UTF-16是UCS-2的扩展。JavaScript引擎内部是自由的使用UCS-2或者UTF-16。大多数引擎使用的是UTF-16,无论它们使用什么方式实现,它只是一个具体的实现,这不将影响到语言的特性。 —–到时候,再探究
JavaScript中的字符串是以UTF-16为代码单元。通常我们使用的字符范围都在Unicode值0x10000以内,他们对应的UTF-16就是它们自身。但Unicode中也存在这个范围之外的字符,这时候就需要两个UTF-16字符来描述。这些字符在统计时会被作为两个字符。
比如下面这个字符,虽然只有一个字,但却会统计出两个字符。
<script>
alert("?".length); //2
</script>
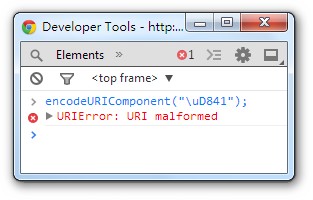
在正则表达式中,它也被作为两个字符来处理
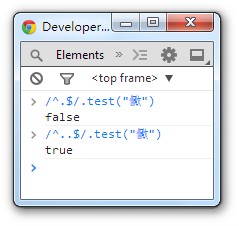
使用charCodeAt的时候也会把它作为两个字符来处理。这些把它当做两个字符处理的情况会分别处理它的“高位替代符”和“低位替代符”。
这种四字节的UTF-16对应的Unicode值可以这样计算。这些替代符都有固定的格式,这些格式也决定了他们在Unicode中的区位。比如高位替代符的二进制表示就是 “110110xx xxxxxxxx”,低位替代符的二进制表示就是“110111yy yyyyyyyy”。把它们固定的头部去掉,取出内容部分再把这两个替代符的内容部分的二进制连接起来就可以得到“xxxx xxxxxxyy yyyyyyyy”,这是一个20位的二进制。实际上目前Unicode的最大码位是“0x10FFFF”,写成二进制就是“10000 11111111 11111111”,这是21位的。也就是说两个UTF-16的替代符中包含的数据要组成任意一个Unicode字符还差了一点。从上面二进制可以观察出,如果x和y全是1的话,还需要加上一个“0x10000”(写成二进制是“1 00000000 00000000”)才能让它达到Unicode最大码位。其实在把Unicode值转换到UTF-16时候就是减去这个值后转换过来的。因为双字节的UTF-16已经可以表示所有小于“0x10000”码位的字符了,四字节的UTF-16只要负责好大于它的部分字符就行。
另外,在发这篇文章的时候又遇到一些问题,MySQL的 utf8 general_ci 貌似不支持四字节字符。嘛,这个问题以后再研究啦。
来自:https://www.web-tinker.com/article/20468.html