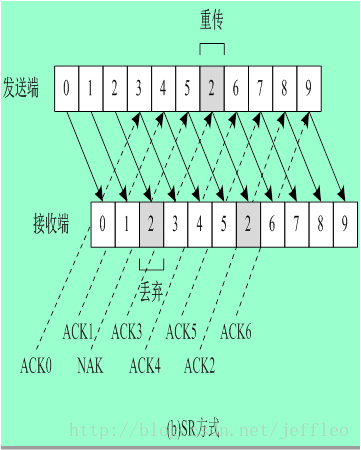
(Continuous RQ):连续重发请求方案是指发送方可以连续发送一系列信息帧,即不用等前一帧被确认便可发送下一帧。这就需要一个较大的缓冲存储空间(称作重发表),用以存放若干待确认的信息帧。每当发送站收到对某信息帧的确认帧后,便从重发表中将该信息帧删除。所以,连续RQ方案的链路传输效率大大提高,但相应地需要更大的缓冲存储空间。连续RQ方案的实现过程如下:发送方连续发送信息帧而不必等待确认帧的返回。发送方在重发表中保存所发送的每个帧的拷贝。重发表按先进先出(FIFO)队列规则操作。接收方对每一个正确收到的信息帧返回一个确认帧。每一个确认帧包含一个唯一的序号,随相应的确认帧返回。接收方保存一个接收次序表,它包含最后正确收到的信息帧的序号。当发送方收到相应信息帧的确认帧后,从重发表中删除该信息帧。当发送方检测出失序的确认帧(即第n号信息帧和第n+2号信息帧的确认帧已返回,而n+1号的确认帧未返回)后,便重发未被确认的信息帧。实际操作过程中,两节点间采用双工方式将确认帧插在双方的发送信息帧中来传送的。上面的连续RQ过程是假定在不发生传输差错的情况下描述的。如果差错出现,如何进一步处理可以有两种策略,即Go-back-N和选择重发。 Go-back-N是当接收方检测出失序的信息帧后,要求发送方重发最后一个正确接收的信息帧之后的所有未被确认的帧,或者当发送方发送了n帧后,若发现该n帧的前一帧在计时器超时后仍未返回其确认信息,则该帧被判定为出错或丢失。对接收方来说,因为这一帧出错,就不能以正确的序号向它的高层递交数据,对其后发送来的n帧也可能都不能接收而丢弃,因此,发送方发现这种情况,就不得不重新发送该出错帧及其后的n帧,这就是Go-back-N(退回N)法名称的由来。Co-back-N法操作过程如图3-2所示。图中假定发送完8号帧后,发现2号帧的确认返回在计时器超时后还未收到,则发送方只能退回从2号帧开始重发。Go-back-N可能将已正确传送到目的方的帧再传一遍,这显然是一种浪费。另一种更好的策略是当接收方发现某帧出错后,其后继续送来的正确的帧虽然不能立即递交给接收方的高层,但接收方仍可收下来,存放在一个缓冲区中,同时要求发送方重新传送出错的那一帧,一旦收到重新传来的帧后,就可与原已存于缓冲区中的其余帧一并按正确的顺序递交高层。这种方法称为选择重发(Selective repeat),其工作过程如图3-3所示。图中2号帧的否认返回信息NAK2要求发送方选择重发2号帧。显然,选择重发减少了浪费但要求接收方有足够大的缓冲区容量。
=========================================================
3、流量控制
流量控制涉及链路上字符或帧的传输速率的控制,以使接收方在接收前有足够的缓冲存储空间来接受每一个字符或帧。例如,在面向字符的终端--计算机链路中,若远程计算机为许多台终端服务,它就有可能因不能在高峰时按预定速率传输全部字符而暂时过载。同样,在面向帧的自动重发请求系统中,当待确认帧数量增加时,有可能超出缓冲器存储容量,也造成过载。
=======================================================
以太网的流量控制:
以太网不需要确认帧(碰撞检测:CSMA/CD) 无线网有确认帧(碰撞检测:CSMA/CA)。
有确认帧的,可以使用窗口滑动协议进行流量控制。
当通过交换机一个端口的流量过大,超过了它的处理能力时,就会发生端口阻塞。
网络拥塞一般是由于线速不匹配(如100M向10M端口发送数据)和突发的集中传输而产生的,它可能导致这几种情况:延时增加、丢包、重传增加,网络资源不能有效利用。
流量控制的作用是防止在出现阻塞的情况下丢帧。
在半双工方式下,流量控制是通过反压(backpressure)技术实现,模拟产生碰撞,使得信息源降低发送速度。
有两种方法可以达到这一目的:交换机可以强行制造一次与服务器的冲突,使得服务器退避;或者,交换机通过插入一次“载波检测”使得服务器的端口保持繁忙,这样就能使服务器感觉到交换机要发送数据一样。利用这两种方法,服务器都会在一段时间内暂停发送,从而允许交换机去处理积聚在它的缓冲区中的数据。
在全双工方式下,IEEE802.3 x标准定义了在全双工环境中实现流量控制的方法。交换机产生一个”PAUSE”MAC控制帧,”PAUSE”MAC控制帧使用一个保留的组播地址:01-80-C2-00-00-01,将它发送给正在发送的站,发送站接收到该帧后,就会暂停或停止发送。PAUSE帧利用了一个保留的组播地址,它不会被网桥和交换机所转发,这样,PAUSE帧不会产生附加信息量。
在全双工环境中,服务器和交换机之间的连接是一个无碰撞的发送和接收通道。由于没有碰撞检测,且不允许交换机通过产生一次冲突而使得服务器停止发送
在实际的网络中,尤其是一般局域网,产生网络拥塞的情况极少,所以有的厂家的交换机并不支持流量控制。高性能的交换机应支持半双工方式下的反向压力和全双工的IEEE802.3x流控。有的交换机的流量控制将阻塞整个LAN的输入,降低整个LAN的性能;高性能的交换机采用的策略是仅仅阻塞向交换机拥塞端口输入帧的端口,保证其他端口用户的正常工作。
##################################################
pause帧格式:
 至于以太网的CSMA/CD ,应该是 数据帧发送,检测数据帧小于64字节,说明发生了链路碰撞。数据帧的发送和接收应该是用协议发送的,接收数据帧到本地,用设计好的CSMA/CD函数判断数据帧是不是小于64字节,然后决策是不是 数据碰撞了。
至于以太网的CSMA/CD ,应该是 数据帧发送,检测数据帧小于64字节,说明发生了链路碰撞。数据帧的发送和接收应该是用协议发送的,接收数据帧到本地,用设计好的CSMA/CD函数判断数据帧是不是小于64字节,然后决策是不是 数据碰撞了。
https://en.wikipedia.org/wiki/Ethernet_flow_control
https://www.tuicool.com/articles/Bzu2uuf
========================================================
4、链路控制
链路管理功能主要用于面向连接的服务。当链路两端的节点要进行通信前,必须首先确认对方已处于就绪状态,并交换一些必要的信息以对帧序号初始化,然后才能建立连接,在传输过程中则要能维持该连接。如果出现差错,需要重新初始化,重新自动建立连接。传输完毕后则要释放连接。数据连路层连接的建立维持和释放就称作链路管理。在多个站点共享同一物理信道的情况下(例如在LAN中)如何在要求通信的站点间分配和管理信道也属于数据链路层管理的范畴。
=========================================================
在以太网中,LLC只出现在802.3以太网的格式中,802.3的MAC层没有字段指明上层协议字段,但是指明了数据包长度,所以上层协议需要LLC指明。在ETHERNET_II帧中,把802.3的长度字段改为了type。由Type字段区分上层协议,这时候就没有必要实现LLC子层,仅包含一个MAC子层。
以太网的上层协议可以有好几种,(1)无连接,这种传输效果难以保证。(2)面向连接,该方式提供了四种服务:连接的建立、确认和数据到达响应、差错恢复(请求重发接收的错误数据)以及滑动窗口(用来提高数据传输速率)。(3)无连接应答响应服务。
网络层的IP协议,就是面向无连接的。
经过探讨,因为以太网是面向无连接的,而PPP是面向连接的,所以以太网不需要向PPP那样,建立连接,断开连接,这些数据链路层控制命令操作。
=========================================================
5、透明传输
因为数据链路层的帧是有帧定界的,如果该帧上面传递的数据,意外包含了帧定界的,采取以下措施:
当信息字段中出现和标志字段一样的比特组合时,如(0x7E),就必须采取一些措施使这种形式上和标志字段一言的比特组合不出现在信息字段中。
如:
当PPP使用异步传输时,它把转移符定义为0x7D,并使用字节填充。
当PPP使用同步传输时,使用零比特填充。
四、滑动窗口协议-基于确认帧的流量控制协议
全双工下使用802.3x定义的pause帧来通知对端。
前面提到了用检错码来检测帧传输中是否发生了错误,如果发生了错误,就需要通过滑动窗口协议来解决。
滑动窗口协议分为两种类型: 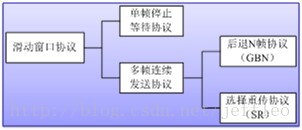
1. 单帧停止等待协议
发送端每次发送1帧之后,需要等待接收端返回确认帧,如果接受到ACK,表示传输成功,发送下一帧;如果接收到NAK,表示传输错误,重新发送此帧

2. 多帧连续发送协议
多帧连续发送有两种类型,后退N帧(GBN)拉回重发方式和选择重发(SR)方式
1. 后退N帧(GBN)拉回重发方式
只要有一个帧发送失败,则当前发送的全部帧都重新发送,这样导致的问题就是会发送许多重复帧,流量控制不好
2. 选择重发(SR)方式
选择重发和拉回重发的区别在于,当前发送的帧中出现某个帧传输错误后,在下一次发送时只是重新发送该错误的帧
3. 滑动窗口机制
在GBN和SR中,发送端可以连续发送多个数据帧,从流量控制的角度出发,发送端连续发送数据帧的数量必然会收到限制:
1. 接收端的缓冲区可以用于接受新的帧的容量
2. 接收端处理数据帧的速度
3. 接收端需要等待重传的帧的数量
引入滑动窗口的目的:对可以连续发出的最多帧数(已发出但未确认的帧)作限制 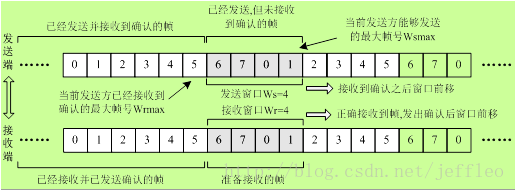
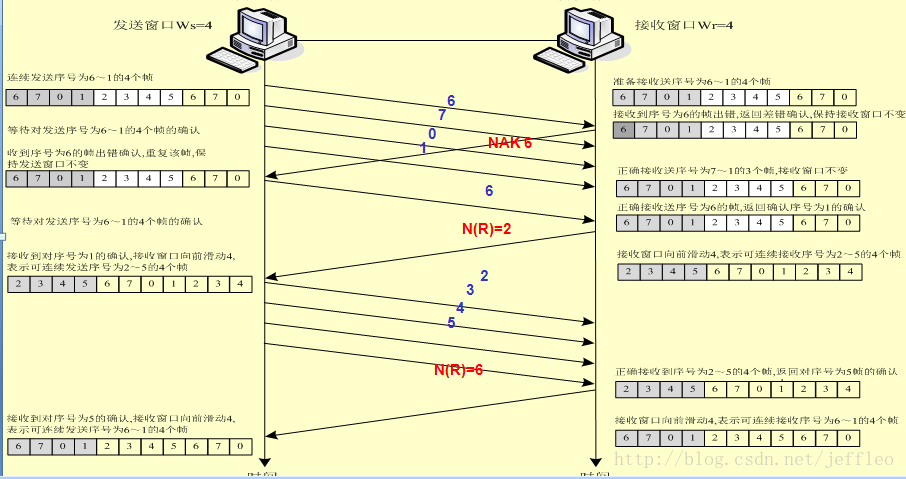
发送窗口(Ws):表示在收到对方确认的信息之前,以连续发出的最多数据帧数
接受窗口(Wr):可以连续接收的最多数据帧数(只有序号在窗口内的帧才可以接收,否则丢弃)
滑动窗口机制实例
参考:
ppp协议:
https://blog.csdn.net/lnboxue/article/details/79486069
https://blog.csdn.net/cainv89/article/details/50612718
https://blog.csdn.net/windeal3203/article/details/51066331
https://blog.csdn.net/csucxcc/article/details/1684416
================================================
以太网帧格式
https://blog.csdn.net/a1414345/article/details/72781130
http://blog.sina.com.cn/s/blog_87bbe37e01013zim.html
https://blog.csdn.net/jeffleo/article/details/53932693
https://zhuanlan.zhihu.com/p/21318925
https://www.jianshu.com/p/ffb4423be724
http://blog.sina.com.cn/s/blog_5f38b78d0100c62d.html 专题